input var
Prompt template used to extract the name of the destination language from all input variables.
Get the name of the destination language from following variables:
{all_input_variables}
This workflow streamlines the translation of HUGO markdown files into target languages while preserving file structure and formatting. Leveraging AI language models, it ensures accurate translations of content, maintains TOML front matter integrity, and applies translation best practices for static site generators.
Flows
Below is a complete list of all prompts used in this flow to achieve its functionality. Prompts are the instructions given to the AI model to generate responses or perform actions. They guide the AI in understanding user intent and generating relevant outputs.
Prompt template used to extract the name of the destination language from all input variables.
Get the name of the destination language from following variables:
{all_input_variables}
Prompt template for the translation of HUGO markdown files, including restrictions and example formatting.
You are professional translator translating HUGO markdown file to destination language, which is defined in input variables:
{all_input_variables}
-- TRANSLATION RESTRICTIONS --
{context}
-- END RESTRICTIONS --
Input file is HUGO file with Front matter section formatted with toml language (translated file should start with toml, than contains variables in toml format ), than file continue with markdown text
Keep the same formatting and structure as original input file, make sure all control characters are used in the same form as in original input.
Don't translate text, which are part of HTML tags or field names in the front matter section - translate just field values.
In the translation properly handle quotes
--
--EXAMPLE of file structure START:
title = "any title"
any other markdown text ...
-- EXAMPLE END
--
RETURN JUST TRANSLATED FILE, NOTHING ELSE!
INPUT FILE TO TRANSLATE:
{input}
This is a final line added for robust parsing.
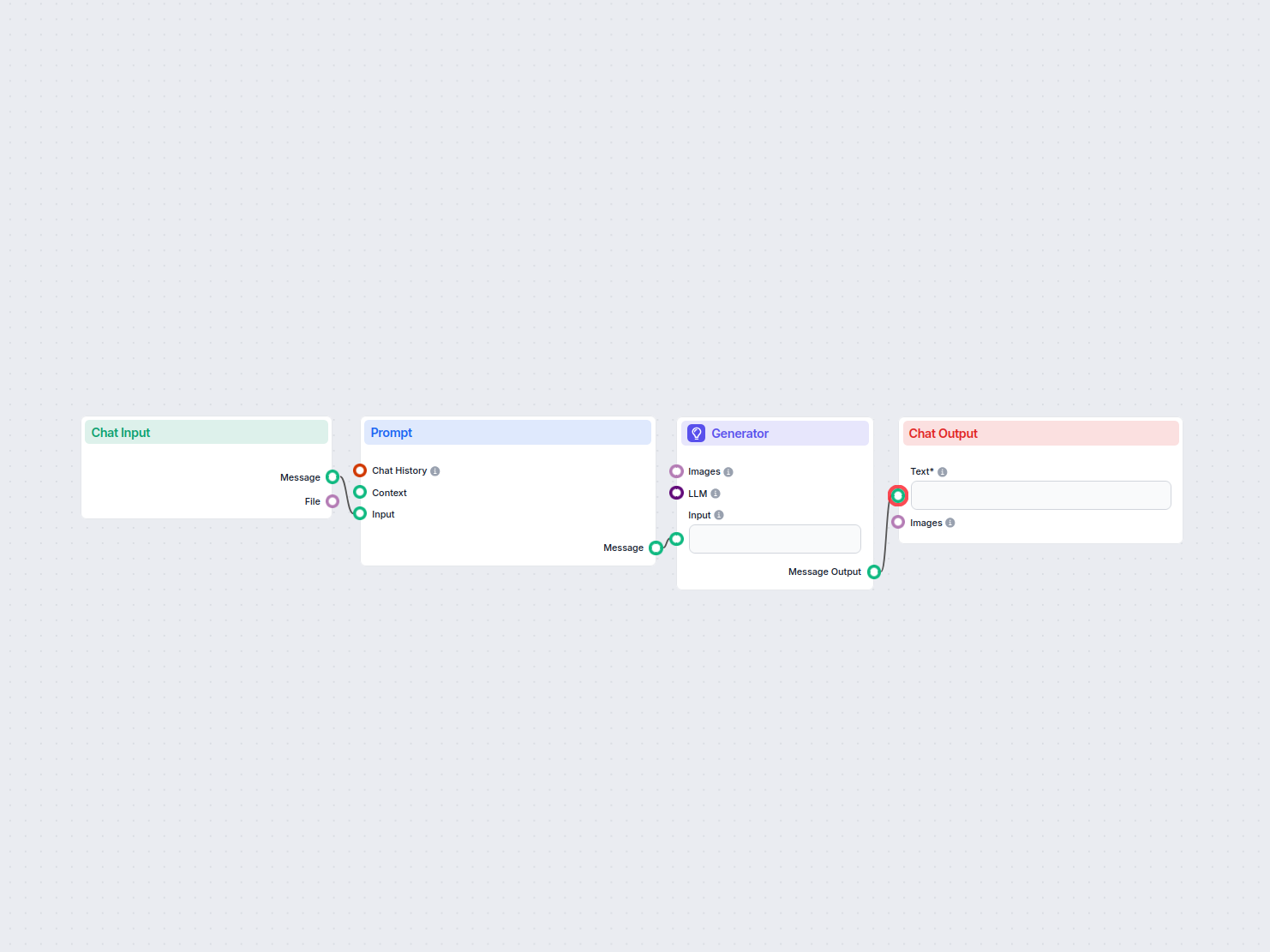
Below is a complete list of all components used in this flow to achieve its functionality. Components are the building blocks of every AI Flow. They allow you to create complex interactions and automate tasks by connecting various functionalities. Each component serves a specific purpose, such as handling user input, processing data, or integrating with external services.
The Chat Input component in FlowHunt initiates user interactions by capturing messages from the Playground. It serves as the starting point for flows, enabling the workflow to process both text and file-based inputs.
Learn how FlowHunt's Prompt component lets you define your AI bot’s role and behavior, ensuring relevant, personalized responses. Customize prompts and templates for effective, context-aware chatbot flows.
FlowHunt supports dozens of text generation models, including models by OpenAI. Here's how to use ChatGPT in your AI tools and chatbots.
Explore the Generator component in FlowHunt—powerful AI-driven text generation using your chosen LLM model. Effortlessly create dynamic chatbot responses by combining prompts, optional system instructions, and even images as input, making it a core tool for building intelligent, conversational workflows.
FlowHunt's Document Retriever enhances AI accuracy by connecting generative models to your own up-to-date documents and URLs, ensuring reliable and relevant answers using Retrieval-Augmented Generation (RAG).
Discover the Chat Output component in FlowHunt—finalize chatbot responses with flexible, multi-part outputs. Essential for seamless flow completion and creating advanced, interactive AI chatbots.
The Note component in FlowHunt lets you add comments and documentation directly into your workflow. Use it to clarify, annotate, or provide instructions within your flow, making complex automations easier to understand and maintain.
Flow description
This workflow is designed to automate the translation of markdown files used in HUGO projects, with special attention to preserving the file structure and formatting. The flow ensures that only the relevant text content is translated, while technical elements like front matter, markdown structure, and control characters remain intact. This is particularly useful for teams managing multi-language static sites built with HUGO, and looking to scale content localization while maintaining high quality and consistency.
The workflow consists of several interconnected components. Here’s a step-by-step outline:
| Step | Component | Function |
|---|---|---|
| 1 | Chat Input | Accepts the markdown file to be translated and any required variables (e.g., target language). |
| 2 | Prompt Template (input var) | Extracts the destination language name from input variables for downstream use. |
| 3 | LLM OpenAI (nano) | Uses a lightweight GPT-4 model to process prompts. |
| 4 | Generator (get language name) | Generates the destination language name from the provided variables. |
| 5 | Document Retriever (GetBestTranslation) | Searches for existing best translations or context from internal/document sources. |
| 6 | Prompt Template (Prompt) | Crafts a detailed prompt instructing the LLM on how to translate, with restrictions and examples. |
| 7 | LLM OpenAI (full) | Uses a full-feature GPT-4 model (with large context) to perform the translation. |
| 8 | Generator | Executes the translation using the above prompt and model. |
| 9 | Chat Output | Displays the translated markdown file in the output interface. |
+ + + and markdown/HTML elements are preserved as required by HUGO and TOML specifications.In summary, this workflow provides an end-to-end, reliable, and scalable solution for translating HUGO markdown files, making it highly valuable for organizations managing multilingual static sites or documentation projects.
We help companies like yours to develop smart chatbots, MCP Servers, AI tools or other types of AI automation to replace human in repetitive tasks in your organization.
Translate web content between languages while preserving HTML structure, using AI and UrlsLab plugin. Email addresses and URLs remain unchanged, ensuring accura...
Automate the creation of professional Google Slide presentations from any uploaded document using AI. This workflow extracts document content, generates structu...
Generate comprehensive, SEO-optimized product review articles for software tools, including detailed features, pricing, user reviews, resources, and more, with ...