
التدفقات
التدفقات هي العقل المدبر لكل شيء في FlowHunt. تعلم كيف تبنيها باستخدام منشئ بصري بدون كود، من وضع أول مكون إلى دمج الموقع الإلكتروني، ونشر روبوتات الدردشة، والا...
2 دقيقة قراءة
AI
No-Code
+4

مجموعة أدوات CLI مفتوحة المصدر الجديدة من FlowHunt تتيح تقييم التدفقات بشكل شامل مع LLM كقاضٍ، مع تقارير مفصلة وتقييم جودة مؤتمت لتدفقات الذكاء الاصطناعي.
يسعدنا أن نعلن عن إطلاق مجموعة أدوات FlowHunt CLI – أداتنا الجديدة مفتوحة المصدر لسطر الأوامر المصممة لإحداث ثورة في طريقة تقييم واختبار المطورين لتدفقات الذكاء الاصطناعي. توفر هذه المجموعة القوية إمكانات تقييم تدفق على مستوى المؤسسات لمجتمع المصدر المفتوح، مع تقارير متقدمة وتنفيذنا المبتكر لـ “LLM كقاضٍ”.
تمثل مجموعة أدوات FlowHunt CLI خطوة كبيرة إلى الأمام في اختبار وتقييم سير عمل الذكاء الاصطناعي. وهي متاحة الآن على GitHub، وتوفر للمطورين أدوات شاملة من أجل:
تجسد المجموعة التزامنا بالشفافية وتطوير المجتمع، مما يجعل تقنيات تقييم الذكاء الاصطناعي المتقدمة في متناول المطورين حول العالم.
واحدة من أكثر الميزات ابتكاراً في مجموعة أدوات CLI الخاصة بنا هي تنفيذ “LLM كقاضٍ”. يستخدم هذا النهج الذكاء الاصطناعي لتقييم جودة وصحة الردود المولدة بالذكاء الاصطناعي – أي جعل الذكاء الاصطناعي يقيم أداء الذكاء الاصطناعي الآخر بقدرات تبرير متطورة.
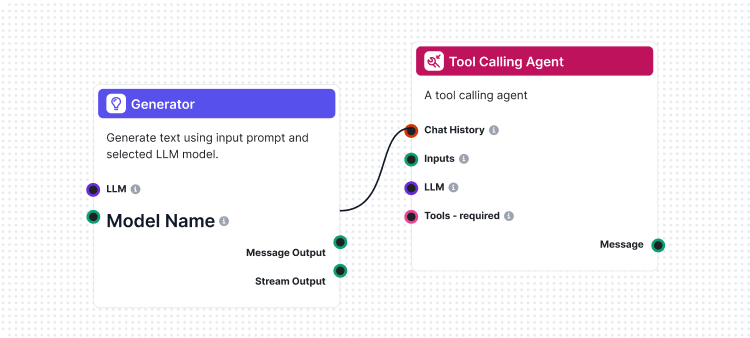
ما يجعل تنفيذنا فريداً هو أننا استخدمنا FlowHunt نفسه لإنشاء تدفق التقييم. يوضح هذا النهج قوة ومرونة منصتنا مع توفير نظام تقييم قوي. يتكون تدفق LLM كقاضٍ من عدة مكونات مترابطة:
1. قالب التوجيه: يصمم توجيه التقييم بمعايير محددة
2. مولّد المخرجات المهيكلة: يعالج التقييم باستخدام LLM
3. محلل البيانات: ينسق المخرجات المهيكلة لأغراض التقارير
4. مخرجات الدردشة: يعرض نتائج التقييم النهائية
في قلب نظام LLM كقاضٍ لدينا يوجد قالب توجيه مصمم بعناية لضمان تقييمات متسقة وموثوقة. إليك القالب الأساسي الذي نستخدمه:
You will be given an ANSWER and REFERENCE couple.
Your task is to provide the following:
1. a 'total_rating' scoring: how close is the ANSWER to the REFERENCE
2. a binary label 'correctness' which can be either 'correct' or 'incorrect', which defines if the ANSWER is correct or not
3. and 'reasoning', which describes the reason behind your choice of scoring and correctness/incorrectness of ANSWER
An ANSWER is correct when it is the same as the REFERENCE in all facts and details, even if worded differently. the ANSWER is incorrect if it contradicts the REFERENCE, changes or omits details. its ok if the ANSWER has more details comparing to REFERENCE.
'total rating' is a scale of 1 to 4, where 1 means that the ANSWER is not the same as REFERENCE at all, and 4 means that the ANSWER is the same as the REFERENCE in all facts and details even if worded differently.
Here is the scale you should use to build your answer:
1: The ANSWER is contradicts the REFERENCE completely, adds additional claims, changes or omits details
2: The ANSWER points to the same topic but the details are omitted or changed completely comparing to REFERENCE
3: The ANSWER's references are not completely correct, but the details are somewhat close to the details mentioned in the REFERENCE. its ok, if there are added details in ANSWER comparing to REFERENCES.
4: The ANSWER is the same as the REFERENCE in all facts and details, even if worded differently. its ok, if there are added details in ANSWER comparing to REFERENCES. if there are sources available in REFERENCE, its exactly the same as ANSWER and is for sure mentioned in ANSWER
REFERENCE
===
{target_response}
===
ANSWER
===
{actual_response}
===
يضمن هذا القالب أن يوفر القاضي الذكي لدينا:
يعرض تدفق LLM كقاضٍ لدينا تصميم سير عمل ذكاء اصطناعي متطور باستخدام منشئ تدفق FlowHunt المرئي. إليك كيف تعمل المكونات معاً:
يبدأ التدفق بمكون إدخال الدردشة الذي يستقبل طلب التقييم متضمناً الرد الفعلي والإجابة المرجعية.
يتم إنشاء قالب التوجيه ديناميكياً عبر مكون قالب التوجيه من خلال:
{target_response}{actual_response}يعالج مكون مولّد المخرجات المهيكلة القالب باستخدام LLM مختار، وينتج مخرجات مهيكلة تتضمن:
total_rating: تقييم رقمي من 1 إلى 4correctness: تصنيف صحيح/خاطئ ثنائيreasoning: شرح مفصل لنتيجة التقييميقوم مكون تحليل البيانات بتنسيق المخرجات المهيكلة لصيغة قابلة للقراءة، ويعرض مكون مخرجات الدردشة النتائج النهائية للتقييم.
يوفر نظام LLM كقاضٍ عدداً من الإمكانات المتقدمة التي تجعله فعالاً بشكل خاص لتقييم تدفقات الذكاء الاصطناعي:
على عكس المطابقة النصية البسيطة، يفهم القاضي الذكي لدينا:
يوفر مقياس التقييم المكون من 4 نقاط تقييماً دقيقاً:
يتضمن كل تقييم تبريراً مفصلاً، مما يتيح:
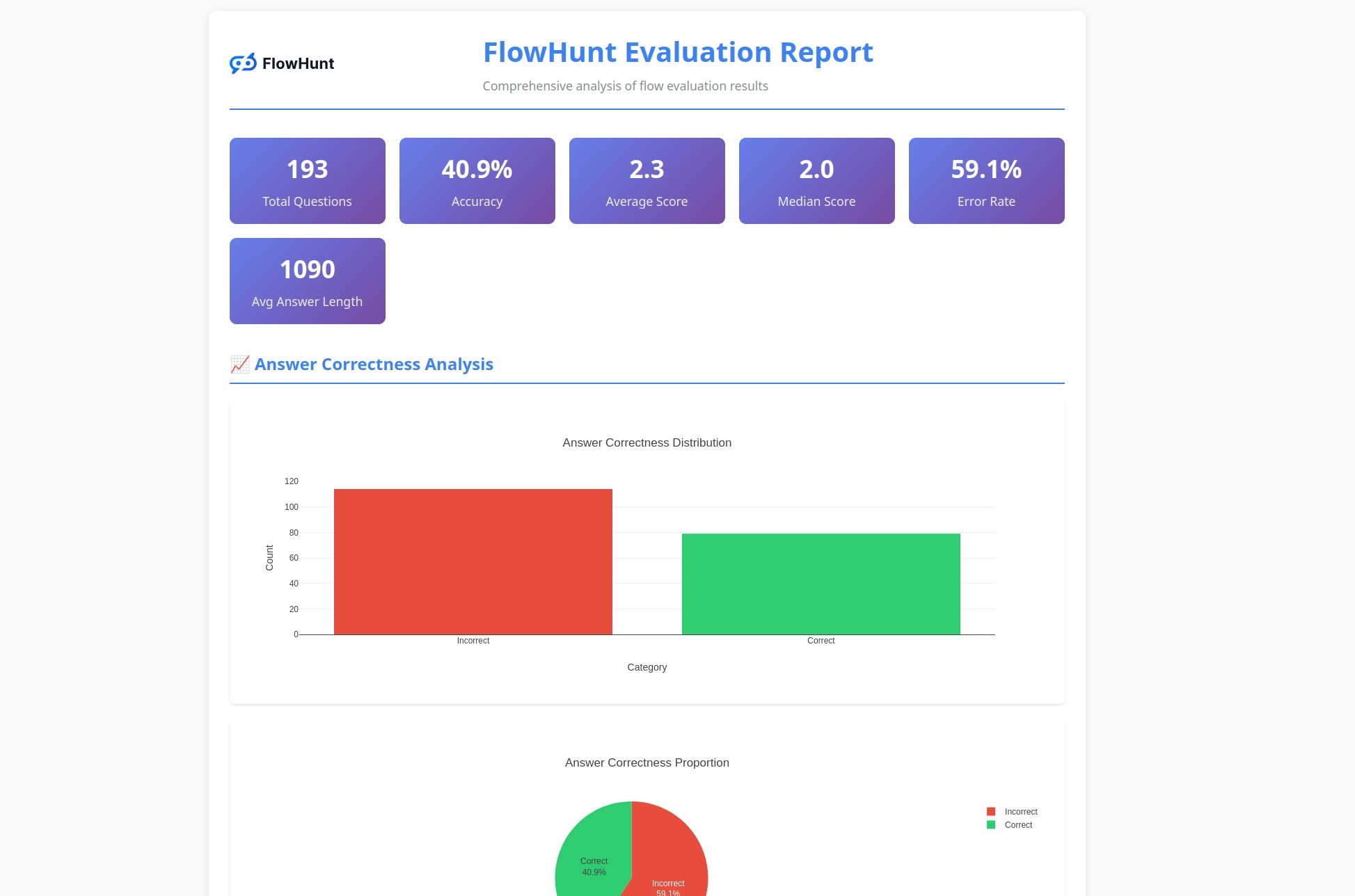
تنتج مجموعة أدوات CLI تقارير مفصلة توفر رؤى عملية حول أداء التدفق:
هل أنت مستعد لتقييم تدفقات الذكاء الاصطناعي الخاصة بك بأدوات احترافية؟ إليك كيفية البدء:
تثبيت بسطر واحد (موصى به) لنظامي macOS وLinux:
curl -sSL https://raw.githubusercontent.com/yasha-dev1/flowhunt-toolkit/main/install.sh | bash
سيقوم هذا تلقائياً بـ:
flowhunt إلى PATH الخاص بكتثبيت يدوي:
# استنساخ المستودع
git clone https://github.com/yasha-dev1/flowhunt-toolkit.git
cd flowhunt-toolkit
# التثبيت عبر pip
pip install -e .
التحقق من التثبيت:
flowhunt --help
flowhunt --version
1. المصادقة أولاً، قم بالمصادقة مع واجهة برمجة تطبيقات FlowHunt الخاصة بك:
flowhunt auth
2. عرض التدفقات الخاصة بك
flowhunt flows list
3. تقييم تدفق أنشئ ملف CSV ببيانات الاختبار الخاصة بك:
flow_input,expected_output
"What is 2+2?","4"
"What is the capital of France?","Paris"
شغّل التقييم مع LLM كقاضٍ:
flowhunt evaluate your-flow-id path/to/test-data.csv --judge-flow-id your-judge-flow-id
4. تنفيذ التدفقات دفعة واحدة
flowhunt batch-run your-flow-id input.csv --output-dir results/
يوفر نظام التقييم تحليلاً شاملاً:
flowhunt evaluate FLOW_ID TEST_DATA.csv \
--judge-flow-id JUDGE_FLOW_ID \
--output-dir eval_results/ \
--batch-size 10 \
--verbose
تشمل الميزات:
تتكامل مجموعة أدوات CLI بسلاسة مع منصة FlowHunt، مما يتيح لك:
يمثل إطلاق مجموعة أدوات CLI الخاصة بنا أكثر من مجرد أداة جديدة – إنه رؤية لمستقبل تطوير الذكاء الاصطناعي حيث:
الجودة قابلة للقياس: تقنيات التقييم المتقدمة تجعل أداء الذكاء الاصطناعي قابلاً للكمية والمقارنة.
الاختبار مؤتمت: أطر اختبار شاملة تقلل الجهد اليدوي وتحسن الاعتمادية.
الشفافية معيار: التبرير والتقارير المفصلة تجعل سلوك الذكاء الاصطناعي مفهوماً وقابلاً للتتبع.
المجتمع يقود الابتكار: أدوات مفتوحة المصدر تُمَكِّن من التحسين التعاوني وتبادل المعرفة.
من خلال فتح مصدر مجموعة أدوات FlowHunt CLI، نبرهن على التزامنا بـ:
تمثل مجموعة أدوات FlowHunt CLI مع LLM كقاضٍ تطوراً كبيراً في إمكانات تقييم تدفقات الذكاء الاصطناعي. من خلال الجمع بين منطق تقييم متقدم وتقارير شاملة وسهولة الوصول مفتوحة المصدر، نمكن المطورين من بناء أنظمة ذكاء اصطناعي أفضل وأكثر اعتمادية.
يظهر النهج الميتا في استخدام FlowHunt لتقييم تدفقات FlowHunt نضج ومرونة منصتنا مع توفير أداة قوية لمجتمع تطوير الذكاء الاصطناعي الأوسع.
سواء كنت تبني روبوتات دردشة بسيطة أو أنظمة متعددة الوكلاء معقدة، توفر مجموعة أدوات FlowHunt CLI البنية التحتية للتقييم التي تحتاجها لضمان الجودة والاعتمادية والتحسين المستمر.
هل أنت مستعد للارتقاء بتقييم تدفقات الذكاء الاصطناعي لديك؟ زر مستودع GitHub الخاص بنا وابدأ مع مجموعة أدوات FlowHunt CLI اليوم، واختبر قوة LLM كقاضٍ بنفسك.
مستقبل تطوير الذكاء الاصطناعي هنا – وهو مفتوح المصدر.
مجموعة أدوات FlowHunt CLI هي أداة سطر أوامر مفتوحة المصدر لتقييم تدفقات الذكاء الاصطناعي مع إمكانيات تقارير شاملة. تتضمن ميزات تقييم LLM كقاضٍ، وتحليل النتائج الصحيحة/الخاطئة، ومؤشرات أداء مفصلة.
يستخدم LLM كقاضٍ تدفق ذكاء اصطناعي متقدم تم بناؤه داخل FlowHunt لتقييم تدفقات أخرى. يقارن الردود الفعلية مع الإجابات المرجعية، ويوفر تقييمات، وتحليلات للصحة، وتبريرات مفصلة لكل تقييم.
مجموعة أدوات FlowHunt CLI مفتوحة المصدر ومتوفر على GitHub عبر https://github.com/yasha-dev1/flowhunt-toolkit. يمكنك استنساخها والمساهمة فيها واستخدامها بحرية لتلبية احتياجاتك في تقييم تدفقات الذكاء الاصطناعي.
تولد المجموعة تقارير شاملة تتضمن تحليل النتائج الصحيحة/الخاطئة، وتقييمات LLM كقاضٍ مع تقييمات وتبريرات، ومؤشرات أداء، وتحليل مفصل لسلوك التدفق عبر حالات الاختبار المختلفة.
نعم! تم بناء تدفق LLM كقاضٍ باستخدام منصة FlowHunt ويمكن تعديله لسيناريوهات تقييم متنوعة. يمكنك تعديل قالب التوجيه ومعايير التقييم لتناسب حالات الاستخدام الخاصة بك.
ياشا مطور برمجيات موهوب متخصص في بايثون وجافا وتعلم الآلة. يكتب ياشا مقالات تقنية عن الذكاء الاصطناعي، وهندسة البرومبت، وتطوير روبوتات الدردشة.
أنشئ وقيّم تدفقات الذكاء الاصطناعي المتقدمة باستخدام منصة FlowHunt. ابدأ اليوم في بناء تدفقات يمكنها تقييم تدفقات أخرى.
التدفقات هي العقل المدبر لكل شيء في FlowHunt. تعلم كيف تبنيها باستخدام منشئ بصري بدون كود، من وضع أول مكون إلى دمج الموقع الإلكتروني، ونشر روبوتات الدردشة، والا...
يقدم FlowHunt 2.4.1 نماذج ذكاء اصطناعي رئيسية جديدة بما في ذلك Claude وGrok وLlama وMistral وDALL-E 3 وStable Diffusion، ما يوسّع خياراتك للتجريب والإبداع والأت...
دليل شامل لتسعير FlowHunt، بما في ذلك كيفية عمل الاعتمادات والتفاعلات، وكيف تؤثر التعقيدات على التكاليف، وما يحدث للاعتمادات غير المستخدمة....

