
التسويق المدعوم بالذكاء الاصطناعي
يستفيد التسويق المدعوم بالذكاء الاصطناعي من تقنيات مثل التعلم الآلي، ومعالجة اللغة الطبيعية، والتحليلات التنبؤية لأتمتة المهام، واكتساب رؤى عن العملاء، وتقديم ت...
7 دقيقة قراءة
AI
Marketing
+7

يعتمد البحث بالذكاء الاصطناعي على التعلم الآلي وتضمينات المتجهات لفهم نية البحث والسياق، ما يوفر نتائج شديدة الصلة تتجاوز التطابق الدقيق للكلمات المفتاحية.
يستخدم البحث بالذكاء الاصطناعي التعلم الآلي لفهم سياق ونية استعلامات البحث، من خلال تحويلها إلى متجهات رقمية للحصول على نتائج أكثر دقة. وعلى عكس البحث التقليدي القائم على الكلمات المفتاحية، يفسر البحث بالذكاء الاصطناعي العلاقات الدلالية، ما يجعله فعالًا مع أنواع البيانات واللغات المتنوعة.
البحث بالذكاء الاصطناعي، الذي يُشار إليه غالبًا بالبحث الدلالي أو البحث بالمتجهات، هو منهجية بحث تعتمد على نماذج التعلم الآلي لفهم نية ومعنى استعلامات البحث في سياقها. وعلى عكس البحث التقليدي القائم على الكلمات المفتاحية، يحوّل البحث بالذكاء الاصطناعي البيانات والاستعلامات إلى تمثيلات رقمية تُسمى متجهات أو تضمينات. هذا يمكّن محرك البحث من فهم العلاقات الدلالية بين مختلف قطع البيانات، ما يوفر نتائج أكثر صلة ودقة حتى في غياب الكلمات المفتاحية المطابقة تمامًا.
يمثل البحث بالذكاء الاصطناعي تطورًا كبيرًا في تقنيات البحث. فمحركات البحث التقليدية تعتمد بشكل كبير على مطابقة الكلمات المفتاحية، حيث تحدد صلة النتائج بوجود مصطلحات معينة في كل من الاستعلام والمستندات. أما البحث بالذكاء الاصطناعي فيستخدم نماذج تعلم آلي لفهم السياق والمعنى الكامن وراء الاستعلامات والبيانات.
من خلال تحويل النصوص والصور والصوتيات والبيانات غير المنظمة الأخرى إلى متجهات عالية الأبعاد، يمكن للبحث بالذكاء الاصطناعي قياس التشابه بين محتويات مختلفة. هذه الطريقة تمكّن محرك البحث من تقديم نتائج ذات صلة بالسياق، حتى لو لم تتضمن نفس الكلمات المفتاحية الموجودة في الاستعلام.
المكونات الرئيسية:
يكمن جوهر البحث بالذكاء الاصطناعي في مفهوم تضمينات المتجهات. فهذه التضمينات هي تمثيلات رقمية للبيانات تلتقط المعنى الدلالي للنص أو الصور أو أنواع البيانات الأخرى. وتضع هذه التضمينات البيانات المتشابهة بالقرب من بعضها البعض في فضاء متجهات متعدد الأبعاد.
كيف تعمل:
مثال:
تعمل محركات البحث التقليدية القائمة على الكلمات المفتاحية عن طريق مطابقة المصطلحات في استعلام البحث مع المستندات التي تحتوي على تلك المصطلحات. وتعتمد على تقنيات مثل الفهارس المعكوسة وتكرار المصطلحات لترتيب النتائج.
قيود البحث القائم على الكلمات المفتاحية:
مزايا البحث بالذكاء الاصطناعي:
| الجانب | البحث القائم على الكلمات المفتاحية | البحث بالذكاء الاصطناعي (الدلالي/المتجهات) |
|---|---|---|
| المطابقة | تطابق الكلمات المفتاحية بدقة | تشابه دلالي |
| وعي بالسياق | محدود | عالي |
| معالجة المرادفات | تتطلب قوائم مرادفات يدوية | تلقائي عبر التضمينات |
| الأخطاء الإملائية | قد يفشل دون بحث تقريبي | أكثر تسامحًا بفضل السياق الدلالي |
| فهم النية | ضئيل | كبير |
يعد البحث الدلالي تطبيقًا أساسيًا للبحث بالذكاء الاصطناعي يركز على فهم نية المستخدم ومعنى الاستعلامات في سياقها.
العملية:
التقنيات الأساسية:
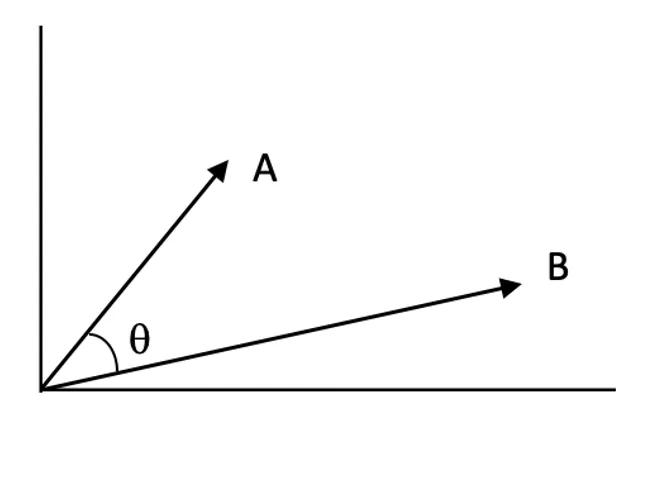
درجات التشابه:
تقيس درجات التشابه مدى ارتباط متجهين ببعضهما في فضاء المتجهات. وكلما كانت الدرجة أعلى، زادت صلة المستند بالاستعلام.
خوارزميات أقرب جار تقريبي (ANN):
البحث عن الجار الأقرب بدقة في الفضاءات عالية الأبعاد يحتاج موارد حسابية كبيرة. وتوفر خوارزميات ANN تقريبات فعالة.
يفتح البحث بالذكاء الاصطناعي الباب أمام مجموعة واسعة من التطبيقات في مختلف الصناعات بفضل قدرته على فهم البيانات وتفسيرها بما يتجاوز مطابقة الكلمات المفتاحية البسيطة.
الوصف: يعزز البحث الدلالي تجربة المستخدم من خلال تفسير نية الاستعلامات وتقديم نتائج ذات صلة بالسياق.
أمثلة:
الوصف: من خلال فهم تفضيلات وسلوكيات المستخدم، يمكن للبحث بالذكاء الاصطناعي تقديم محتوى أو منتجات مخصصة.
أمثلة:
الوصف: يمكّن البحث بالذكاء الاصطناعي الأنظمة من فهم استفسارات المستخدمين والإجابة عليها بمعلومات دقيقة مستخرجة من المستندات.
أمثلة:
الوصف: يمكن للبحث بالذكاء الاصطناعي فهرسة والبحث في أنواع البيانات غير المنظمة مثل الصور والصوتيات ومقاطع الفيديو من خلال تحويلها إلى تضمينات.
أمثلة:
إدماج البحث بالذكاء الاصطناعي في الأتمتة والشات بوتات يعزز قدراتها بشكل ملحوظ.
الفوائد:
خطوات التنفيذ:
مثال على حالة استخدام:
رغم مزايا البحث بالذكاء الاصطناعي العديدة، إلا أن هناك تحديات يجب أخذها في الاعتبار:
استراتيجيات التخفيف:
برز البحث الدلالي والمتجهي في الذكاء الاصطناعي كبدائل قوية للبحث التقليدي القائم على الكلمات المفتاحية والبحث التقريبي، معززًا بشكل كبير صلة ودقة نتائج البحث من خلال فهم السياق والمعنى وراء الاستعلامات.
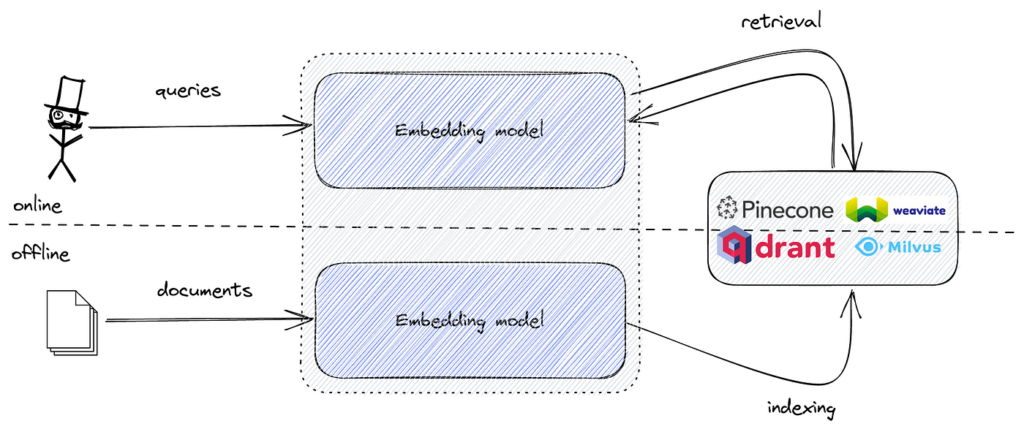
عند تنفيذ البحث الدلالي، يتم تحويل البيانات النصية إلى تضمينات متجهية تلتقط المعنى الدلالي للنص. وهذه التضمينات تمثيلات رقمية عالية الأبعاد. وللبحث بكفاءة عبر هذه التضمينات وإيجاد الأكثر تشابهًا مع تضمين الاستعلام، نحتاج إلى أداة محسّنة للبحث عن التشابه في الفضاءات عالية الأبعاد.
FAISS توفر الخوارزميات والهياكل البيانية اللازمة لأداء هذه المهمة بكفاءة. ومن خلال الجمع بين التضمينات الدلالية وFAISS، يمكننا إنشاء محرك بحث دلالي قوي قادر على التعامل مع مجموعات بيانات ضخمة بزمن استجابة منخفض.
ينطوي تنفيذ البحث الدلالي باستخدام FAISS في بايثون على عدة خطوات:
لنتعمق في كل خطوة بالتفصيل.
جهّز مجموعة البيانات الخاصة بك (مثلاً: مقالات، تذاكر الدعم، أوصاف المنتجات).
مثال:
documents = [
"كيفية إعادة تعيين كلمة المرور على منصتنا.",
"استكشاف مشكلات الاتصال بالشبكة وحلها.",
"دليل تثبيت تحديثات البرامج.",
"أفضل الممارسات لنسخ البيانات احتياطيًا واستعادتها.",
"إعداد المصادقة الثنائية لتعزيز الأمان."
]
نظّف ونسّق البيانات النصية حسب الحاجة.
حوّل البيانات النصية إلى تضمينات متجهية باستخدام نماذج Transformer المدربة مسبقًا من مكتبات مثل Hugging Face (transformers أو sentence-transformers).
مثال:
from sentence_transformers import SentenceTransformer
import numpy as np
# تحميل نموذج مدرب مسبقًا
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
# توليد التضمينات لكل المستندات
embeddings = model.encode(documents, convert_to_tensor=False)
embeddings = np.array(embeddings).astype('float32')
float32 حسب متطلبات FAISS.أنشئ فهرس FAISS لتخزين التضمينات وتمكين البحث الفعال عن التشابه.
مثال:
import faiss
embedding_dim = embeddings.shape[1]
index = faiss.IndexFlatL2(embedding_dim)
index.add(embeddings)
IndexFlatL2 ينفذ بحثًا دقيقًا باستخدام مسافة L2 (الإقليدية).حوّل استعلام المستخدم إلى تضمين وابحث عن أقرب الجيران.
مثال:
query = "كيف أغير كلمة مرور حسابي؟"
query_embedding = model.encode([query], convert_to_tensor=False)
query_embedding = np.array(query_embedding).astype('float32')
k = 3
distances, indices = index.search(query_embedding, k)
استخدم الفهارس لعرض أكثر المستندات صلة.
مثال:
print("أفضل النتائج لاستعلامك:")
for idx in indices[0]:
print(documents[idx])
الناتج المتوقع:
أفضل النتائج لاستعلامك:
كيفية إعادة تعيين كلمة المرور على منصتنا.
إعداد المصادقة الثنائية لتعزيز الأمان.
أفضل الممارسات لنسخ البيانات احتياطيًا واستعادتها.
توفر FAISS عدة أنواع من الفهارس:
استخدام فهرس الملفات المعكوسة (IndexIVFFlat):
nlist = 100
quantizer = faiss.IndexFlatL2(embedding_dim)
index = faiss.IndexIVFFlat(quantizer, embedding_dim, nlist, faiss.METRIC_L2)
index.train(embeddings)
index.add(embeddings)
التطبيع والبحث بالجداء الداخلي:
قد يكون استخدام تشابه جيب الزاوية أكثر فاعلية مع البيانات النصية
البحث بالذكاء الاصطناعي هو منهجية بحث حديثة تستخدم التعلم الآلي وتضمينات المتجهات لفهم نية ومعنى الاستعلامات في سياقها، ما يوفر نتائج أكثر دقة وصلة من البحث التقليدي القائم على الكلمات المفتاحية.
على عكس البحث القائم على الكلمات المفتاحية الذي يعتمد على التطابقات الدقيقة، يفسر البحث بالذكاء الاصطناعي العلاقات الدلالية والنية وراء الاستعلامات، ما يجعله فعالًا مع اللغة الطبيعية والمدخلات الغامضة.
تضمينات المتجهات هي تمثيلات رقمية للنصوص أو الصور أو أنواع البيانات الأخرى تلتقط معناها الدلالي، ما يمكّن محرك البحث من قياس التشابه والسياق بين قطع البيانات المختلفة.
يغذي البحث بالذكاء الاصطناعي البحث الدلالي في التجارة الإلكترونية، والتوصيات الشخصية في خدمات البث، وأنظمة الإجابة على الأسئلة في دعم العملاء، وتصفح البيانات غير المنظمة، واسترجاع الوثائق في البحث والشركات.
تشمل الأدوات الشائعة FAISS للبحث الفعال عن تشابه المتجهات، وقواعد بيانات المتجهات مثل Pinecone وMilvus وQdrant وWeaviate وElasticsearch وPgvector لتخزين واسترجاع التضمينات على نطاق واسع.
من خلال دمج البحث بالذكاء الاصطناعي، يمكن للشات بوتات وأنظمة الأتمتة فهم استفسارات المستخدمين بعمق أكبر، واسترجاع إجابات ذات صلة بالسياق، وتقديم ردود ديناميكية وشخصية.
تشمل التحديات المتطلبات العالية للمعالجة الحاسوبية، وتعقيد تفسير النماذج، والحاجة إلى بيانات عالية الجودة، وضمان الخصوصية والأمان مع المعلومات الحساسة.
FAISS مكتبة مفتوحة المصدر للبحث الفعال عن التشابه في تضمينات المتجهات عالية الأبعاد، وتستخدم على نطاق واسع لبناء محركات بحث دلالية قادرة على التعامل مع مجموعات بيانات كبيرة.
اكتشف كيف يمكن للبحث الدلالي المدعوم بالذكاء الاصطناعي أن يغيّر استرجاع المعلومات لديك، وشات بوتاتك، وتدفقات الأتمتة.
يستفيد التسويق المدعوم بالذكاء الاصطناعي من تقنيات مثل التعلم الآلي، ومعالجة اللغة الطبيعية، والتحليلات التنبؤية لأتمتة المهام، واكتساب رؤى عن العملاء، وتقديم ت...
اكتشف ما هو محرك الرؤى—منصة متقدمة مدعومة بالذكاء الاصطناعي تعزز البحث وتحليل البيانات من خلال فهم السياق والنية. تعرّف على كيفية دمج محركات الرؤى معالجة اللغة ...
أنشئ عناوين جذابة ومحسّنة لمحركات البحث باستخدام أبحاث وتحليلات مدعومة بالذكاء الاصطناعي. يجمع هذا الأداة بين بيانات بحث Google وتحليل محتوى الروابط لإنشاء عناو...
