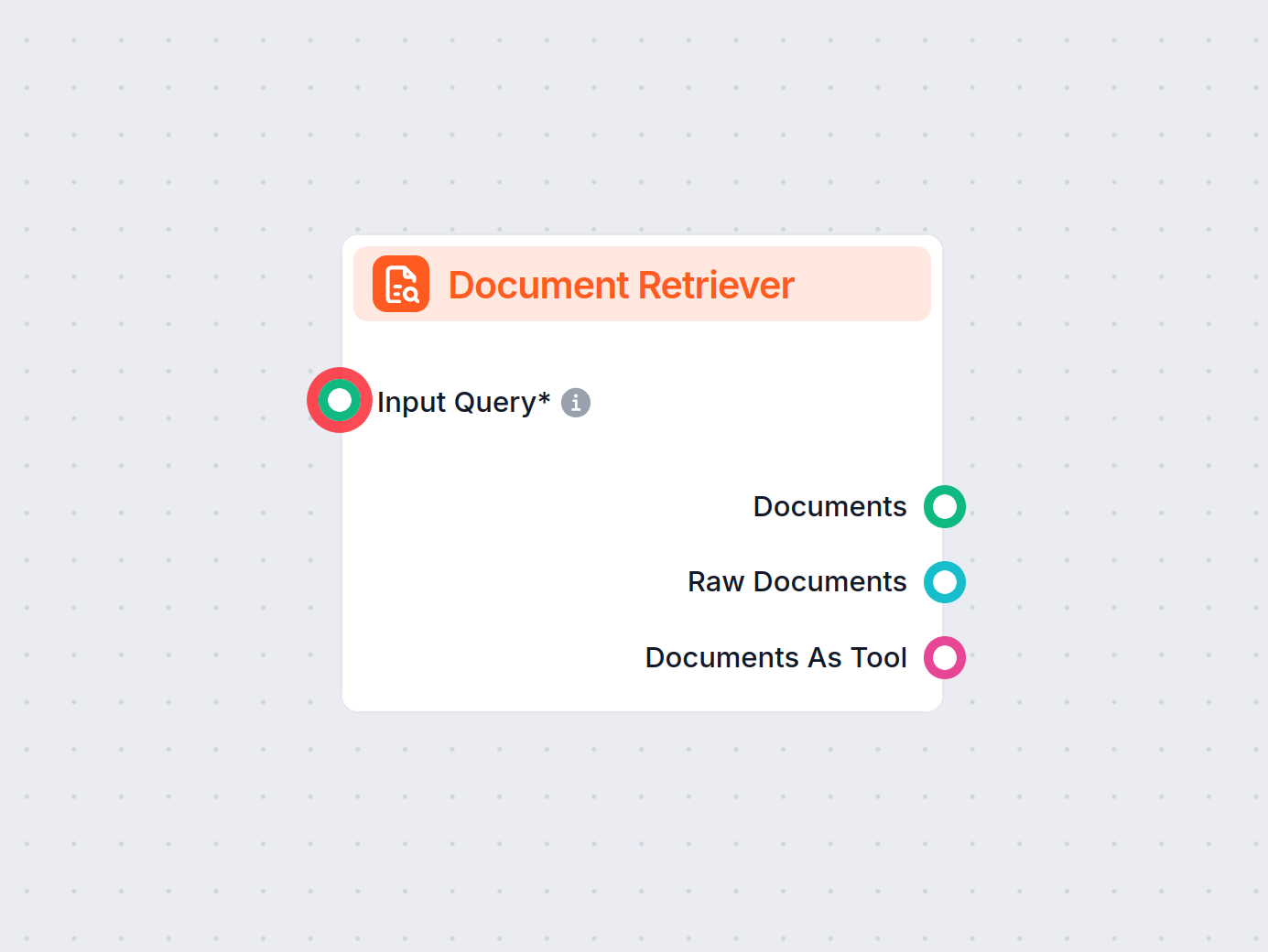
مسترجع المستندات
يعزز مسترجع المستندات من FlowHunt دقة الذكاء الاصطناعي من خلال ربط النماذج التوليدية بمستنداتك وروابطك الخاصة المحدثة، مما يضمن الحصول على إجابات موثوقة وذات صل...
4 دقيقة قراءة
AI
Document Retrieval
+3
يستخدم استرجاع المعلومات الذكاء الاصطناعي، ومعالجة اللغة الطبيعية، وتعلم الآلة لتعزيز دقة وكفاءة استرجاع البيانات عبر محركات البحث، والمكتبات الرقمية، وتطبيقات المؤسسات.
يتم تعزيز استرجاع المعلومات بشكل كبير بواسطة منهجيات الذكاء الاصطناعي لتحسين عمليات استرجاع البيانات بكفاءة ودقة لتلبية متطلبات المستخدم من المعلومات. تُعد أنظمة الاسترجاع أساسًا للعديد من التطبيقات مثل محركات البحث على الويب، والمكتبات الرقمية، وحلول البحث المؤسسي.
تُعد معالجة اللغة الطبيعية فرعًا محوريًا من الذكاء الاصطناعي يمكّن الآلات من فهم ومعالجة اللغات البشرية. ضمن مجال استرجاع المعلومات، تعمل معالجة اللغة الطبيعية على تعزيز الفهم الدلالي لاستفسارات المستخدم، مما يمكّن الأنظمة من تقديم نتائج بحث أكثر صلة من خلال تفسير السياق والنية وراء مدخلات المستخدم. تساهم تقنيات مثل تحليل المشاعر، وتقسيم الكلمات، والتحليل النحوي بشكل كبير في تحسين عملية الاسترجاع.
تلعب خوارزميات تعلم الآلة دورًا أساسيًا في استرجاع المعلومات من خلال التعلم من أنماط البيانات لزيادة ملاءمة نتائج البحث. تتطور هذه الخوارزميات من خلال التكيف مع سلوكيات وتفضيلات المستخدمين، مما يعزز تخصيص ودقة المعلومات المسترجعة. تُستخدم تقنيات مثل التعلم تحت الإشراف، والتعلم غير الخاضع للإشراف، والتعلم المعزز بشكل شائع لتحسين مهام الاسترجاع.
استفسارات المستخدم هي عبارات منظمة تعكس احتياجات المعلومات التي يقدمها المستخدم لنظام استرجاع المعلومات. تخضع هذه الاستفسارات للمعالجة لاستخراج المصطلحات المهمة وتقييم أهميتها، لتوجيه النظام في استرجاع المستندات ذات الصلة. غالبًا ما تُستخدم تقنيات مثل توسيع الاستفسار وإعادة صياغة الاستفسار لتحسين نتائج الاسترجاع.
تحسب النماذج الاحتمالية في استرجاع المعلومات احتمال مدى صلة المستند باستفسار معين. من خلال تقييم عوامل مثل تكرار المصطلحات وطول المستند، تقوم هذه النماذج بتقدير احتمالات الصلة وتقديم نتائج مرتبة بناءً على إحصاءات موزونة. من النماذج البارزة BM25 ونماذج الاسترجاع القائمة على الانحدار اللوجستي، والتي تُستخدم على نطاق واسع في أنظمة الاسترجاع.
يستخدم استرجاع المعلومات نماذج متنوعة لمعالجة تحديات مختلفة:
يتضمن تمثيل المستندات تحويلها إلى صيغة تسهل الاسترجاع الفعال. غالبًا ما يشمل ذلك فهرسة المصطلحات والبيانات الوصفية لضمان سرعة الوصول والترتيب الفعال للمستندات ذات الصلة. تُستخدم تقنيات مثل تكرار المصطلحات المعكوس (TF-IDF) والتضمين الدلالي للكلمات بشكل شائع.
تشير المستندات في استرجاع المعلومات إلى أي محتوى قابل للاسترجاع، بما في ذلك النصوص والصور والصوت والفيديو. أما الاستفسارات فهي مدخلات المستخدم التي توجه عملية الاسترجاع، وغالبًا ما يتم تمثيلها بطريقة مشابهة للمستندات لتمكين المطابقة والترتيب الفعالين.
يشير الفهم الدلالي في استرجاع المعلومات إلى عملية تفسير معنى وسياق الاستفسارات والمستندات. تعزز تقنيات الذكاء الاصطناعي المتقدمة، مثل توصيف الأدوار الدلالية والتعرف على الكيانات، هذه القدرة، مما يسمح للأنظمة بتقديم نتائج أقرب إلى نية المستخدم.
المستندات المسترجعة هي النتائج التي تقدمها أنظمة استرجاع المعلومات ردًا على استفسار المستخدم. غالبًا ما يتم ترتيب هذه المستندات بناءً على مدى صلتها بالاستفسار، باستخدام خوارزميات ونماذج ترتيب متنوعة.
تُعد محركات البحث على الويب تطبيقًا بارزًا لاسترجاع المعلومات، حيث تستخدم خوارزميات متقدمة لفهرسة وترتيب مليارات صفحات الويب، وتزويد المستخدمين بنتائج بحث ذات صلة باستفساراتهم. تستخدم محركات البحث مثل Google وBing تقنيات مثل PageRank وتعلم الآلة لتحسين عملية الاسترجاع.
من المتوقع أن يشهد مستقبل استرجاع المعلومات في الذكاء الاصطناعي تغييرات جذرية مع التقدم في الذكاء الاصطناعي التوليدي وتعلم الآلة. تعد هذه التقنيات بفهم دلالي أعمق، وتوليف فوري للمعلومات، وتجارب بحث مخصصة، مما قد يحدث ثورة في تفاعل المستخدمين مع أنظمة المعلومات. من الاتجاهات الناشئة دمج نماذج التعلم العميق لتحسين الفهم السياقي، وتطوير واجهات بحث محادثية لتجارب أكثر سهولة وذكاءً.
يُعد استرجاع المعلومات (IR) في الذكاء الاصطناعي عملية الحصول على المعلومات ذات الصلة من مجموعات البيانات الضخمة وقواعد البيانات، وقد أصبح أكثر أهمية في عصر البيانات الضخمة. يعمل الباحثون على تطوير أنظمة مبتكرة تعتمد على الذكاء الاصطناعي لتعزيز دقة وكفاءة الاسترجاع. فيما يلي بعض التطورات الحديثة من المجتمع العلمي التي تسلط الضوء على إنجازات بارزة في هذا المجال:
المؤلفون: Xiaoyu Wang, Haoyong Ouyang, Balu Bhasuran, Xiao Luo, Karim Hanna, Mia Liza A. Lustria, Zhe He
يقدم هذا البحث نظام Lab-AI المصمم لتوفير تفسيرات مخصصة لاختبارات المعمل في البيئات السريرية. بخلاف بوابات المرضى التقليدية التي تستخدم نطاقات طبيعية عامة، يستخدم Lab-AI الاسترجاع المعزز بالتوليد (RAG) لتقديم نطاقات طبيعية شخصية بناءً على عوامل فردية مثل العمر والجنس. يتكون النظام من وحدتين: استرجاع العوامل واسترجاع النطاق الطبيعي، حيث حقق درجة F1 بلغت 0.95 لاسترجاع العوامل ودقة 0.993 لاسترجاع النطاق الطبيعي. تفوق بشكل كبير على الأنظمة غير المعتمدة على RAG، مما عزز فهم المرضى لنتائج التحاليل.
اقرأ المزيد
المؤلفون: Mohammed-Khalil Ghali, Abdelrahman Farrag, Daehan Won, Yu Jin
تتناول هذه الدراسة تحديات استرجاع المعرفة من قواعد البيانات الضخمة، وتبرز محدودية النماذج اللغوية الكبيرة التقليدية (LLMs) في الاستفسارات المتخصصة. تجمع المنهجية المقترحة بين LLMs وقواعد البيانات المتجهية لتحسين دقة الاسترجاع دون الحاجة إلى ضبط كبير. حقق نموذجهم، الاسترجاع النصي التوليدي (GTR)، دقة تزيد عن 90% وتألق في مجموعات بيانات متنوعة، مما يُظهر قدرة كبيرة على ديمقراطية أدوات الذكاء الاصطناعي وتحسين قابلية التوسع في استرجاع المعلومات المدعوم بالذكاء الاصطناعي.
اقرأ المزيد
المؤلفون: Vaibhav Balloli, Sara Beery, Elizabeth Bondi-Kelly
يستكشف هذا البحث تطبيق الذكاء الاصطناعي في استرجاع الصور، وهو أمر بالغ الأهمية في مجالات مثل الحفاظ على الحياة البرية والرعاية الصحية. يركز البحث على دمج الخبرة البشرية في أنظمة الذكاء الاصطناعي لمعالجة محدودية تقنيات التعلم العميق في السيناريوهات الواقعية. تجمع منهجية “البشر في الحلقة” بين الحكم البشري وتحليل الذكاء الاصطناعي لتعزيز عملية الاسترجاع.
اقرأ المزيد
استرجاع المعلومات (IR) هو عملية الحصول على المعلومات ذات الصلة من مجموعات بيانات ضخمة باستخدام الذكاء الاصطناعي ومعالجة اللغة الطبيعية وتعلم الآلة لتلبية احتياجات المستخدم من المعلومات بكفاءة ودقة.
يشغّل الاسترجاع محركات البحث على الويب، والمكتبات الرقمية، وحلول البحث المؤسسي، وتوصيات المنتجات في التجارة الإلكترونية، واسترجاع السجلات الطبية، والبحث القانوني.
يعزز الذكاء الاصطناعي عملية الاسترجاع من خلال الاستفادة من معالجة اللغة الطبيعية لفهم المعنى الدلالي، وتعلم الآلة للترتيب والتخصيص، والنماذج الاحتمالية لتقدير الصلة، مما يحسن دقة وملاءمة نتائج البحث.
تشمل التحديات الرئيسية الغموض في اللغة، وانحياز الخوارزميات، ومخاوف خصوصية البيانات، وقابلية التوسع مع زيادة حجم البيانات.
تشمل التوجهات المستقبلية دمج الذكاء الاصطناعي التوليدي، والتعلم العميق لفهم السياق بشكل أفضل، وبناء تجارب بحث أكثر تخصيصًا وتفاعلية.
الدردشة الذكية وأدوات الذكاء الاصطناعي تحت سقف واحد. اربط الكتل التفاعلية وحول أفكارك إلى تدفقات مؤتمتة.
يعزز مسترجع المستندات من FlowHunt دقة الذكاء الاصطناعي من خلال ربط النماذج التوليدية بمستنداتك وروابطك الخاصة المحدثة، مما يضمن الحصول على إجابات موثوقة وذات صل...
الإجابة على الأسئلة مع الجيل المعزز بالاسترجاع (RAG) تجمع بين استرجاع المعلومات وتوليد اللغة الطبيعية لتعزيز نماذج اللغة الكبيرة (LLMs) من خلال دعم الإجابات ببي...
يُعد البحث المحسن في المستندات باستخدام معالجة اللغة الطبيعية (NLP) دمجًا لتقنيات معالجة اللغة الطبيعية المتقدمة ضمن أنظمة استرجاع المستندات، مما يحسن الدقة وال...

