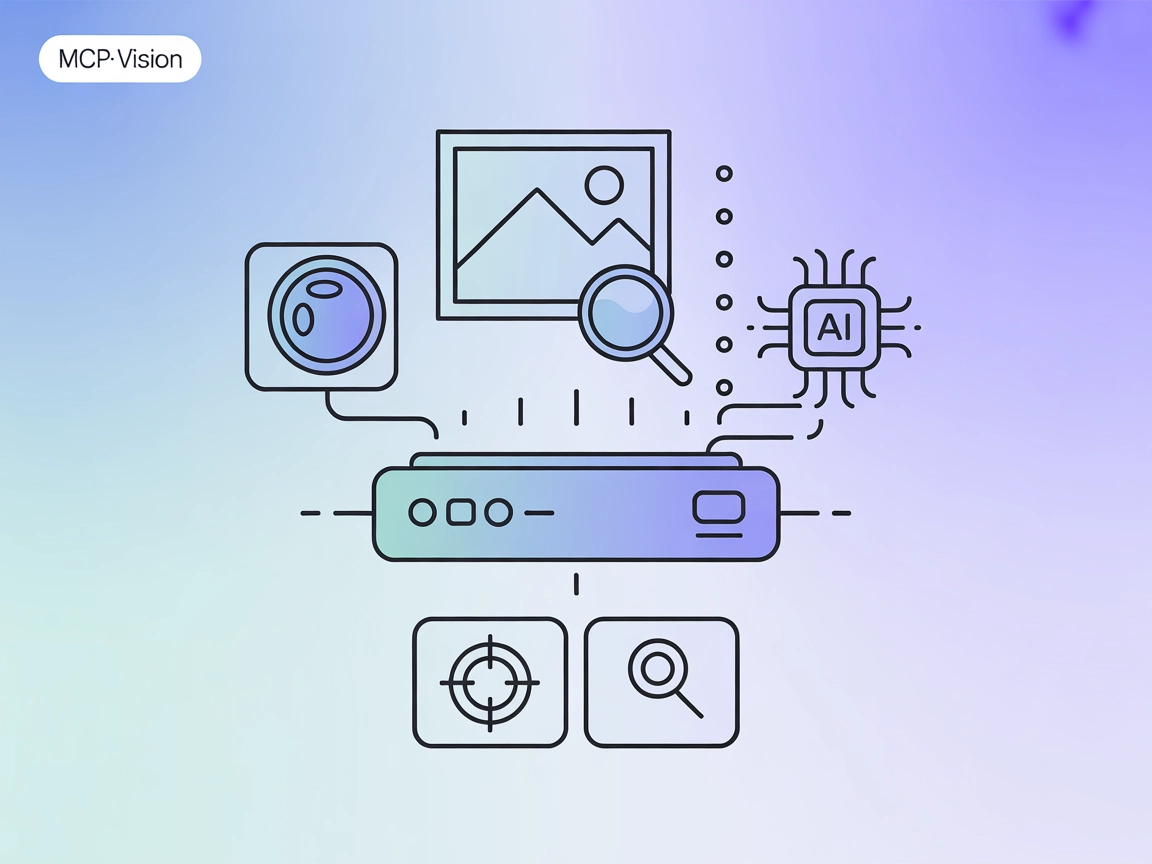
خادم OpenCV MCP
يعمل خادم OpenCV MCP كجسر بين أدوات معالجة الصور والفيديو القوية في OpenCV ومساعدي الذكاء الاصطناعي ومنصات المطورين عبر بروتوكول Model Context Protocol (MCP). ي...
4 دقيقة قراءة
OpenCV
MCP Server
+4
يعمل خادم OpenCV MCP كجسر بين أدوات معالجة الصور والفيديو القوية في OpenCV ومساعدي الذكاء الاصطناعي ومنصات المطورين عبر بروتوكول Model Context Protocol (MCP). ي...
يعمل خادم mcp-vision MCP على ربط نماذج الرؤية الحاسوبية من HuggingFace — مثل اكتشاف الأجسام بدون تدريب مسبق — مع FlowHunt ومنصات الذكاء الاصطناعي الأخرى، مما يم...
اكتشف أداة FlowHunt المدعومة بالذكاء الاصطناعي لتوليد تسميات الصور. أنشئ تسميات جذابة وملائمة لصورك فوراً مع إمكانية تخصيص الأنماط والنغمات—مثالية لعشاق وسائل ا...
أوبن سي في هو مكتبة متقدمة ومفتوحة المصدر للرؤية الحاسوبية وتعلم الآلة، تقدم أكثر من 2500 خوارزمية لمعالجة الصور، واكتشاف الأجسام، والتطبيقات اللحظية عبر لغات و...
يعمل إثراء المحتوى بالذكاء الاصطناعي على تحسين المحتوى الخام وغير المنظم من خلال تطبيق تقنيات الذكاء الاصطناعي لاستخلاص معلومات ذات معنى، وهيكلة المحتوى، واستخر...
استكشف إعادة البناء الثلاثي الأبعاد: تعرّف كيف تلتقط هذه العملية المتقدمة الأجسام أو البيئات الواقعية وتحولها إلى نماذج ثلاثية الأبعاد مفصّلة باستخدام تقنيات مث...
التجزئة الدلالية هي تقنية في رؤية الحاسوب تقوم بتقسيم الصور إلى عدة مقاطع، مع إعطاء كل بكسل تسمية فئة تمثل كائنًا أو منطقة. تمكّن من فهم تفصيلي لتطبيقات مثل الق...
التعرف على الأنماط هو عملية حسابية تهدف إلى تحديد الأنماط والانتظام في البيانات، وهو أمر بالغ الأهمية في مجالات مثل الذكاء الاصطناعي وعلوم الحاسوب وعلم النفس وت...
اكتشف ما هو التعرف على الصور في الذكاء الاصطناعي. ما هي استخداماته، وما هي الاتجاهات السائدة، وكيف يختلف عن التقنيات المشابهة....
التعرف على النصوص في المشاهد (STR) هو فرع متخصص من التعرف الضوئي على الحروف (OCR) يركز على تحديد وتفسير النصوص داخل الصور الملتقطة في المشاهد الطبيعية باستخدام ...
التعلم العميق هو فرع من فروع التعلم الآلي في الذكاء الاصطناعي (AI) يحاكي آلية عمل الدماغ البشري في معالجة البيانات وإنشاء الأنماط لاستخدامها في اتخاذ القرار. وه...
الرؤية الحاسوبية هي مجال ضمن الذكاء الاصطناعي (AI) يركز على تمكين الحواسيب من تفسير وفهم العالم المرئي. من خلال الاستفادة من الصور الرقمية من الكاميرات والفيديو...
الشبكة العصبية الالتفافية (CNN) هي نوع متخصص من الشبكات العصبية الاصطناعية مصممة لمعالجة البيانات الشبكية المنظمة مثل الصور. تعتبر CNN فعالة بشكل خاص في المهام ...
يعد المتوسط المرجح للدقة (mAP) مقياسًا رئيسيًا في رؤية الحاسوب لتقييم نماذج اكتشاف الأجسام، حيث يجمع بين دقة الاكتشاف وتحديد الموقع بقيمة عددية واحدة. يُستخدم ع...
باي تورش هو إطار تعلم آلي مفتوح المصدر تم تطويره بواسطة Meta AI، ويشتهر بمرونته، ورسومه البيانية الديناميكية للحساب، وتسريع وحدة معالجة الرسومات، ودمجه السلس مع...
تجزئة الكائنات الفردية هي مهمة في رؤية الحاسوب تهدف إلى اكتشاف وتحديد كل كائن مميز في الصورة بدقة على مستوى البكسل. تعزز هذه التقنية التطبيقات من خلال توفير فهم...
يضبط الضبط الدقيق للنموذج النماذج المدربة مسبقًا لتلائم مهام جديدة من خلال إجراء تعديلات طفيفة، مما يقلل الحاجة إلى البيانات والموارد. تعرف على كيفية استفادة ال...
تقدير العمق هو مهمة محورية في رؤية الحاسوب، تركز على التنبؤ بمسافة الأجسام داخل الصورة بالنسبة للكاميرا. يحول بيانات الصور ثنائية الأبعاد إلى معلومات مكانية ثلا...
تقدير الوضعية هو تقنية في رؤية الحاسوب تتنبأ بموقع واتجاه شخص أو جسم في الصور أو الفيديوهات من خلال تحديد وتتبع النقاط الرئيسية. تُعد هذه التقنية ضرورية لتطبيقا...
كافيه هو إطار عمل مفتوح المصدر للتعلم العميق من مركز بيركلي للرؤية والتعلم (BVLC)، مُحسّن للسرعة والتجزئة في بناء الشبكات العصبية الالتفافية (CNNs). يُستخدم على...
محولات Hugging Face هي مكتبة بايثون مفتوحة المصدر رائدة تسهّل تنفيذ نماذج المحول (Transformer) لمهام تعلم الآلة في معالجة اللغة الطبيعية، ورؤية الحاسوب، ومعالجة...
تعرّف على نماذج الذكاء الاصطناعي التمييزية—نماذج تعلم الآلة التي تركز على التصنيف والانحدار من خلال نمذجة حدود القرار بين الفئات. افهم كيفية عملها، ومميزاتها، و...
نموذج الذكاء الاصطناعي الأساسي هو نموذج تعلم آلي واسع النطاق يتم تدريبه على كميات هائلة من البيانات، وقابل للتكيف مع مجموعة واسعة من المهام. لقد أحدثت نماذج الأ...