
Text Generation
Text Generation with Large Language Models (LLMs) refers to the advanced use of machine learning models to produce human-like text from prompts. Explore how LLM...
7 min read
AI
Text Generation
+5

FlowHunt tests and ranks leading LLMs—including GPT-4, Claude 3, Llama 3, and Grok—for content writing, evaluating readability, tone, originality, and keyword usage to help you choose the best model for your needs.
Large Language Models (LLMs) are cutting-edge AI tools that reshape how we create and consume content. Before we go deeper into the differences between individual LLMs, you should understand what allows these models to create human-like text so effortlessly.
LLMs are trained on huge datasets, which helps them grasp context, semantics, and syntax. Based on the amount of data, they can correctly predict the next word in a sentence, piecing the words into understandable writing. One reason for their effectiveness is the transformer architecture. This self-attention mechanism uses neural networks to process text syntax and semantics. This means LLMs can handle a wide range of complex tasks with ease.
Large Language Models (LLMs) have transformed the way businesses approach content creation. With their ability to produce personalized and optimized text, LLMs generate content like emails, landing pages, and social media posts using human language prompts.
Here’s what LLMs can help content writers with:
Moreover, the future of LLMs looks promising. Advancements in technology are likely to improve their accuracy and multimodal capabilities. This expansion of applications will influence various industries significantly.
Start your free trial today and see results within days.
Here’s a quick look at the popular LLMs we will be testing:
| Model | Unique Strengths |
|---|---|
| GPT-4 | Versatile in various writing styles |
| Claude 3 | Excels in creative and contextual tasks |
| Llama 3.2 | Known for efficient text summarization |
| Grok | Known for focus on a laid-back and humorous tone |
When choosing an LLM, it’s essential to consider your content creation needs. Each model offers something unique, from handling complex tasks to generating AI-driven creative content. Before we test them, let’s briefly summarize each to see how it can benefit your content creation process.
Key Features:
Performance Metrics:
Strengths:
Challenges:
Overall, GPT-4 is a powerful tool for businesses looking to enhance their content creation and data analysis strategies.
Key Features:
Strengths:
Challenges:
Key Features:
Strengths:
Challenges:
Llama 3 stands out as a robust and versatile open-source LLM, promising advancements in AI capabilities while also presenting certain challenges for users.
Key Features:
Strengths:
Challenges:
In summary, while xAI Grok provides interesting features and has the advantage of media visibility, it faces significant challenges in popularity and performance within the competitive landscape of language models.
Let’s jump right into the testing. We’ll rank the models using a basic blog writing output. All testing was performed in FlowHunt, only changing the LLM models.
Key focus areas:
Test prompt:
Write a blog post titled “10 Easy Ways to Live Sustainably Without Breaking the Bank.” The tone should be practical and approachable, with a focus on actionable tips that are realistic for busy individuals. Highlight “sustainability on a budget” as the main keyword. Include examples for everyday scenarios like grocery shopping, energy use, and personal habits. Wrap up with an encouraging call-to-action for readers to start with one tip today.
Note: The Flow is limited to only create output of approximately 500 words. If you feel the outputs are rushed or don’t go in-depth, this is on purpose.
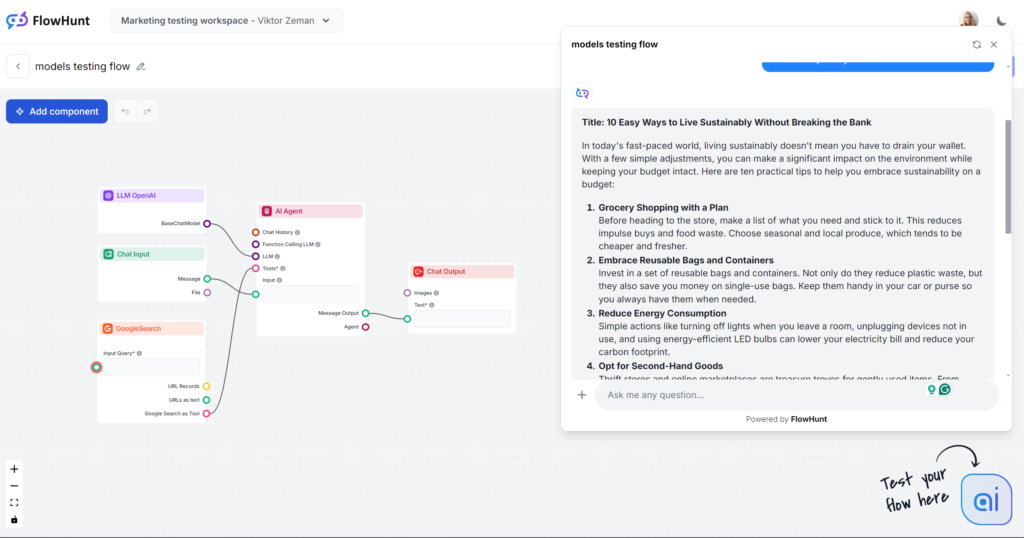
If this were a blind test, the “In today’s fast-paced world…” opening line would tip you off immediately. You’re likely quite familiar with this model’s writing, as it’s not only the most popular choice but also the core of most third-party AI writing tools. GPT-4o is always a safe choice for general content but be prepared for vagueness and wordiness.
Tone and Language
Looking past the painfully overused opening sentence, GPT-4o did exactly what we expected. You wouldn’t fool anyone that a human wrote this, but it’s still a decently structured article and it undeniably follows our prompt. The tone really is practical and approachable, immediately focusing on actionable tips instead of vague rambling.
Keyword usage
GPT-4o fared well in the keyword usage test. Not only did it successfully use the provided main keyword, but it also used similar phrases and other fitting keywords.
Readability
On a Flesch-Kincaid scale, this output ranks as 10th-12th grade (fairly difficult) with a score of 51.2. A point lower, it would rank at the college level. With such a short output, even the keyword “sustainability” itself probably has a noticeable effect on the readability. That being said, there’s certainly loads of room for improvement.
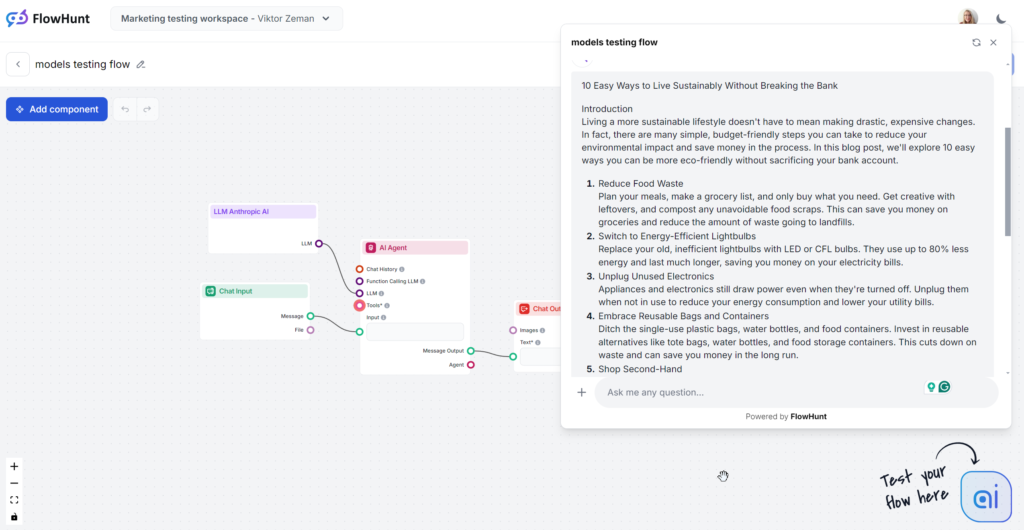
The analyzed Claude output is the mid-range Sonnet model rumored to be the best route for content. The content reads well and is noticeably more human than GPT-4o or Llama. Claude is the perfect solution for clean and simple content to deliver information efficiently without being too wordy like GPT or flashy like Grok.
Tone and Language
Claude stands out for its simple, relatable, and human-like answers. The tone is practical and approachable, immediately focusing on actionable tips instead of vague rambling.
Keyword usage
Claude was the only model to ignore the keyword part of the prompt, using it only in 1 out of 3 outputs. When it included a keyword, it did so in the conclusion, and the usage felt somewhat forced.
Readability
Claude’s Sonnet scored high on the Flesch-Kincaid scale, ranking in 8th & 9th grade (Plain English), just a couple of points behind Grok. While Grok shifted the whole tone and vocabulary to achieve this, Claude used a similar vocabulary to GPT-4o. What made the readability so good? Shorter sentences, everyday words, and no vague content.
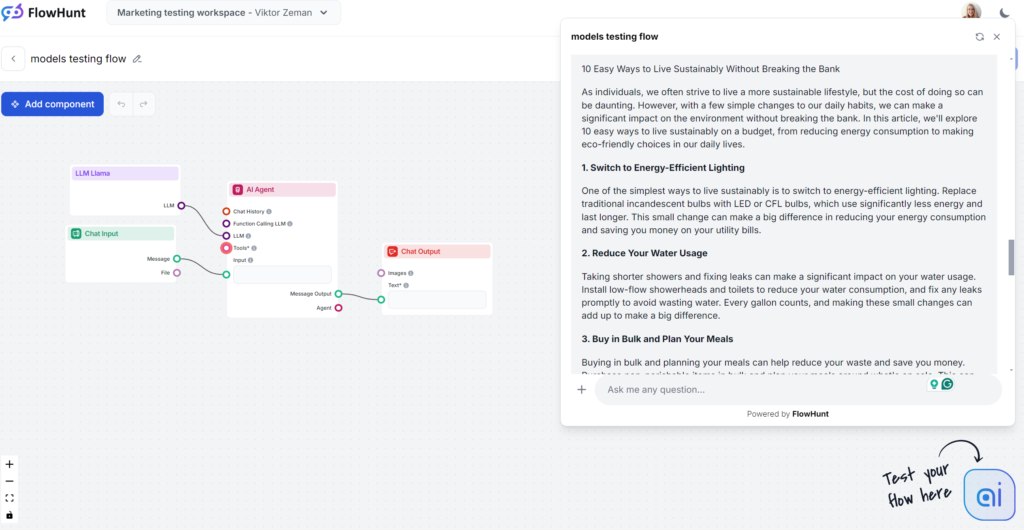
Llama’s strongest point was the keyword usage. On the other hand, the writing style was uninspired and a bit wordy, but still less boring than GPT-4o. Llama is like GPT-4o’s cousin – a safe content choice with a slightly wordy and vague writing style. It’s a great choice if you generally like the writing style of OpenAI models but want to skip the classic GPT phrases.
Tone and Language
Llama-generated articles read a lot like the ones from GPT-4o. The wordiness and vagueness is comparable, but the tone is practical and approachable.
Keyword usage
Meta is the winner in the keyword usage test. Llama used the keyword more than once, including in the introduction, and naturally included similar phrases and other fitting keywords.
Readability
On a Flesch-Kincaid scale, this output ranks as 10th-12th grade (fairly difficult), scoring 53.4, just slightly better than GPT-4o (51.2). With such a short output, even the keyword “sustainability” itself probably has a noticeable effect on the readability. Still, there’s room for improvement.
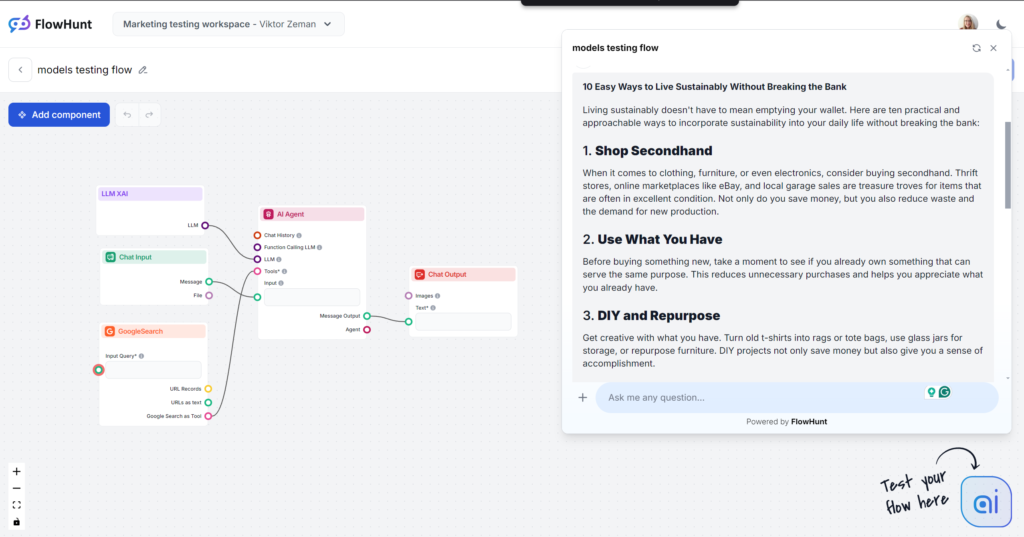
Grok was a huge surprise, especially in tone and language. With a very natural and laid-back tone, it felt like you were getting some quick tips from a close friend. If laid-back and snappy is your style of writing, Grok is definitely the choice for you.
Tone and Language
The output reads very well. The language is natural, sentences are snappy, and Grok uses idioms well. The model stays true to its primary tone and pushes the envelope on human-like text. Note: Grok’s laid-back tone isn’t always a good choice for B2B and SEO-driven content.
Keyword usage
Grok used the keyword we asked for, but only in the conclusion. Other models did better keyword placement and added other relevant keywords, while Grok focused more on the flow of language.
Readability
With the easy-going language, Grok passed the Flesch-Kincaid test with flying colors. It scored 61.4, which falls in the 7th-8th grade (plain English) territory. It’s optimal for making topics accessible to the general population. This great leap in readability is almost tangible.
Get latest tips, trends, and deals for free.
The power of LLMs hinges on the quality of training data, which can sometimes be biased or inaccurate, leading to the spread of misinformation. It is vital to fact-check and vet AI-generated content for fairness and inclusivity. When experimenting with various models, remember that each model has a different approach to input data privacy and limiting harmful output.
To guide ethical use, organizations must establish frameworks addressing data privacy, bias mitigation, and content moderation. This includes regular dialogue between AI developers, writers, and legal experts. Consider this list of ethical concerns:
The choice of LLMs should align ethically with an organization’s content guidelines. Both open-source and proprietary models should be evaluated for potential misuse.
Bias, inaccuracy, and hallucinations remain major issues with generated AI content. Thanks to the built-in guidelines, this often results in vague, low-value output of LLMs. Businesses often need extra training and security measures to address these issues. For small businesses, time and resources for custom training are often out of reach. An alternative is adding these capabilities by using general models via third-party tools like FlowHunt.
FlowHunt allows you to give specific knowledge, internet access, and new capabilities to classic base models. This way, you can choose the right model for the task without base model limitations or countless subscriptions.
Another major issue is the complexity of these models. With billions of parameters, they can be tricky to manage, understand, and debug. FlowHunt gives you much more control than plain prompts to chat ever could. You get to add individual capabilities as blocks and tweak them to create your library of ready-to-go AI Tools.
The future of language models (LLMs) in content writing is promising and exciting. As these models advance, they promise greater accuracy and less bias in content generation. This means writers will get to produce reliable, human-like text with AI-generated content.
LLMs will not only handle text but also become proficient in multimodal content creation. This includes managing both text and images, boosting creative content for diverse industries. With larger and better-filtered datasets, LLMs will craft more dependable content and refine writing styles.
But for now, LLMs can’t do that on their own, and these capabilities are divided among various companies and models, each fighting for your attention and money. FlowHunt brings them all together and lets
GPT-4 is the most popular and versatile for general content, but Meta’s Llama offers a fresher writing style. Claude 3 is best for clean, simple content, while Grok excels with a laid-back, human-like tone. The best choice depends on your content goals and style preferences.
Consider readability, tone, originality, keyword usage, and how each model aligns with your content needs. Also, weigh strengths like creativity, genre versatility, or integration potential, and be mindful of challenges such as bias, verbosity, or resource requirements.
FlowHunt lets you test and compare multiple leading LLMs in one environment, providing control over output and enabling you to find the best model for your specific content workflow without multiple subscriptions.
Yes. LLMs can perpetuate bias, generate misinformation, and raise data privacy concerns. It’s vital to fact-check AI outputs, evaluate models for ethical alignment, and establish frameworks for responsible use.
Future LLMs will offer improved accuracy, less bias, and multimodal content generation (text, images, etc.), empowering writers to create more reliable and creative content. Unified platforms like FlowHunt will streamline access to these advanced capabilities.
Experience top LLMs side-by-side and enhance your content writing workflow with FlowHunt’s unified platform.
Text Generation with Large Language Models (LLMs) refers to the advanced use of machine learning models to produce human-like text from prompts. Explore how LLM...
A Large Language Model (LLM) is a type of AI trained on vast textual data to understand, generate, and manipulate human language. LLMs use deep learning and tra...

Discover the essential GPU requirements for Large Language Models (LLMs), including training vs inference needs, hardware specifications, and choosing the right...