
Patronus MCP
Integrate FlowHunt with Patronus MCP Server to streamline LLM system optimization, evaluation, and experimentation. Standardize AI model testing, automate exper...
4 min read
AI
Patronus MCP
+4

FlowHunt’s new open-source CLI toolkit enables comprehensive flow evaluation with LLM as a Judge, providing detailed reporting and automated quality assessment for AI workflows.
We’re excited to announce the release of the FlowHunt CLI Toolkit – our new open-source command-line tool designed to revolutionize how developers evaluate and test AI flows. This powerful toolkit brings enterprise-grade flow evaluation capabilities to the open-source community, complete with advanced reporting and our innovative “LLM as a Judge” implementation.
The FlowHunt CLI Toolkit represents a significant step forward in AI workflow testing and evaluation. Available now on GitHub , this open-source toolkit provides developers with comprehensive tools for:
The toolkit embodies our commitment to transparency and community-driven development, making advanced AI evaluation techniques accessible to developers worldwide.
One of the most innovative features of our CLI toolkit is the “LLM as a Judge” implementation. This approach uses artificial intelligence to evaluate the quality and correctness of AI-generated responses – essentially having AI judge AI performance with sophisticated reasoning capabilities.
What makes our implementation unique is that we used FlowHunt itself to create the evaluation flow. This meta-approach demonstrates the power and flexibility of our platform while providing a robust evaluation system. The LLM as a Judge flow consists of several interconnected components:
1. Prompt Template: Crafts the evaluation prompt with specific criteria 2. Structured Output Generator: Processes the evaluation using an LLM 3. Data Parser: Formats the structured output for reporting 4. Chat Output: Presents the final evaluation results
At the heart of our LLM as a Judge system is a carefully crafted prompt that ensures consistent and reliable evaluations. Here’s the core prompt template we use:
You will be given an ANSWER and REFERENCE couple.
Your task is to provide the following:
1. a 'total_rating' scoring: how close is the ANSWER to the REFERENCE
2. a binary label 'correctness' which can be either 'correct' or 'incorrect', which defines if the ANSWER is correct or not
3. and 'reasoning', which describes the reason behind your choice of scoring and correctness/incorrectness of ANSWER
An ANSWER is correct when it is the same as the REFERENCE in all facts and details, even if worded differently. the ANSWER is incorrect if it contradicts the REFERENCE, changes or omits details. its ok if the ANSWER has more details comparing to REFERENCE.
'total rating' is a scale of 1 to 4, where 1 means that the ANSWER is not the same as REFERENCE at all, and 4 means that the ANSWER is the same as the REFERENCE in all facts and details even if worded differently.
Here is the scale you should use to build your answer:
1: The ANSWER is contradicts the REFERENCE completely, adds additional claims, changes or omits details
2: The ANSWER points to the same topic but the details are omitted or changed completely comparing to REFERENCE
3: The ANSWER's references are not completely correct, but the details are somewhat close to the details mentioned in the REFERENCE. its ok, if there are added details in ANSWER comparing to REFERENCES.
4: The ANSWER is the same as the REFERENCE in all facts and details, even if worded differently. its ok, if there are added details in ANSWER comparing to REFERENCES. if there are sources available in REFERENCE, its exactly the same as ANSWER and is for sure mentioned in ANSWER
REFERENCE
===
{target_response}
===
ANSWER
===
{actual_response}
===
This prompt ensures that our LLM judge provides:
Start your free trial today and see results within days.
Our LLM as a Judge flow demonstrates sophisticated AI workflow design using FlowHunt’s visual flow builder. Here’s how the components work together:
The flow begins with a Chat Input component that receives the evaluation request containing both the actual response and the reference answer.
The Prompt Template component dynamically constructs the evaluation prompt by:
{target_response} placeholder{actual_response} placeholderThe Structured Output Generator processes the prompt using a selected LLM and generates structured output containing:
total_rating: Numerical score from 1-4correctness: Binary correct/incorrect classificationreasoning: Detailed explanation of the evaluationThe Parse Data component formats the structured output into a readable format, and the Chat Output component presents the final evaluation results.
The LLM as a Judge system provides several advanced capabilities that make it particularly effective for AI flow evaluation:
Unlike simple string matching, our LLM judge understands:
The 4-point rating scale provides granular evaluation:
Each evaluation includes detailed reasoning, making it possible to:
Get latest tips, trends, and deals for free.
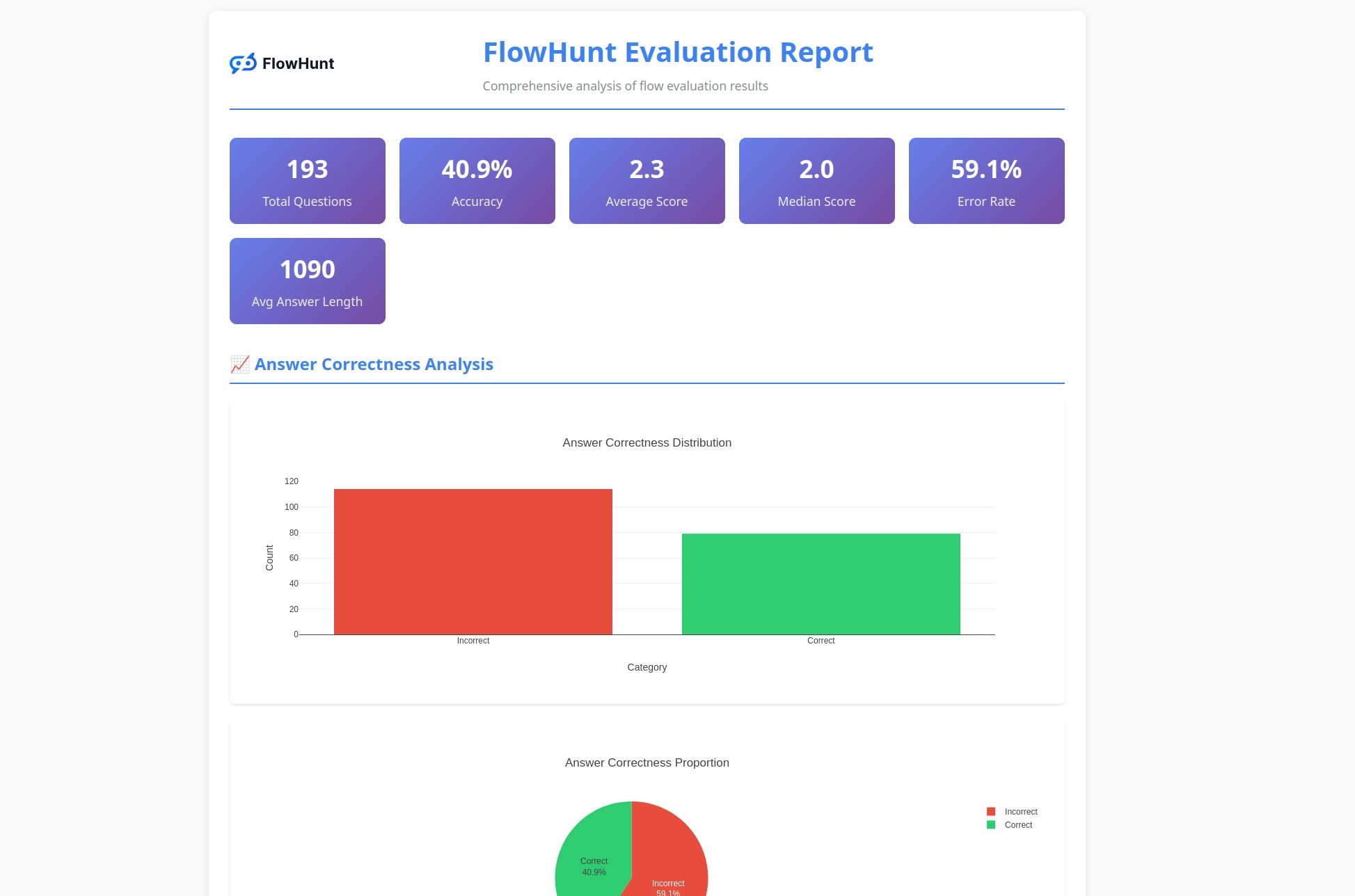
The CLI toolkit generates detailed reports that provide actionable insights into flow performance:
Ready to start evaluating your AI flows with professional-grade tools? Here’s how to get started:
One-Line Installation (Recommended) for macOS and Linux:
curl -sSL https://raw.githubusercontent.com/yasha-dev1/flowhunt-toolkit/main/install.sh | bash
This will automatically:
flowhunt command to your PATHManual Installation:
# Clone the repository
git clone https://github.com/yasha-dev1/flowhunt-toolkit.git
cd flowhunt-toolkit
# Install with pip
pip install -e .
Verify Installation:
flowhunt --help
flowhunt --version
1. Authentication First, authenticate with your FlowHunt API:
flowhunt auth
2. List Your Flows
flowhunt flows list
3. Evaluate a Flow Create a CSV file with your test data:
flow_input,expected_output
"What is 2+2?","4"
"What is the capital of France?","Paris"
Run evaluation with LLM as a Judge:
flowhunt evaluate your-flow-id path/to/test-data.csv --judge-flow-id your-judge-flow-id
4. Batch Execute Flows
flowhunt batch-run your-flow-id input.csv --output-dir results/
The evaluation system provides comprehensive analysis:
flowhunt evaluate FLOW_ID TEST_DATA.csv \
--judge-flow-id JUDGE_FLOW_ID \
--output-dir eval_results/ \
--batch-size 10 \
--verbose
Features include:
The CLI toolkit seamlessly integrates with the FlowHunt platform, allowing you to:
The release of our CLI toolkit represents more than just a new tool – it’s a vision for the future of AI development where:
Quality is Measurable: Advanced evaluation techniques make AI performance quantifiable and comparable.
Testing is Automated: Comprehensive testing frameworks reduce manual effort and improve reliability.
Transparency is Standard: Detailed reasoning and reporting make AI behavior understandable and debuggable.
Community Drives Innovation: Open-source tools enable collaborative improvement and knowledge sharing.
By open-sourcing the FlowHunt CLI Toolkit, we’re demonstrating our commitment to:
The FlowHunt CLI Toolkit with LLM as a Judge represents a significant advancement in AI flow evaluation capabilities. By combining sophisticated evaluation logic with comprehensive reporting and open-source accessibility, we’re empowering developers to build better, more reliable AI systems.
The meta-approach of using FlowHunt to evaluate FlowHunt flows demonstrates the maturity and flexibility of our platform while providing a powerful tool for the broader AI development community.
Whether you’re building simple chatbots or complex multi-agent systems, the FlowHunt CLI Toolkit provides the evaluation infrastructure you need to ensure quality, reliability, and continuous improvement.
Ready to elevate your AI flow evaluation? Visit our GitHub repository to get started with the FlowHunt CLI Toolkit today, and experience the power of LLM as a Judge for yourself.
The future of AI development is here – and it’s open source.
The FlowHunt CLI Toolkit is an open-source command-line tool for evaluating AI flows with comprehensive reporting capabilities. It includes features like LLM as a Judge evaluation, correct/incorrect result analysis, and detailed performance metrics.
LLM as a Judge uses a sophisticated AI flow built within FlowHunt to evaluate other flows. It compares actual responses against reference answers, providing ratings, correctness assessments, and detailed reasoning for each evaluation.
The FlowHunt CLI Toolkit is open-source and available on GitHub at https://github.com/yasha-dev1/flowhunt-toolkit. You can clone, contribute, and use it freely for your AI flow evaluation needs.
The toolkit generates comprehensive reports including correct/incorrect result breakdowns, LLM as a Judge evaluations with ratings and reasoning, performance metrics, and detailed analysis of flow behavior across different test cases.
Yes! The LLM as a Judge flow is built using FlowHunt's platform and can be adapted for various evaluation scenarios. You can modify the prompt template and evaluation criteria to suit your specific use cases.
Yasha is a talented software developer specializing in Python, Java, and machine learning. Yasha writes technical articles on AI, prompt engineering, and chatbot development.

Build and evaluate sophisticated AI workflows with FlowHunt's platform. Start creating flows that can judge other flows today.
Integrate FlowHunt with Patronus MCP Server to streamline LLM system optimization, evaluation, and experimentation. Standardize AI model testing, automate exper...

FlowHunt 2.6.12 introduces the Slack integration, intent classification, and Gemini model, enhancing AI chatbot functionality, customer insights, and team workf...

The GitHub MCP Server enables seamless integration between AI tools and GitHub, allowing automated workflows to manage repositories, issues, and pull requests d...