
Automated FAQ Generator from Web Search
This AI-powered workflow generates concise, high-quality FAQ answers for any given question by searching the web, extracting relevant content, and producing a c...
3 min read
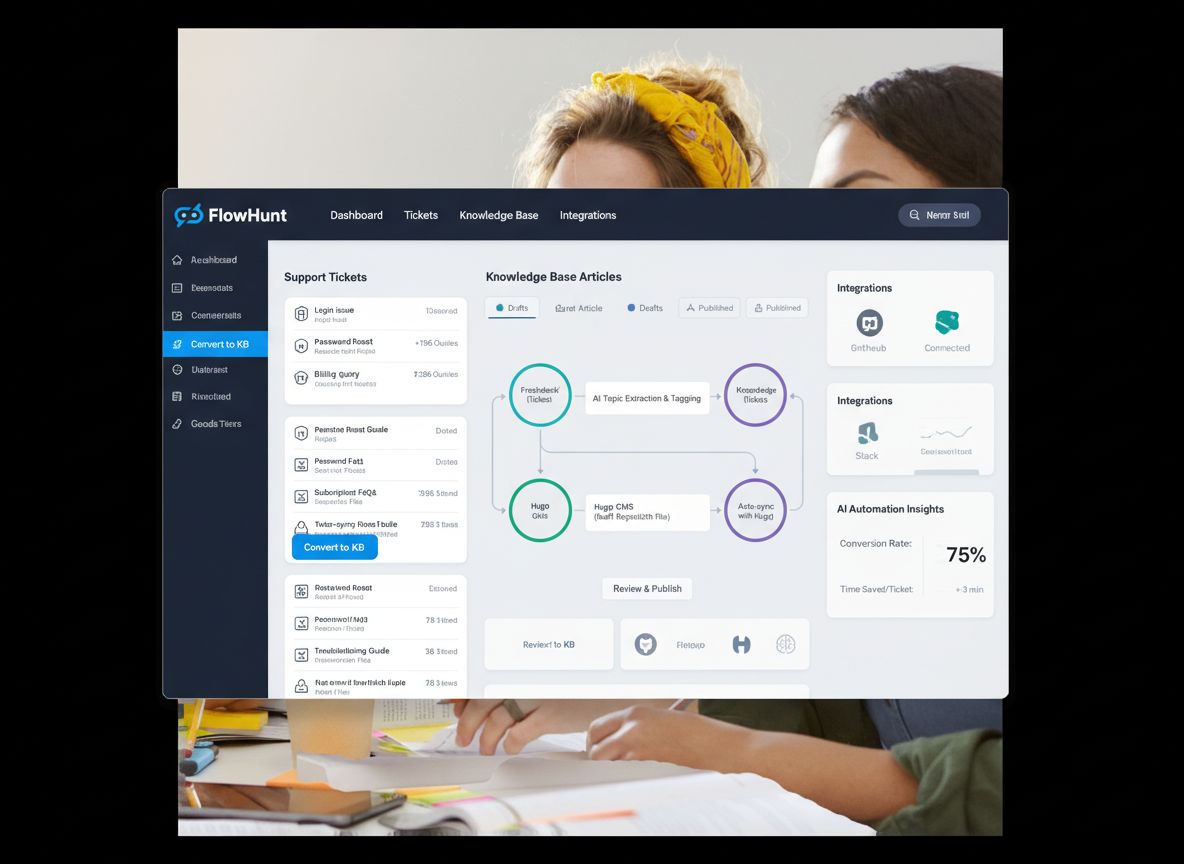
Learn how to automate the creation of knowledge base articles in Hugo directly from customer support tickets using AI agents and GitHub integration.
Customer support teams generate valuable insights every single day through their interactions with customers. These questions, concerns, and solutions represent a goldmine of information that could benefit your entire user base if properly documented. However, manually converting support tickets into polished knowledge base articles is time-consuming, repetitive, and often deprioritized in favor of immediate support demands. What if you could automate this entire process, transforming raw customer inquiries into professionally formatted, SEO-optimized knowledge base pages that appear directly on your website? This is exactly what modern automation workflows now make possible. By connecting your LiveAgent ticketing system with Hugo static site generation and GitHub version control, you can create a seamless pipeline that turns customer questions into searchable, discoverable knowledge base content automatically. In this comprehensive guide, we’ll explore how to build this powerful automation system, the technical architecture behind it, and the practical steps to implement it in your own organization.

A knowledge base is a centralized repository of information designed to help users find answers to common questions without requiring direct support intervention. Traditional knowledge bases are built manually—support teams write articles, format them, optimize them for search engines, and publish them through a content management system. This process is labor-intensive and creates a significant bottleneck, especially for growing companies that receive hundreds of support inquiries daily. Knowledge base automation changes this paradigm by using artificial intelligence to extract relevant information from support tickets, structure it according to predefined templates, and publish it directly to your website. The automation system acts as an intelligent intermediary between your support team and your website, identifying which tickets contain generalizable knowledge that would benefit other users, then transforming that raw support conversation into polished, professional documentation. This approach not only saves time but also ensures consistency in formatting, structure, and SEO optimization across all knowledge base articles. The system can be configured to understand your specific business context, avoid creating duplicate content, and maintain a coherent knowledge base that grows organically as your support team handles more inquiries.
Start your free trial today and see results within days.
The business case for knowledge base automation is compelling and multifaceted. First, it dramatically reduces support volume by enabling customers to find answers independently. Studies consistently show that customers prefer self-service options when they’re available and effective, and a well-maintained knowledge base can reduce support tickets by 20-30%. Second, it improves customer satisfaction by providing instant answers to common questions without requiring customers to wait for a support response. Third, it creates significant SEO benefits—knowledge base articles are indexed by search engines and can drive organic traffic to your website, improving your visibility and attracting new customers who discover your content through search. Fourth, it captures institutional knowledge that might otherwise be lost when team members leave the organization. Every support interaction contains valuable context and solutions that, when documented, become part of your company’s permanent knowledge repository. Fifth, it enables your support team to focus on complex, high-value issues rather than repeatedly answering the same questions. When you automate the creation of knowledge base content from support tickets, you’re essentially creating a force multiplier for your support organization. The time your team spends answering questions becomes documented knowledge that serves thousands of future customers. Finally, it provides valuable data about what your customers are struggling with, which can inform product development, marketing messaging, and customer education initiatives.
Building an automated knowledge base system requires integrating multiple tools and platforms into a cohesive workflow. The system typically consists of four main components: a ticketing system (LiveAgent), an AI agent that processes tickets, a version control system (GitHub), and a static site generator (Hugo). LiveAgent serves as the source of truth for customer inquiries, storing all support conversations with metadata like tags, categories, and timestamps. The AI agent is the orchestrator of the entire process—it receives a ticket ID, retrieves the full ticket content and conversation history, analyzes the content to determine if it’s suitable for knowledge base publication, checks existing knowledge to avoid duplicates, generates SEO-optimized content in the proper format, and manages the GitHub workflow. GitHub acts as the content management and version control layer, allowing for review, approval, and tracking of all knowledge base changes. Hugo, a static site generator, transforms the markdown files stored in GitHub into a fast, secure, and SEO-friendly website. This architecture creates a clear separation of concerns: LiveAgent handles support, the AI agent handles intelligence and decision-making, GitHub handles version control and collaboration, and Hugo handles presentation. The beauty of this system is that each component can be independently maintained and upgraded without disrupting the others.
Get latest tips, trends, and deals for free.
FlowHunt provides the orchestration layer that ties all these systems together into a seamless workflow. Rather than requiring custom development or complex integrations, FlowHunt allows you to visually design the automation flow, connecting LiveAgent, GitHub, and Hugo through a simple, intuitive interface. The platform handles authentication, error handling, retry logic, and all the technical complexity that would otherwise require significant engineering effort. With FlowHunt, you can create sophisticated automation workflows without writing code, making knowledge base automation accessible to teams without dedicated development resources. The platform also provides memory and context management, allowing your automation to learn from previous executions and make intelligent decisions about when to create new articles versus updating existing ones. FlowHunt’s integration with GitHub enables automatic pull request creation, allowing your team to review generated content before it goes live. This human-in-the-loop approach ensures quality while still capturing the efficiency benefits of automation.
The automated knowledge base generation workflow follows a carefully designed sequence of steps, each building on the previous one to create a complete, production-ready knowledge base article. Understanding this process is essential for implementing it effectively in your organization.
Step One: Ticket Retrieval and Validation
The workflow begins when you provide a ticket ID from your LiveAgent system. The AI agent immediately retrieves the complete ticket content, including the subject line, body text, all tags, and the full conversation history between the customer and support team. This comprehensive retrieval is crucial because it ensures the AI has all necessary context to generate accurate, relevant content. The agent also validates that the ticket contains sufficient information and is appropriate for knowledge base publication. For example, if your organization receives many demo scheduling requests, you can configure the system to automatically skip these tickets since they don’t represent generalizable knowledge that would benefit other users. This filtering step prevents your knowledge base from becoming cluttered with administrative or transactional content that doesn’t provide value to your user base.
Step Two: Duplicate Detection Using Memory
Before generating new content, the system checks its memory to determine whether a similar knowledge base article has already been created. This memory system is one of the most important features of the automation, as it prevents the creation of duplicate or near-duplicate articles that would confuse users and dilute your SEO efforts. The AI agent searches through previous tickets and generated articles to find similar topics. If it finds a match, it can either update the existing article with new information or skip creation entirely, depending on your configuration. If no similar topic exists, the agent adds this ticket to its memory, creating a record that will be referenced for all future tickets. This memory-based approach means that the system becomes smarter over time—as you process more tickets, the system builds a comprehensive map of your knowledge base and can make increasingly intelligent decisions about content creation and updates.
Step Three: Knowledge Base Structure Analysis
The system then examines your existing knowledge base repository to understand how content is structured, formatted, and organized. This step is critical for ensuring consistency across all articles. The AI agent analyzes existing markdown files, frontmatter formats, heading structures, and content patterns to understand your knowledge base’s conventions. It looks at how articles are categorized, what metadata is included, how images are referenced, and what SEO elements are present. By analyzing your existing content, the system learns your specific style and structure requirements, ensuring that newly generated articles seamlessly integrate with your existing knowledge base rather than standing out as obviously automated content.
Step Four: GitHub Branch Management
To maintain clean version control and enable proper review workflows, the system creates or uses an existing GitHub branch for the knowledge base update. Rather than creating a new branch for every single ticket, the system intelligently manages branches to keep your repository organized. If a branch already exists for knowledge base updates, the system uses that branch and adds the new file to it. This approach prevents branch proliferation while maintaining the ability to batch multiple knowledge base updates into a single pull request for review. The branch naming convention is typically descriptive, such as “knowledge-base-updates” or “kb-automation,” making it easy for team members to understand the purpose of the branch.
Step Five: Content Generation and Formatting
With all the context gathered, the AI agent generates the knowledge base article. The generated content includes a properly formatted frontmatter section with metadata like title, description, keywords, tags, categories, publication date, and call-to-action elements. The article body follows a structured format designed for both user readability and search engine optimization. Typically, this includes a main headline, several H2 sections with question-based headings (such as “What is this?”, “Why should we do this?”, and “How should we do this?”), and detailed answers formatted as paragraphs and bullet points. This structure is optimized for featured snippets and other search engine features that reward clear, question-answer formatting. The content is written in markdown format, which is the standard for Hugo and most static site generators, ensuring compatibility and easy editing.
Step Six: File Creation and Commit
The system creates a new markdown file in your knowledge base folder with an appropriate filename based on the article topic. The filename is typically slugified (lowercase, hyphens instead of spaces) to follow web standards. The file includes the complete frontmatter and body content generated in the previous step. Once the file is created, the system commits the changes to the GitHub branch with a descriptive commit message that references the original ticket ID. This commit message creates a permanent record linking the knowledge base article back to the original customer inquiry, enabling traceability and context for future reference.
Step Seven: Pull Request Creation and Review
Finally, the system creates a pull request from the knowledge base branch to your main branch. This pull request includes a description of the changes, the ticket ID that prompted the creation, and any relevant context. The pull request serves as a checkpoint where your team can review the generated content, make any necessary edits, verify that the article meets your quality standards, and ensure it aligns with your knowledge base strategy. This human review step is crucial—while AI-generated content is generally high quality, human oversight ensures accuracy, brand consistency, and appropriateness. Once your team approves the pull request, it can be merged into the main branch, triggering Hugo to rebuild your website and publish the new article.
To use this automation workflow, you need to identify the correct ticket ID from your LiveAgent system. LiveAgent displays ticket IDs in two convenient locations. First, within the LiveAgent interface itself, you’ll see a “Ticket” label with the ID displayed prominently. You can copy this ID directly from the interface. Second, and often more convenient, you can find the ticket ID in the URL of the ticket page. When you open a ticket in LiveAgent, the URL will contain a parameter like “ID=12345” at the end. This ID is exactly what you need to provide to the automation workflow. Once you have the ticket ID, you simply input it into the FlowHunt workflow, and the entire process begins automatically. The system retrieves the ticket, analyzes it, checks for duplicates, generates the article, creates the GitHub branch and pull request, and notifies your team for review. The entire process typically completes in seconds to minutes, depending on the complexity of the ticket and the size of your existing knowledge base.
Experience how FlowHunt automates your knowledge base creation from support tickets — from ticket analysis and content generation to GitHub integration and Hugo publishing — all in one seamless workflow.
Once you have the basic workflow in place, there are several advanced configurations that can optimize the system for your specific needs. You can configure the system to ignore certain ticket types based on tags, categories, or keywords. For example, you might want to skip all tickets tagged as “billing” or “account-specific” since these typically don’t represent generalizable knowledge. You can also set thresholds for article quality or length—if a ticket is too short or lacks sufficient detail, the system can skip it and wait for more comprehensive information. The memory system can be configured to use different matching algorithms, from simple keyword matching to sophisticated semantic similarity analysis. You can also customize the frontmatter and content structure to match your specific requirements, adding custom fields or modifying the article format. Some organizations add additional metadata like difficulty level, target audience, or related articles. You can also configure the system to automatically add images to articles by generating them with AI or pulling them from your asset library. The system can be set to create articles in multiple languages if you serve an international audience. You can also configure notifications and approvals—for example, requiring specific team members to approve articles in certain categories before they’re published.
Consider a practical example from the workflow in action. A customer submits a support ticket asking about a WordPress integration error they’re experiencing. The ticket includes error messages, screenshots, and a detailed description of what they’ve tried. The support team responds with troubleshooting steps and eventually resolves the issue. This ticket is now a perfect candidate for knowledge base automation. When the ticket ID is provided to the workflow, the system retrieves the complete conversation, analyzes it, and checks its memory. Since no previous article about WordPress integration errors exists, the system adds this topic to memory and proceeds with article generation. The system examines your existing knowledge base and discovers that you have a specific format for technical troubleshooting articles, with sections for symptoms, causes, solutions, and prevention. The generated article follows this format, creating a comprehensive guide to WordPress integration errors that will help future customers solve the same problem independently. The article is created in a GitHub branch, a pull request is generated, your team reviews it, makes any necessary adjustments, and merges it. Within minutes, the article is live on your website, indexed by search engines, and available to help customers. The next time someone searches for “WordPress integration error” or encounters this issue, they’ll find your knowledge base article and solve their problem without contacting support.
To justify the investment in knowledge base automation, it’s important to measure its impact. Key metrics include the reduction in support ticket volume for questions covered by knowledge base articles, the increase in organic traffic from search engines, the time saved by your support team, and the improvement in customer satisfaction scores. You can track how many customers access knowledge base articles before contacting support, how many support tickets reference knowledge base articles, and how many customers report that they found the answer they needed in their knowledge base. You can also measure the quality of generated articles by tracking user engagement metrics like time on page, scroll depth, and bounce rate. Articles that users find valuable will have higher engagement metrics. You can also track the number of articles generated, the time saved compared to manual creation, and the cost savings from reduced support volume. Most organizations find that knowledge base automation pays for itself within the first few months through reduced support costs and improved customer satisfaction.
Automating knowledge base creation from LiveAgent tickets represents a significant opportunity to improve customer support efficiency, enhance your website’s SEO performance, and create a valuable resource that serves your customers long after the initial support interaction. By connecting LiveAgent, GitHub, Hugo, and AI-powered automation through FlowHunt, you create a system that transforms raw customer inquiries into polished, professional knowledge base articles automatically. The workflow is straightforward—provide a ticket ID, and the system handles everything from content generation to GitHub integration to pull request creation. The memory system ensures you don’t create duplicate content, while the human review step maintains quality and brand consistency. As your knowledge base grows, it becomes an increasingly valuable asset that reduces support costs, improves customer satisfaction, and drives organic traffic to your website. The implementation is accessible to teams without deep technical expertise, making this powerful automation available to organizations of all sizes.
A LiveAgent ticket is a customer support request or inquiry logged in the LiveAgent ticketing system. Each ticket contains a subject, body, tags, and full conversation history that can be used to generate knowledge base content.
You can find your ticket ID in two ways: (1) Look for the 'Ticket' label with the ID displayed in the LiveAgent interface, or (2) Check the URL at the end where it shows 'ID=your-ticket-id'. Copy this ID to use in the automation flow.
Yes, the flow can be configured to ignore specific ticket types. For example, you can set it to skip demo scheduling requests to avoid creating duplicate knowledge base pages for similar topics.
The flow uses memory to check if a similar topic has been processed before. If it finds a match, it will update the existing article if needed or skip creation to avoid duplicates.
The flow creates or uses an existing GitHub branch, generates a markdown file with proper frontmatter, commits the changes, and creates a pull request for review before merging to the main branch.
Arshia is an AI Workflow Engineer at FlowHunt. With a background in computer science and a passion for AI, he specializes in creating efficient workflows that integrate AI tools into everyday tasks, enhancing productivity and creativity.

Transform customer support tickets into SEO-optimized knowledge base articles automatically with FlowHunt's AI-powered workflows.
This AI-powered workflow generates concise, high-quality FAQ answers for any given question by searching the web, extracting relevant content, and producing a c...

Learn how to integrate FlowHunt AI flows with LiveAgent to automatically respond to customer tickets using intelligent automation rules and API integration.