Make LLMs to fact-check their responses and include sources
Discover how to build chatbots with Retrieval Interleaved Generation (RIG) to ensure AI responses are accurate, fact-checked, and include verifiable sources.
AI
Chatbot
Fact-Checking
RIG
RAG
Knowledge Retrieval
Machine Learning
Retrieval Interleaved Generation, or RIG for short, is a cutting-edge AI method that smoothly combines finding information and creating answers. In the past, AI models used RAG (Retrieval Augmented Generation) or generation, but RIG merges these processes to enhance AI accuracy. By weaving together retrieval and generation, AI systems can tap into a wider base of knowledge, offering more precise and relevant responses. The main aim of RIG is to reduce mistakes and improve the trustworthiness of AI outputs, making it an essential tool for developers who want to fine-tune AI accuracy. Thus, Retrieval Interleaved Generation comes as an alternative to RAG (Retrieval Augmented Generation) for generating AI-powered answers based on a context.
How does RIG (Retrieval Interleaved Generation) work?
Here is how RIG works. The following stages are inspired by the original blog](https://research.google/blog/grounding-ai-in-reality-with-a-little-help-from-data-commons/
“Explore Google’s DataGemma models, connecting AI to real-world data for factual, reliable responses. Join us in shaping trustworthy AI!”), which focuses more on general use cases using the Data Commons API. However, in most use cases, you may want to use both a general [knowledge base (e.g., Wikipedia or Data Commons) and your own data. Here’s how you can use the power of flows in FlowHunt to make a RIG chatbot from your own knowledge base and a general knowledge base like Wikipedia.
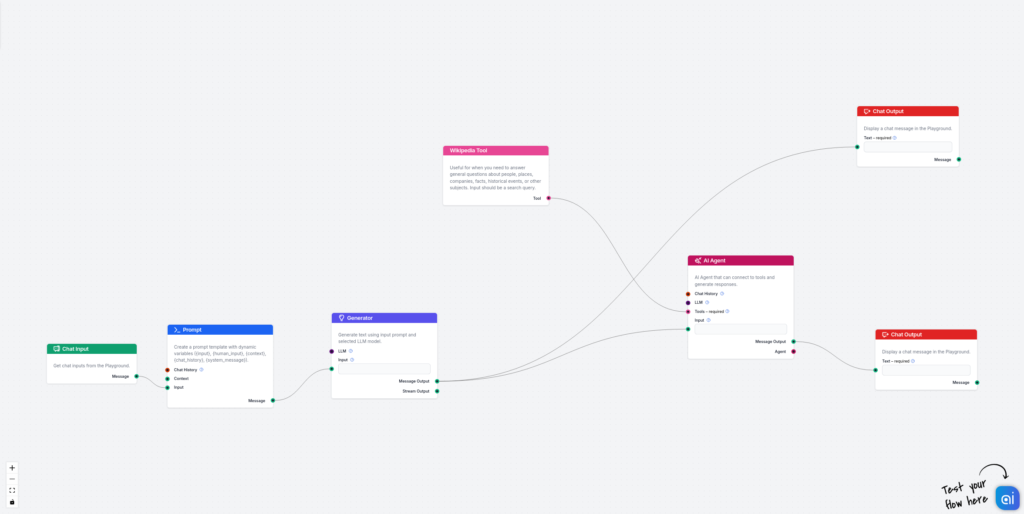
A user query is fed to a generator, which generates a sample answer with a citation of corresponding sections. In this stage, the generator might even produce a good answer but hallucinated with wrong data and statistics.
In the next phase, we use an AI Agent which receives this output and refines the data in each section by connecting to Wikipedia and, additionally, adds sources for each corresponding section.
As you can see, this method enhances chatbot accuracy significantly and ensures each generated section has a source and is grounded in truth.
Ready to grow your business?
Start your free trial today and see results within days.
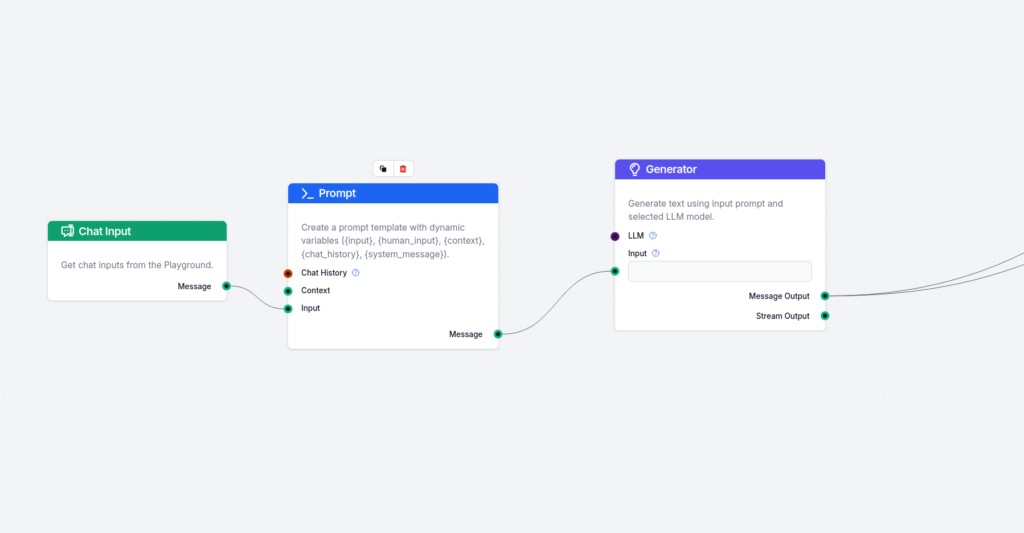
Add the First Stage (Dumb Sample Answer Generator):
The first part of the flow consists of Chat input, a prompt template, and a generator. Simply connect them together. The most important part is the prompt template. I have used the following:
Gived is user’s query. Based on the User’s query generate best possible answer with fake data or percentage. After each of different sections of your answer, include data which source to use in order to fetch the correct data and refine that section with correct data. You can either specify to choose Internal knowledge source to fetch data from in case there is custom data to user’s product or service or use Wikipedia to use as general knowledge source.
Join our newsletter
Get latest tips, trends, and deals for free.
Example Input: Which countries are top in terms of renewable energy and what is the best metric for measuring this and what is that measure for top country? Example output: The top countries in renewable energy are Norway, Sweden, Portugal, USA [Search in Wikipedia with query “Top Countries in renewable Energy”], the usual metric for renewable energy is Capacity factor [Search in Wikipedia with query “metric for renewable energy”], and number one country has 20% capacity factor [search in Wikipedia “biggest capacity factor”]
Let’s begin now! User Input: {input}
Here, we use Few Shot prompting to make the generator output exactly the format we want.
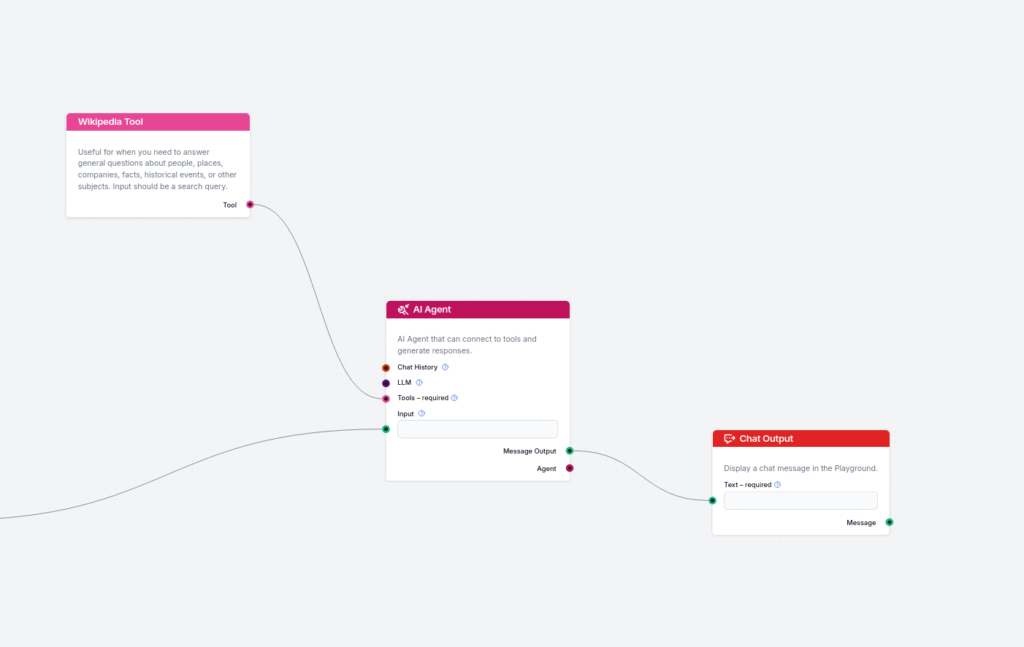
Add the Fact-Check Part:
Now, add the second part, which fact-checks the sample answer output and refines the answer based on real sources of truth. Here, we use Wikipedia and AI Agents, since it’s easier and more flexible to connect Wikipedia to AI Agents than to simple Generators. Connect the output of the generator to the AI Agent and connect the Wikipedia tool to the AI Agent. Here is the Goal I use for the AI Agent:
You are given a sample answer to user’s question. The sample answer might include wrong data. Use Wikipedia tool in the given sections with the specified query to use Wikipedia’s information to refine the answer. Include the link of Wikipedia in each of the sections specified. FETCH DATA FROM YOUR TOOLS AND REFINE THE ANSWER IN THAT SECTION. ADD THE LINK TO THE SOURCE IN THAT PARTICULAR SECTION AND NOT IN THE END.
Similarly, you can add Document Retriever to the AI Agent, which can connect to your own custom knowledge base to retrieve documents.
To truly appreciate RIG, it helps to first look at its predecessor, Retrieval-Augmented Generation (RAG). RAG merges the strengths of systems that fetch relevant data and models that generate coherent and suitable content. The shift from RAG to RIG is a big step forward. RIG not only retrieves and generates, but it also mixes these processes for better accuracy and efficiency. This allows AI systems to improve their understanding and output in a step-by-step manner, delivering results that are not only accurate but also relevant and insightful. By blending retrieval with generation, AI systems can draw on vast amounts of information while keeping their responses coherent and relevant.
The Future of Retrieval Interleaved Generation
The future of Retrieval Interleaved Generation looks promising, with many advancements and research directions on the horizon. As AI continues to grow, RIG is set to play a key role in shaping the world of machine learning and AI applications. Its potential impact goes beyond current capabilities, promising to transform how AI systems process and generate information. With ongoing research, we expect further innovations that will enhance the integration of RIG into various AI frameworks, leading to more efficient, accurate, and reliable AI systems. As these developments unfold, the importance of RIG will only increase, cementing its role as a cornerstone of AI accuracy and performance.
In conclusion, Retrieval Interleaved Generation marks a major step forward in the quest for AI accuracy and efficiency. By skillfully blending retrieval and generation processes, RIG enhances the performance of Large Language Models, improves multi-step reasoning, and offers exciting possibilities in education and fact-checking. Looking ahead, the ongoing evolution of RIG will undoubtedly drive new innovations in AI, solidifying its role as a vital tool in the pursuit of smarter, more reliable artificial intelligence systems.
Frequently asked questions
RIG is an AI method that combines information retrieval and answer generation, allowing chatbots to fact-check their own responses and provide source-backed, accurate outputs.
RIG weaves together retrieval and generation steps, using tools like Wikipedia or your custom data, so each answer section is grounded in reliable sources and verified for accuracy.
With FlowHunt, you can design a RIG chatbot by connecting prompt templates, generators, and AI Agents to both internal and external knowledge sources, enabling automatic fact-checking and source citation.
While RAG (Retrieval Augmented Generation) retrieves information and then generates answers, RIG interleaves these steps for each section, resulting in higher accuracy and more reliable, sourced responses.
Yasha is a talented software developer specializing in Python, Java, and machine learning. Yasha writes technical articles on AI, prompt engineering, and chatbot development.
Yasha Boroumand
CTO, FlowHunt
Ready to build your own AI?
Start building smart chatbots and AI tools with FlowHunt’s intuitive, no-code platform. Connect blocks and automate your ideas with ease.
RIG Wikipedia Assistant Chatbot (Retrieval Interleaved Generator)
Discover the RIG Wikipedia Assistant, a tool designed for precise information retrieval from Wikipedia. Ideal for research and content creation, it provides wel...
Retrieval Augmented Generation (RAG) is an advanced AI framework that combines traditional information retrieval systems with generative large language models (...
RAG AI: The Definitive Guide to Retrieval-Augmented Generation and Agentic Workflows
Discover how Retrieval-Augmented Generation (RAG) is transforming enterprise AI, from core principles to advanced Agentic architectures like FlowHunt. Learn how...
7 min read
RAG
Agentic RAG
+2
Cookie Consent We use cookies to enhance your browsing experience and analyze our traffic. See our privacy policy.