OpenAI just released a new model called OpenAI O1 from the O1 series of models. The main architectural change in these models is the ability to think before answering a user’s query. In this blog, we’ll dive deep into the key changes in OpenAI O1, the new paradigms these models use, and how this model can significantly increase RAG accuracy. We’ll compare a simple RAG flow using OpenAI GPT4o and OpenAI O1 model.
How is OpenAI O1 different than previous models?
Large-Scale Reinforcement Learning
The O1 model leverages large-scale reinforcement learning algorithms during its training process. This enables the model to develop a robust “Chain of Thought,” allowing it to think more deeply and strategically about problems. By continuously optimizing its reasoning pathways through reinforcement learning, the O1 model significantly improves its ability to analyze and solve complex tasks efficiently.
Chain of Thought Integration
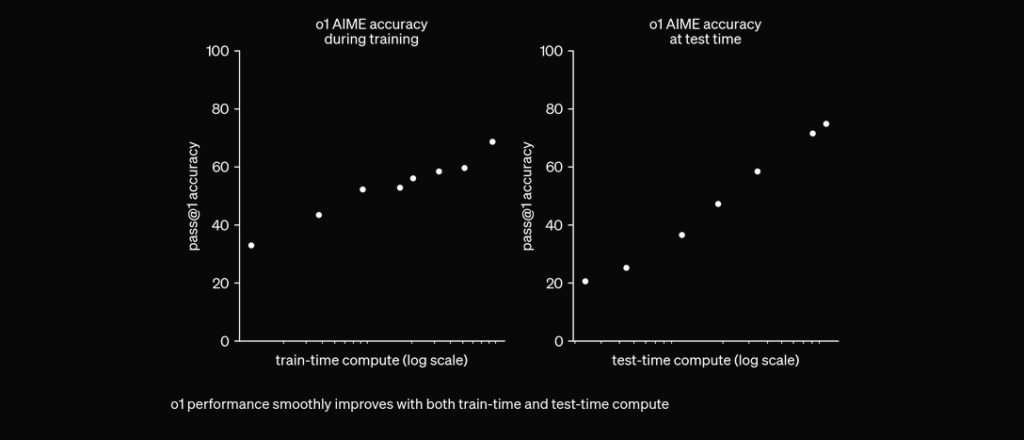
Previously, chain of thought has proven to be a useful prompt engineering mechanism to make LLM “think” by itself and answer complex questions in a step-by-step plan. With O1 models, this step comes out of the box and is integrated natively into the model at inference time, making it useful for mathematical and coding problem-solving tasks.
O1 is trained with RL to “think” before responding via a private chain of thought. The longer it thinks, the better it does on reasoning tasks. This opens up a new dimension for scaling. We’re no longer bottlenecked by pretraining. We can now scale inference compute too. pic.twitter.com/niqRO9hhg1
— Noam Brown (@polynoamial) September 12, 2024
Superior Benchmark Performance
In extensive evaluations, the O1 model has demonstrated remarkable performance across various benchmarks:
- AIME (American Invitational Mathematics Examination): Solves 83% of problems correctly, a substantial improvement over GPT-4o’s 13%.
- GPQA (Expert-Level Test in Sciences): Surpasses PhD-level experts, marking the first AI model to outperform humans on this benchmark.
- MMLU (Multi-Task Language Understanding): Excels in 54 out of 57 subcategories, achieving 78.2% performance with visual perception enabled.
- Coding Competitions: Achieves high rankings in platforms like Codeforces, outperforming 93% of human competitors.
OpenAI O1 vs OpenAI GPT4o in RAG Flow
To test the performance accuracy of OpenAI O1 and GPT4o, we created two identical flows, but with two different LLMs. We’ll compare the question-answering capability of the models on two sources indexed regarding the technical report of OpenAI O1.
First, we’ll make a simple RAG flow in FlowHunt. It consists of Chat Input, Document Retriever (fetches relevant documents), Prompt, Generator, and Chat Output. The LLM OpenAI component is added to specify the model (otherwise, GPT4o is used by default).
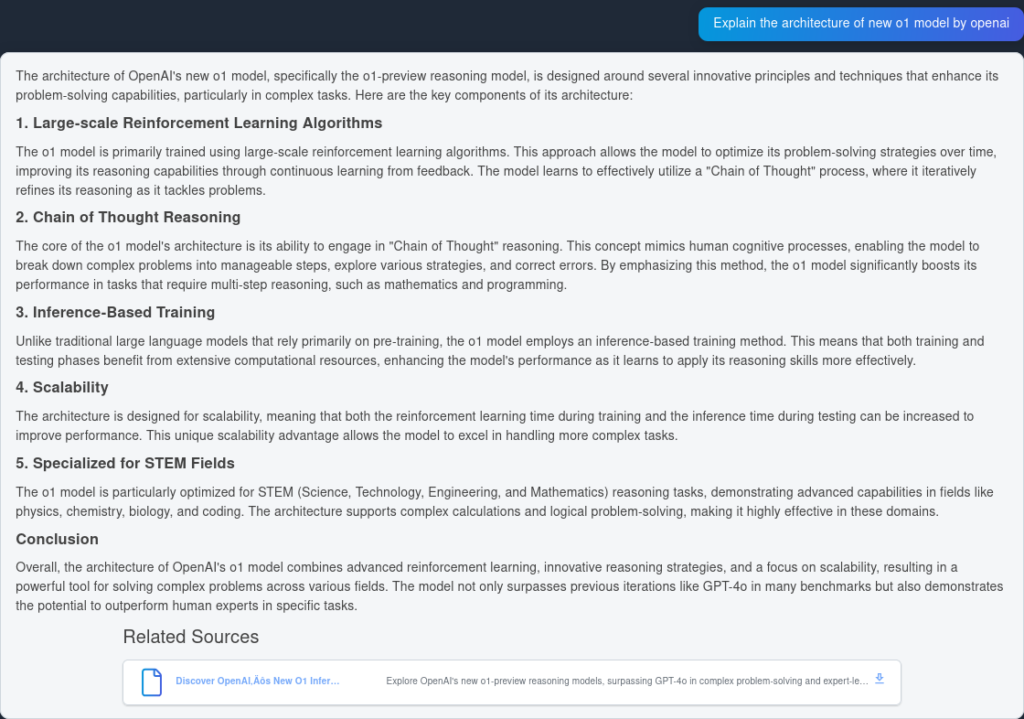
Here is the response from GPT4o:
And here is the result from OpenAI O1:
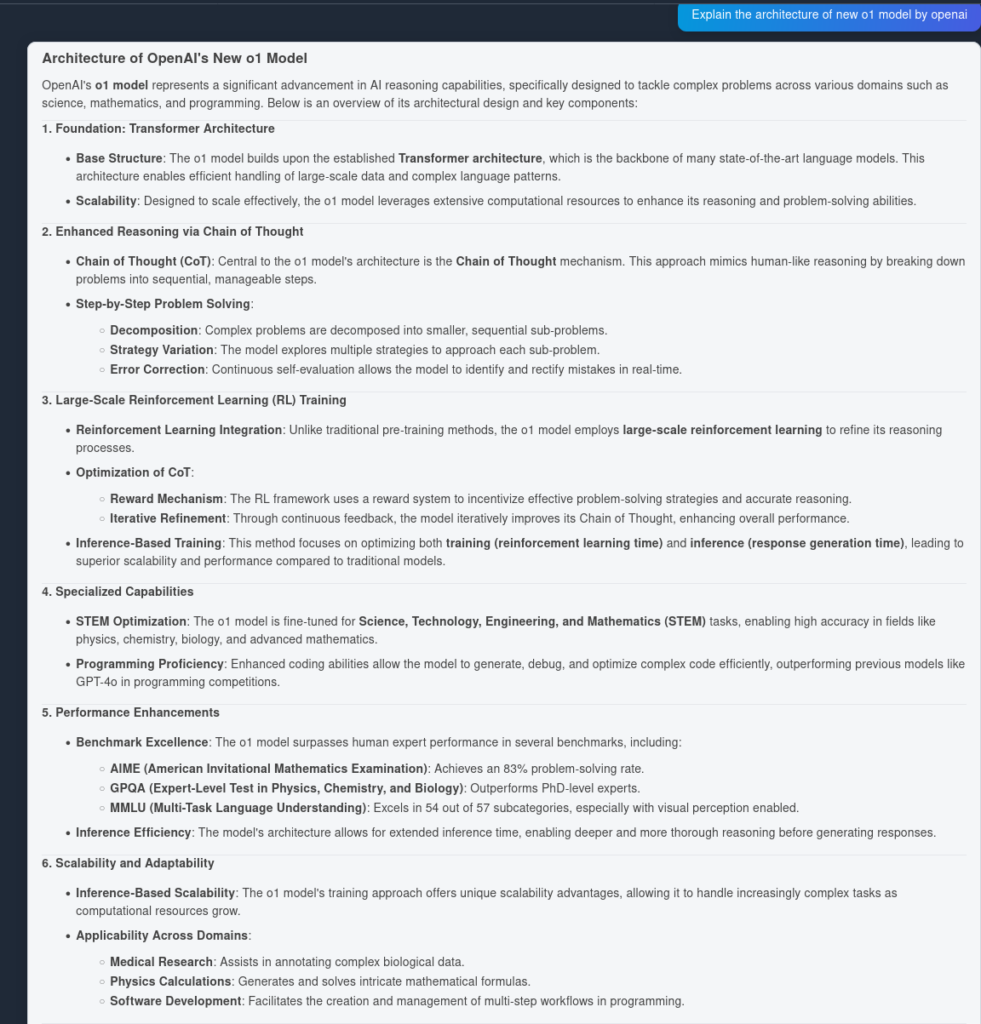
As you can see, OpenAI O1 captured more architectural advantages from the article itself—6 points as opposed to 4. In addition, O1 makes logical implications from each point, enriching the document with more insights as to why the architectural change is useful.
Does OpenAI O1 Model Worth It?
From our experiments, the O1 model would cost more for increased accuracy. The new model has 3 types of tokens: Prompt Token, Completion Token, and Reason Token (a newly added type of token), making it potentially more expensive. In most cases, OpenAI O1 provides answers that seem more helpful if grounded by truth. However, there are some instances where GPT4o outperforms OpenAI O1—some tasks simply don’t need reasoning.
Frequently asked questions
- How is OpenAI O1 different from GPT4o?
OpenAI O1 uses large-scale reinforcement learning and integrates chain of thought reasoning at inference time, enabling deeper, more strategic problem-solving than GPT4o.
- Does OpenAI O1 outperform GPT4o in benchmarks?
Yes, O1 achieves higher scores in benchmarks like AIME (83% vs. GPT4o's 13%), GPQA (surpassing PhD-level experts), and MMLU, excelling in 54 of 57 categories.
- Is OpenAI O1 always better than GPT4o?
Not always. While O1 excels in reasoning-heavy tasks, GPT4o can outperform it in simpler use cases that don't require advanced reasoning.
- What are the new token types in OpenAI O1?
O1 introduces a new 'Reason' token in addition to Prompt and Completion tokens, enabling more sophisticated reasoning but potentially increasing operational cost.
- How can I leverage OpenAI O1 for my projects?
You can use platforms like FlowHunt to build RAG flows and AI agents with OpenAI O1 for tasks requiring advanced reasoning and accurate document retrieval.
Yasha is a talented software developer specializing in Python, Java, and machine learning. Yasha writes technical articles on AI, prompt engineering, and chatbot development.

Yasha Boroumand
CTO, FlowHunt
Build Advanced RAG Flows with FlowHunt
Try FlowHunt to leverage the latest LLMs like OpenAI O1 and GPT4o for superior reasoning and retrieval-augmented generation.
Learn more