Wan 2.1: The Open-Source AI Video Generation Revolution
Wan 2.1 is a powerful open-source AI video generation model by Alibaba, delivering studio-quality videos from text or images, free for everyone to use locally.
AI Video Generation
Open Source
Wan 2.1
Alibaba
Generative AI
Video AI
AI Tools
Wan 2.1 (also called WanX 2.1) is breaking new ground as a fully open-source AI video generation model developed by Alibaba’s Tongyi Lab. Unlike many proprietary video generation systems that require expensive subscriptions or API access, Wan 2.1 delivers comparable or superior quality while remaining completely free and accessible to developers, researchers, and creative professionals.
What makes Wan 2.1 truly special is its combination of accessibility and performance. The smaller T2V-1.3B variant requires only ~8.2 GB of GPU memory, making it compatible with most modern consumer GPUs. Meanwhile, the larger 14B parameter version delivers state-of-the-art performance that outperforms both open-source alternatives and many commercial models on standard benchmarks.
Key Features That Set Wan 2.1 Apart
Multi-Task Support
Wan 2.1 isn’t just limited to text-to-video generation. Its versatile architecture supports:
Text-to-video (T2V)
Image-to-video (I2V)
Video-to-video editing
Text-to-image generation
Video-to-audio generation
This flexibility means you can start with a text prompt, a still image, or even an existing video and transform it according to your creative vision.
Multilingual Text Generation
As the first video model capable of rendering readable English and Chinese text within generated videos, Wan 2.1 opens new possibilities for international content creators. This feature is particularly valuable for creating captions or scene text in multi-language videos.
Revolutionary Video VAE (Wan-VAE)
At the heart of Wan 2.1’s efficiency is its 3D causal Video Variational Autoencoder. This technological breakthrough efficiently compresses spatiotemporal information, allowing the model to:
Compress videos by hundreds of times in size
Preserve motion and detail fidelity
Support high-resolution outputs up to 1080p
Exceptional Efficiency and Accessibility
The smaller 1.3B model requires only 8.19 GB of VRAM and can produce a 5-second, 480p video in roughly 4 minutes on an RTX 4090. Despite this efficiency, its quality rivals or exceeds that of much larger models, making it the perfect balance of speed and visual fidelity.
Industry-Leading Benchmarks & Quality
In public evaluations, Wan 14B achieved the highest overall score in the Wan-Bench tests, outperforming competitors in:
Motion quality
Stability
Prompt-following accuracy
Ready to grow your business?
Start your free trial today and see results within days.
How Wan 2.1 Compares to Other Video Generation Models
Unlike closed-source systems such as OpenAI’s Sora or Runway’s Gen-2, Wan 2.1 is freely available to run locally. It generally surpasses earlier open-source models (like CogVideo, MAKE-A-VIDEO, and Pika) and even many commercial solutions on quality benchmarks.
A recent industry survey noted that “among many AI video models, Wan 2.1 and Sora stand out” – Wan 2.1 for its openness and efficiency, and Sora for its proprietary innovation. In community tests, users have reported that Wan 2.1’s image-to-video capability outperforms competitors in clarity and cinematic feel.
The Technology Behind Wan 2.1
Wan 2.1 builds on a diffusion-transformer backbone with a novel spatio-temporal VAE. Here’s how it works:
An input (text and/or image/video) is encoded into a latent video representation by Wan-VAE
A diffusion transformer (based on the DiT architecture) iteratively denoises that latent
The process is guided by the text encoder (a multilingual T5 variant called umT5)
Finally, the Wan-VAE decoder reconstructs the output video frames
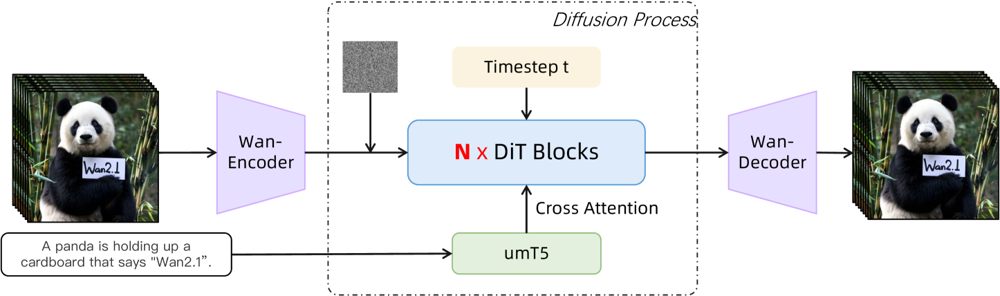
Figure: Wan 2.1’s high-level architecture (text-to-video case). A video (or image) is first encoded by the Wan-VAE encoder into a latent. This latent is then passed through N diffusion transformer blocks, which attend to the text embedding (from umT5) via cross-attention. Finally, the Wan-VAE decoder reconstructs the video frames. This design – featuring a “3D causal VAE encoder/decoder surrounding a diffusion transformer” (ar5iv.org
) – allows efficient compression of spatiotemporal data and supports high-quality video output.
This innovative architecture—featuring a “3D causal VAE encoder/decoder surrounding a diffusion transformer”—allows efficient compression of spatiotemporal data and supports high-quality video output.
The Wan-VAE is specially designed for videos. It compresses the input by impressive factors (temporal 4× and spatial 8×) into a compact latent before decoding it back to full video. Using 3D convolutions and causal (time-preserving) layers ensures coherent motion throughout the generated content.
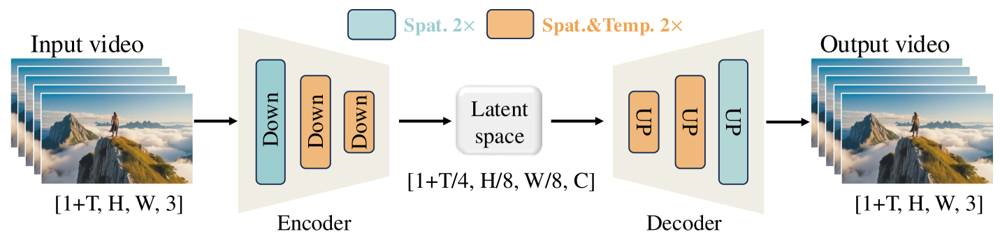
Figure: Wan 2.1’s Wan-VAE framework (encoder-decoder). The Wan-VAE encoder (left) applies a series of down-sampling layers (“Down”) to the input video (shape [1+T, H, W, 3] frames) until it reaches a compact latent ([1+T/4, H/8, W/8, C]). The Wan-VAE decoder (right) symmetrically upsamples (“UP”) this latent back to the original video frames. Blue blocks indicate spatial compression, and orange blocks indicate combined spatial+temporal compression (ar5iv.org
). By compressing the video by 256× (in spatiotemporal volume), Wan-VAE makes high-resolution video modeling tractable for the subsequent diffusion model.
Join our newsletter
Get latest tips, trends, and deals for free.
How to Run Wan 2.1 on Your Own Computer
Ready to try Wan 2.1 yourself? Here’s how to get started:
System Requirements
Python 3.8+
PyTorch ≥2.4.0 with CUDA support
NVIDIA GPU (8GB+ VRAM for 1.3B model, 16-24GB for 14B models)
Additional libraries from the repository
Installation Steps
Clone the repository and install dependencies:
git clone https://github.com/Wan-Video/Wan2.1.git
cd Wan2.1
pip install -r requirements.txt
python generate.py --task t2v-14B --size 1280*720 \
--ckpt_dir ./Wan2.1-T2V-14B \
--prompt "A futuristic city skyline at sunset, with flying cars zooming overhead."
Performance Tips
For machines with limited GPU memory, try the lighter t2v-1.3B model
Use the flags --offload_model True --t5_cpu to offload parts of the model to CPU
Control aspect ratio with the --size parameter (e.g., 832*480 for 16:9 480p)
Wan 2.1 offers prompt extension and “inspiration mode” via additional options
For reference, an RTX 4090 can generate a 5-second 480p video in about 4 minutes. Multi-GPU setups and various performance optimizations (FSDP, quantization, etc.) are supported for large-scale usage.
Why Wan 2.1 Matters for the Future of AI Video
As an open-source powerhouse challenging the giants in AI video generation, Wan 2.1 represents a significant shift in accessibility. Its free and open nature means anyone with a decent GPU can explore cutting-edge video generation without subscription fees or API costs.
For developers, the open-source license enables customization and improvement of the model. Researchers can extend its capabilities, while creative professionals can prototype video content quickly and efficiently.
In an era where proprietary AI models are increasingly locked behind paywalls, Wan 2.1 demonstrates that state-of-the-art performance can be democratized and shared with the broader community.
Frequently asked questions
Wan 2.1 is a fully open-source AI video generation model developed by Alibaba’s Tongyi Lab, capable of creating high-quality videos from text prompts, images, or existing videos. It’s free to use, supports multiple tasks, and runs efficiently on consumer GPUs.
Wan 2.1 supports multi-task video generation (text-to-video, image-to-video, video editing, etc.), multilingual text rendering in videos, high efficiency with its 3D causal Video VAE, and outperforms many commercial and open-source models in benchmarks.
You need Python 3.8+, PyTorch 2.4.0+ with CUDA, and an NVIDIA GPU (8GB+ VRAM for smaller model, 16-24GB for large model). Clone the GitHub repo, install dependencies, download the model weights, and use the provided scripts to generate videos locally.
Wan 2.1 democratizes access to state-of-the-art video generation by being open-source and free, allowing developers, researchers, and creatives to experiment and innovate without paywalls or proprietary restrictions.
Unlike closed-source alternatives like Sora or Runway Gen-2, Wan 2.1 is fully open-source and can be run locally. It generally surpasses previous open-source models and matches or outperforms many commercial solutions on quality benchmarks.
Arshia is an AI Workflow Engineer at FlowHunt. With a background in computer science and a passion for AI, he specializes in creating efficient workflows that integrate AI tools into everyday tasks, enhancing productivity and creativity.
Arshia Kahani
AI Workflow Engineer
Try FlowHunt and Build AI Solutions
Start building your own AI tools and video generation workflows with FlowHunt or schedule a demo to see the platform in action.
How to Transform Content Creation with Wan 2.2 & 2.5 Video Generation?
FlowHunt now supports Wan 2.2 and 2.5 video generation models for text-to-video, image-to-video, persona replacement, and animation. Transform your content crea...
October 2025 Update: Powerful New Video & Image AI Models
FlowHunt October 2025 update brings revolutionary Wan 2.2 and 2.5 video generation models for text-to-video, image-to-video, and animation, plus Qwen's advanced...
Master AI Face Replacement and Animation with WAN 2.2 Animate Replace in FlowHunt Photomatic
Learn how to use WAN 2.2 Animate Replace to create professional face-swapped videos with AI animation. Discover the complete workflow, advanced techniques, and ...
20 min read
AI Video
Animation
+4
Cookie Consent We use cookies to enhance your browsing experience and analyze our traffic. See our privacy policy.