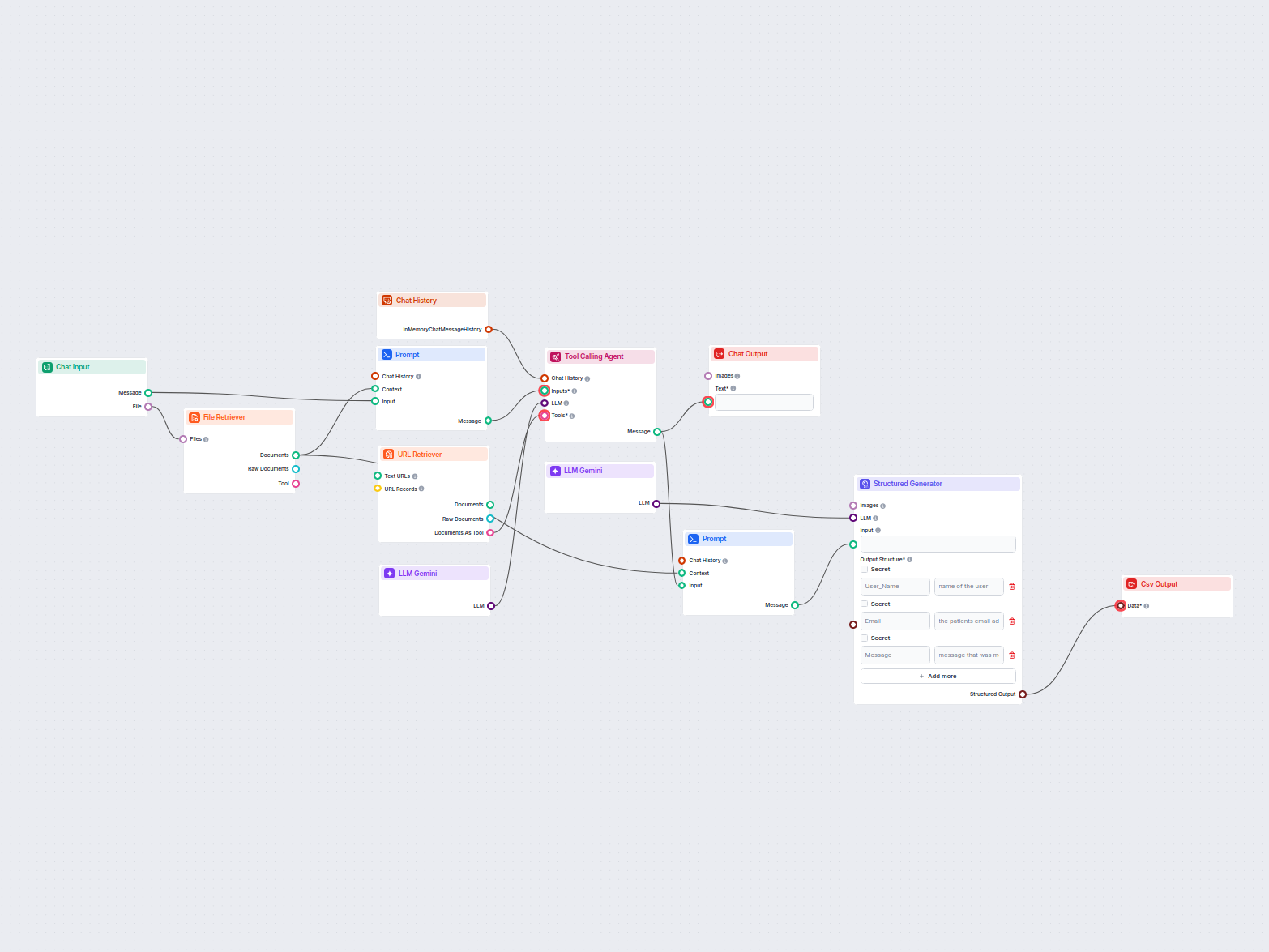
Email & File Data Extraction to CSV
This workflow extracts and organizes key information from emails and attached files, utilizes AI to process and structure the data, and outputs the results as a...
4 min read
To help you get started quickly, we have prepared several example flow templates that demonstrate how to use the Urlcontent component effectively. These templates showcase different use cases and best practices, making it easier for you to understand and implement the component in your own projects.
This workflow extracts and organizes key information from emails and attached files, utilizes AI to process and structure the data, and outputs the results as a...
We help companies like yours to develop smart chatbots, MCP Servers, AI tools or other types of AI automation to replace human in repetitive tasks in your organization.