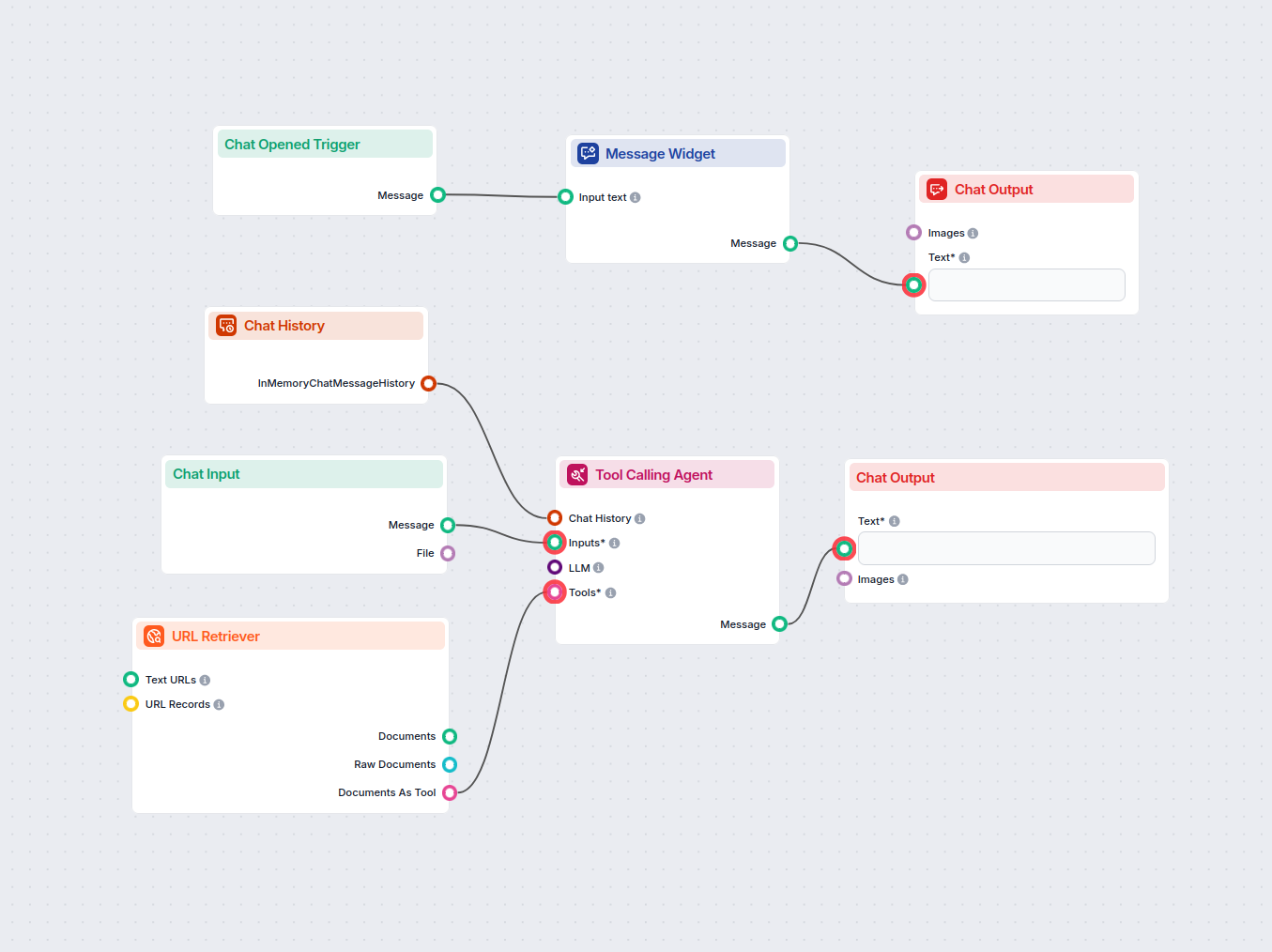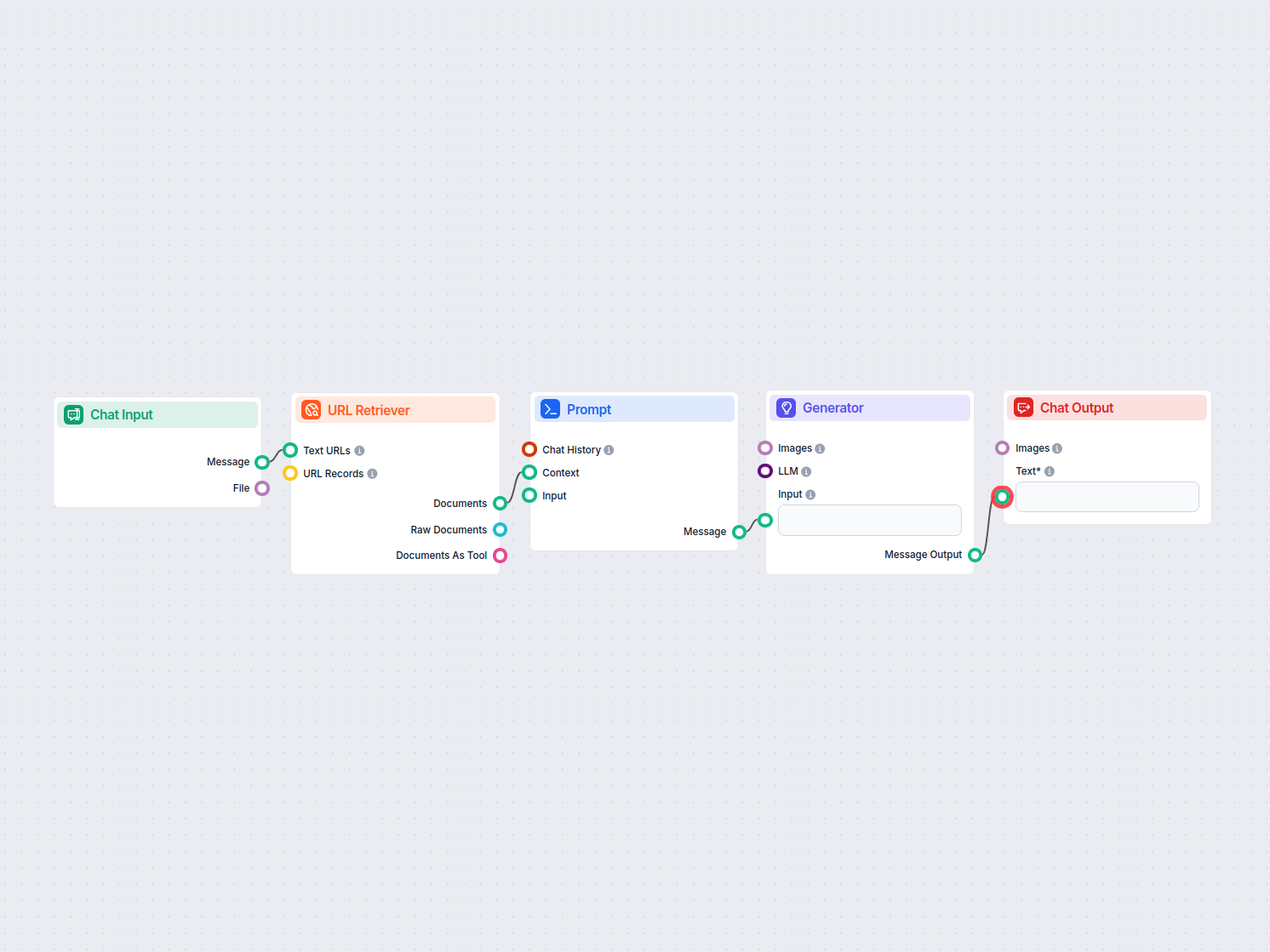
URL to Image Prompt Generator
Transform any article or web page URL into a detailed, creative prompt for text-to-image models. This workflow fetches content from a provided URL, analyzes it,...
3 min read
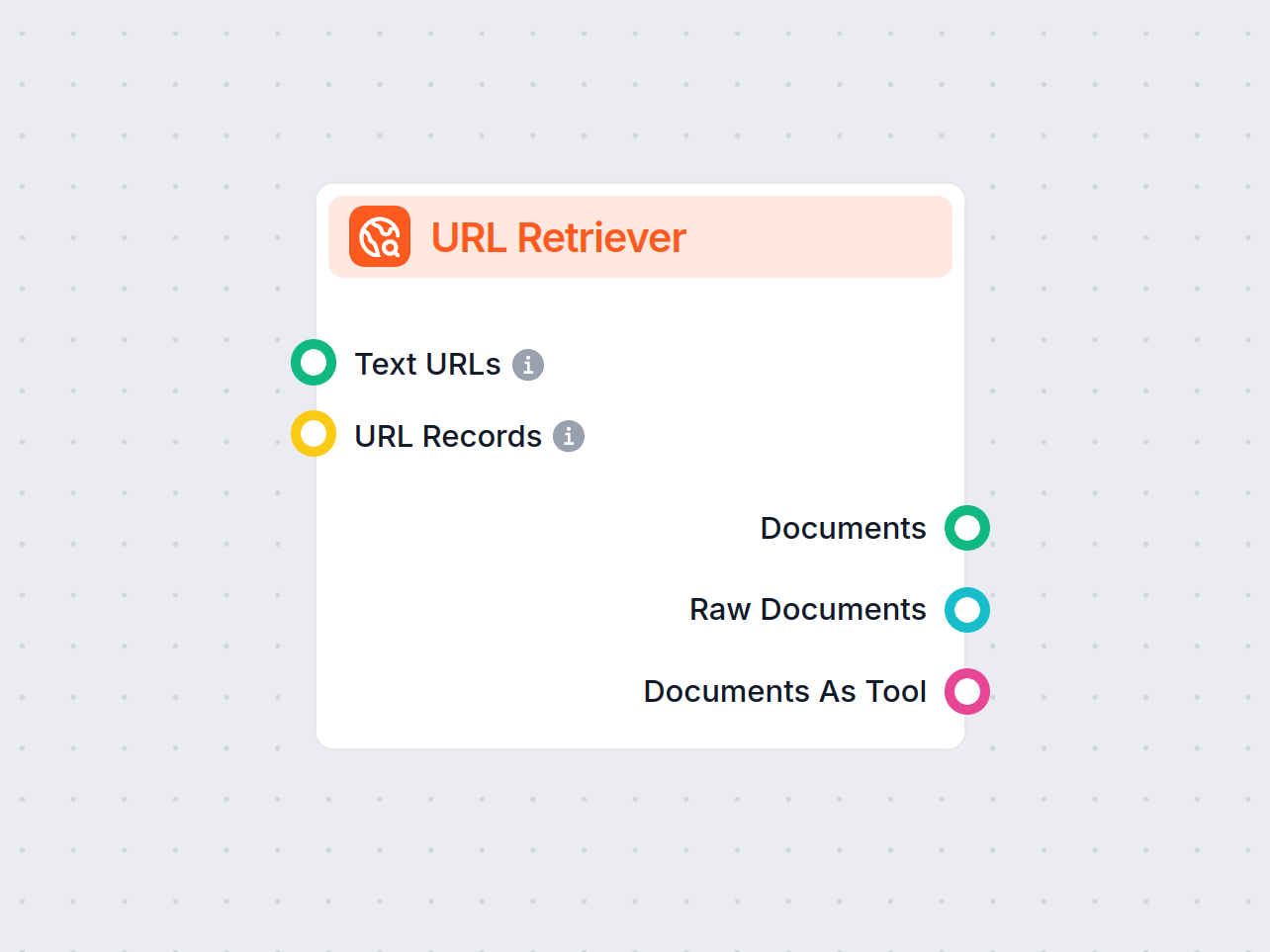
The URL Retriever lets you fetch and process content from web links, supporting OCR, metadata extraction, and flexible output for powering AI workflows.
Component description
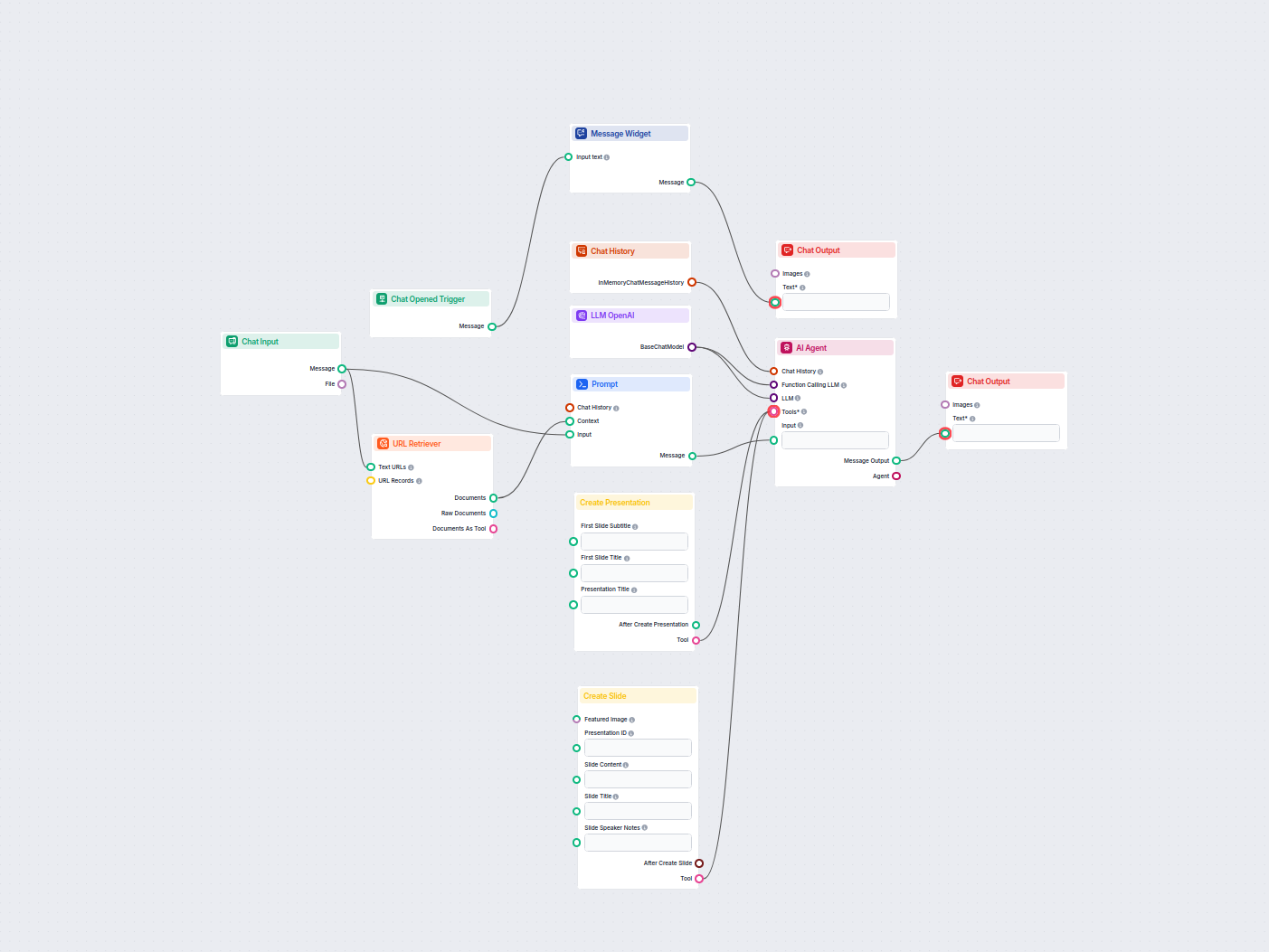
The URL Retriever is a versatile flow component designed to fetch and process web content from specified URLs, returning the information as structured documents. It serves as a bridge between external online content and your AI workflow, enabling you to integrate, analyze, or process web-based information efficiently.
This component retrieves the content of one or multiple URLs provided as input. It can extract the main text, metadata, and even process content from images using Optical Character Recognition (OCR). The retrieved data is then made available in various structured formats suitable for downstream AI tasks such as summarization, question answering, or knowledge extraction.
You can supply URLs to the component in two ways:
Text URLs:
MessageURL Records:
UrlRecord| Parameter | Type | Default | Description |
|---|---|---|---|
| Apply OCR | Boolean | false | If enabled, applies OCR to extract text from images in the document. |
| Cache TTL | Dropdown | 2 weeks | How long the content should be cached, with options from no cache up to 1 year. |
| From H1 if exists | Boolean | true | Begins extraction from the H1 tag if present, focusing on main content. |
| Load from pointer | Boolean | true | Loads content starting from the most relevant section based on your query. |
| Hide Resources | Boolean | false | Hides the retrieved resources from being output or displayed. |
| Max Tokens | Integer | 3000 | Sets the maximum number of tokens for the output text. |
| Skip Last Header | Boolean | true | Skips the last header during extraction for streamlined content. |
| Strategy | Dropdown | Include equal size from each documents | Determines how content is combined: concatenate fully or include equal parts from each document. |
| Export Content | Multi-select | All | Choose which HTML elements to export (H1-H6, Paragraph). |
| Include Metadata | Multi-select | Product | Specify which metadata fields to include (e.g., Product, Author, Website, etc.). |
| Verbose | Boolean | false | Enables detailed output for debugging or information purposes. |
| Tool Name | String | (empty) | Optionally assign a custom name to the tool for agent reference. |
| Tool Description | Multiline | (empty) | Provide a description to help agents understand the tool’s purpose. |
The URL Retriever provides its outputs in several formats, allowing flexible integration with various AI processes:
| Output Name | Type | Description |
|---|---|---|
| Documents | Message | The processed content from the URLs, ready for use in messaging-oriented workflows. |
| Raw Documents | Document | The raw, unprocessed document objects for advanced downstream processing. |
| Documents As Tool | Tool | The content packaged as a tool, enabling agent-based workflows to utilize the documents. |
| Feature | Description |
|---|---|
| Fetches URLs | Retrieves and processes web content from provided URLs. |
| OCR Support | Extracts text from images in documents if enabled. |
| Metadata Extraction | Optionally includes metadata such as author, product, or schema.org types. |
| Customizable Output | Select which HTML elements or metadata to export. |
| Caching | Configurable cache lifetimes for efficiency. |
| Multiple Output Types | Supports message, raw document, and tool outputs for workflow flexibility. |
The URL Retriever is a powerful and flexible bridge between web content and your AI workflows, offering granular control over content extraction and integration.
To help you get started quickly, we have prepared several example flow templates that demonstrate how to use the URL Retriever component effectively. These templates showcase different use cases and best practices, making it easier for you to understand and implement the component in your own projects.
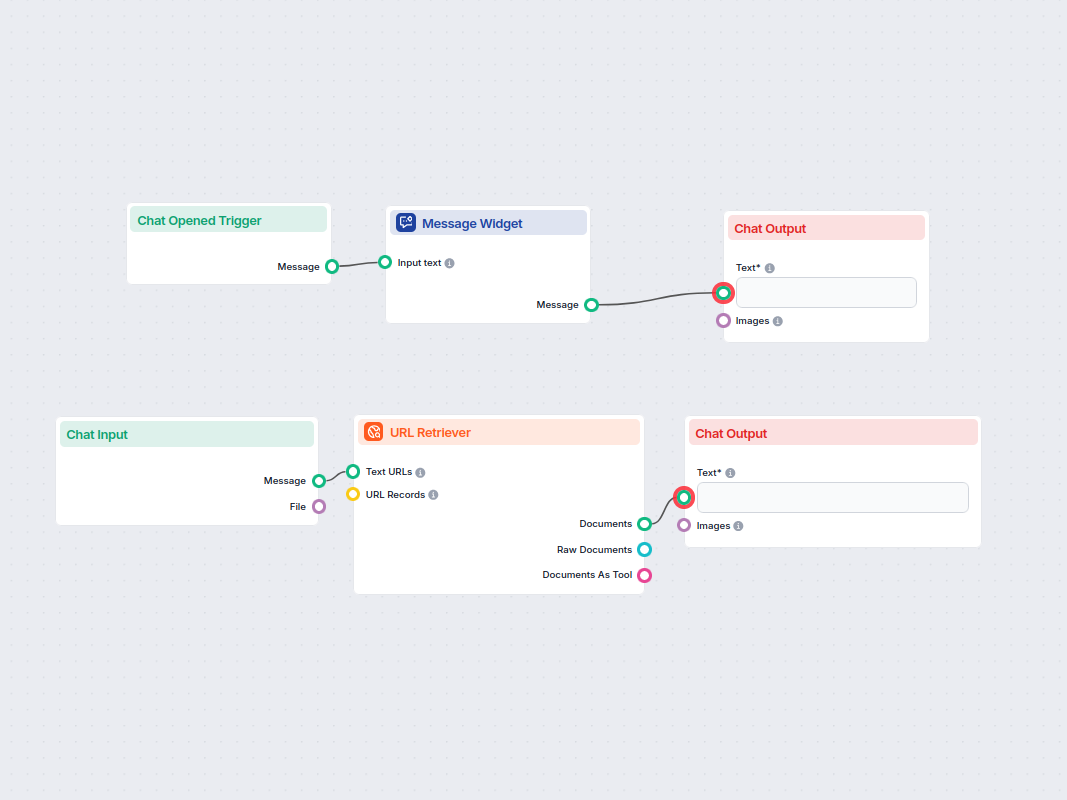
Transform any article or web page URL into a detailed, creative prompt for text-to-image models. This workflow fetches content from a provided URL, analyzes it,...
Generate transcripts from videos by extracting captions from provided URLs. Useful for quickly obtaining readable text from online videos with non-automatically...
Generate concise conclusions from websites, uploaded documents, or YouTube videos using AI. Perfect for quickly summarizing key takeaways and creating article e...
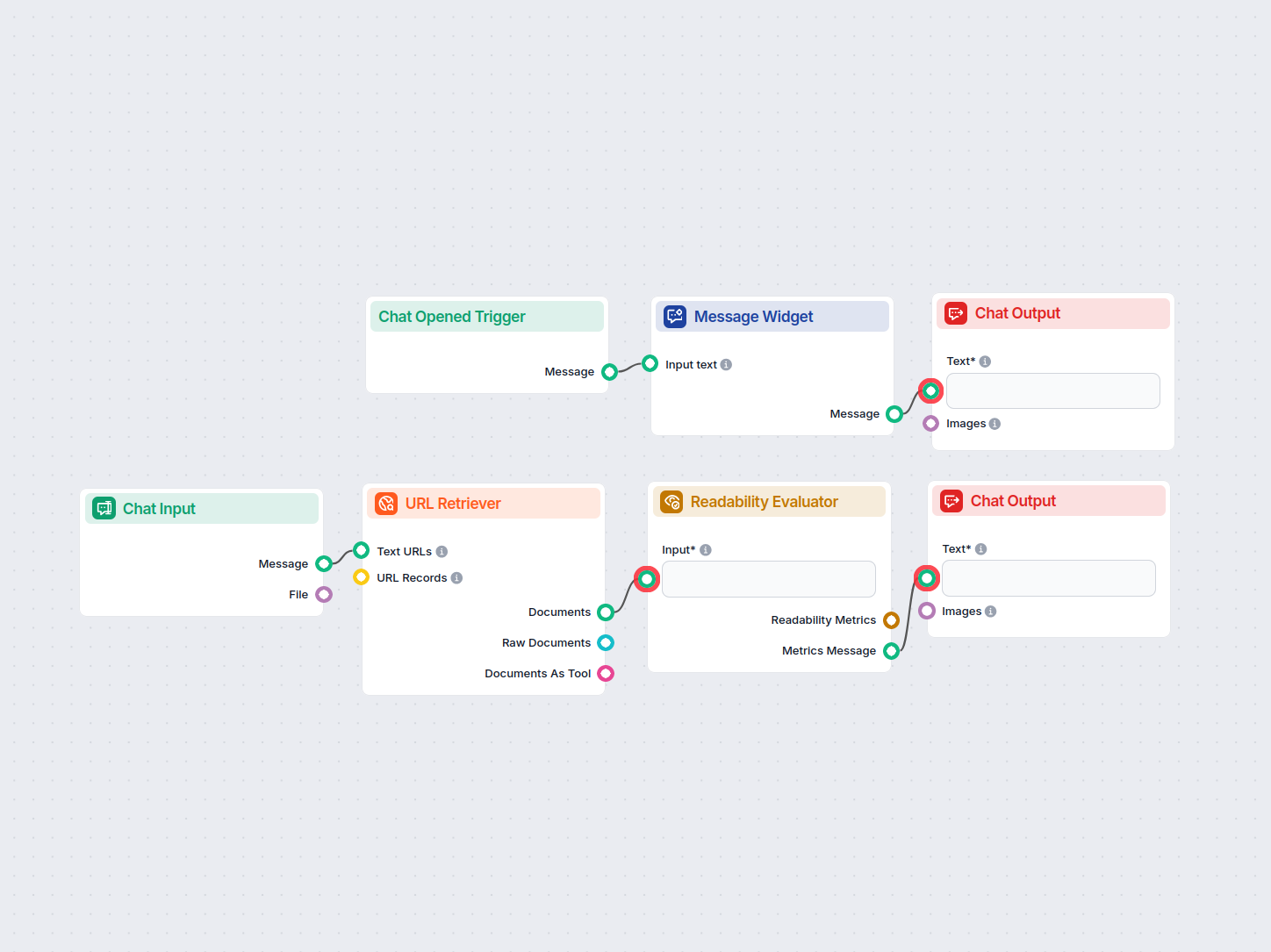
Analyze the readability of any website by inputting its URL. This workflow retrieves the content from the provided URL and evaluates its readability using multi...
Automatically generate SEO-optimized YouTube video titles, descriptions, and hashtags from any webpage URL. Perfect for marketers, content creators, and busines...
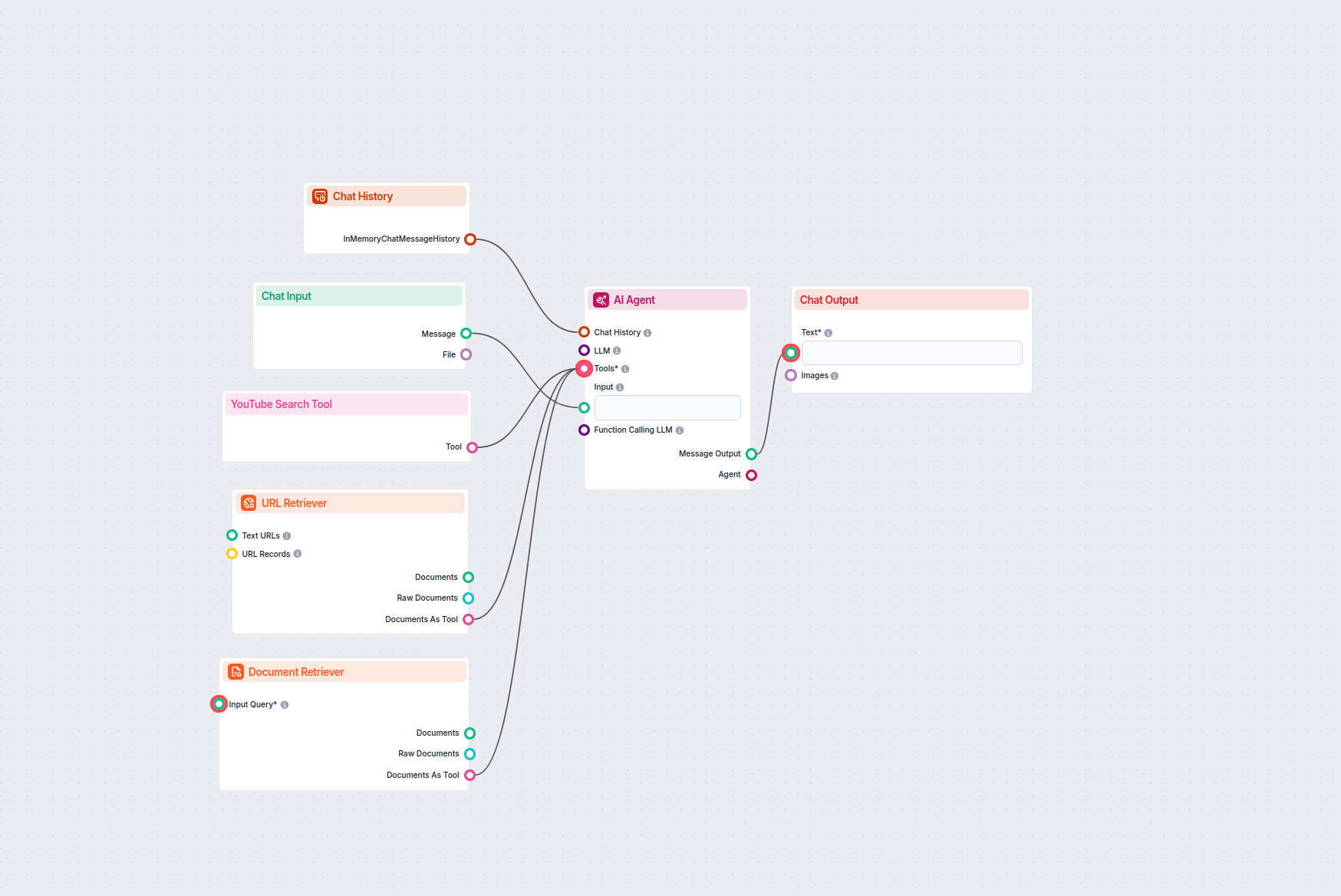
Interact with any YouTube video by chatting with its transcript. Instantly extract and query video content to get concise, AI-powered answers to your questions ...
Turn any YouTube video into a professional Google Slides presentation in minutes. This AI-powered workflow extracts content from a provided YouTube URL, analyze...
Automatically generate high-ranking SEO blog posts from YouTube videos. This workflow extracts video transcripts, analyzes top SEO keywords, creates a detailed ...
Showing 61 to 68 of 68 results
The URL Retriever fetches and processes content from specified web links, making text and metadata from online documents available for your workflow or AI agent.
Yes, by enabling the OCR option, the component can extract text from image-based documents or scanned PDFs.
It outputs processed documents as text messages, raw document objects, or as a tool for agent workflows, depending on your setup.
You can set how long retrieved content is cached, reducing repeated downloads and speeding up your flows.
Yes, you can specify which headings, paragraphs, or metadata fields to include in the output, allowing for targeted extraction.
Absolutely. The URL Retriever is essential for any automation or chatbot that needs to read, process, or summarize live web content.
Supercharge your workflows by integrating live web content. Extract, process, and utilize data from URLs with ease.
Integrate your workflows with Google Docs using the Google Docs Retriever component—seamlessly fetch document content for use in automations, chatbots, or knowl...
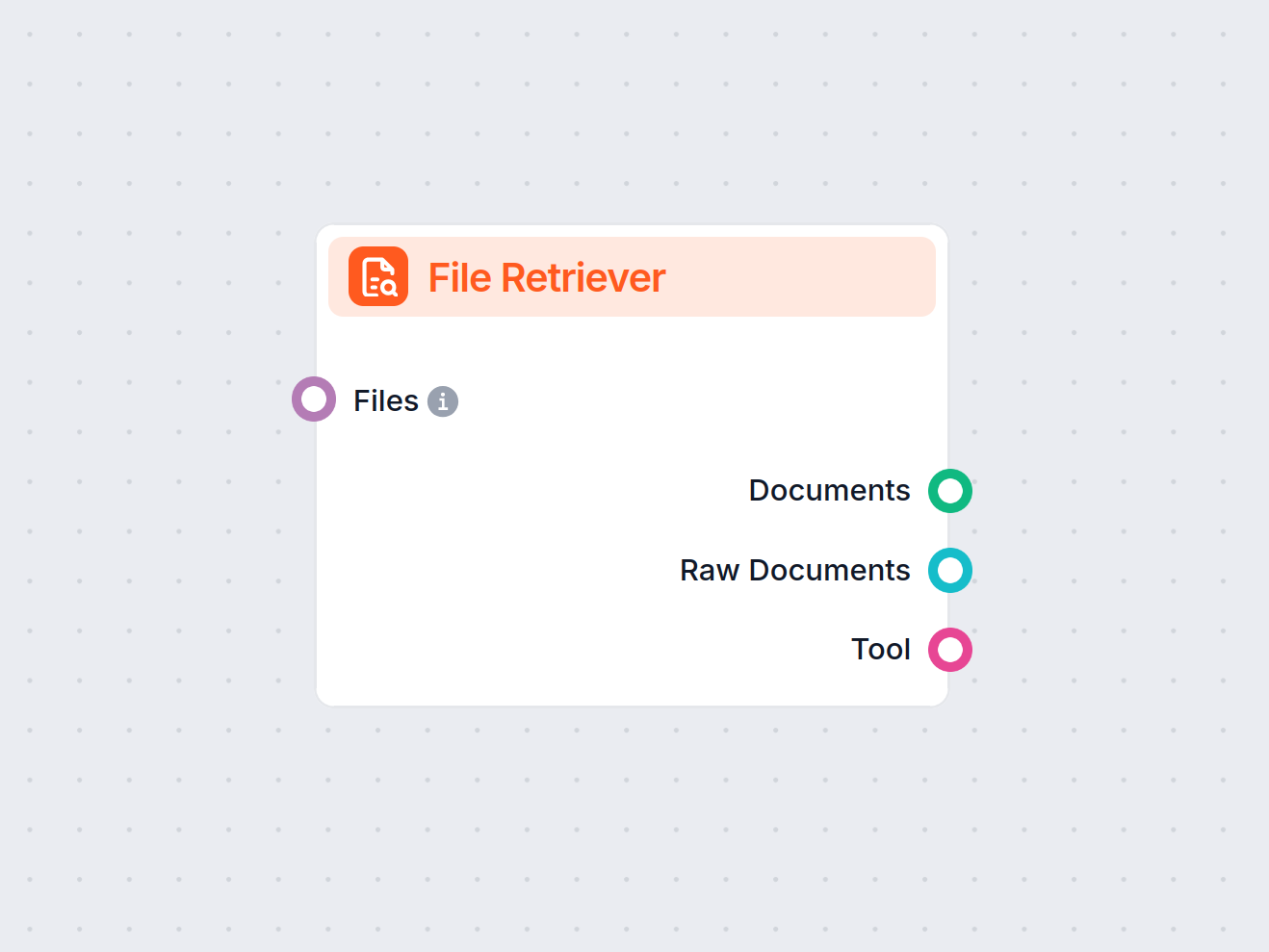
The File Retriever component in FlowHunt lets you bring files into your workflow and convert them into documents for further processing. It supports strategies ...
Capture website snapshots instantly with the Screenshot Tool component. Easily automate taking screenshots of any URL within your workflow—perfect for monitorin...