Retrieval Interleaved Generation, zkráceně RIG, je špičková AI metoda, která plynule kombinuje vyhledávání informací a tvorbu odpovědí. V minulosti modely AI používaly RAG (Retrieval Augmented Generation) nebo samostatné generování, ale RIG tyto procesy spojuje pro zvýšení přesnosti AI. Proplétáním získávání a generování mohou AI systémy čerpat z širší báze znalostí a poskytovat přesnější a relevantnější odpovědi. Hlavním cílem RIG je snížit počet chyb a zvýšit důvěryhodnost výstupů AI, což z něj činí zásadní nástroj pro vývojáře, kteří chtějí doladit přesnost AI. Retrieval Interleaved Generation se tak stává alternativou k RAG (Retrieval Augmented Generation) při generování odpovědí založených na kontextu.
Jak RIG (Retrieval Interleaved Generation) funguje?
Takto RIG funguje. Následující fáze jsou inspirovány originálním blogem
, který se více zaměřuje na obecné scénáře použití s Data Commons API. Ve většině případů však budete chtít využít jak obecnou [znalostní bázi (např. Wikipedia nebo Data Commons), tak i vlastní data. Zde je, jak můžete využít sílu toků ve FlowHunt k vytvoření RIG chatbota z vlastní znalostní báze i obecné znalostní báze typu Wikipedia.
Dotaz uživatele je předán generátoru, který vytvoří ukázkovou odpověď s citací odpovídajících sekcí. V této fázi může generátor vytvořit i dobrou odpověď, ale s vymyšlenými (halucinovanými) údaji a statistikami.
V další fázi použijeme AI Agenta, který tento výstup přijme a upraví data v každé sekci tím, že se připojí k Wikipedii a navíc doplní zdroje pro každou odpovídající sekci.
Jak vidíte, tato metoda výrazně zvyšuje přesnost chatbota a zajišťuje, že každá vygenerovaná sekce má svůj zdroj a je podložená fakty.
Připraveni rozšířit své podnikání?
Začněte svou bezplatnou zkušební verzi ještě dnes a viďte výsledky během několika dní.
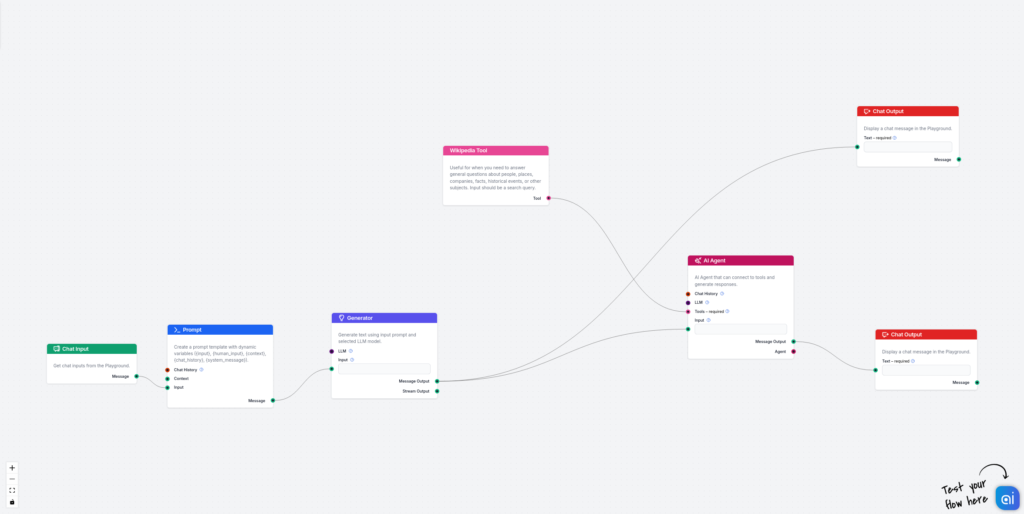
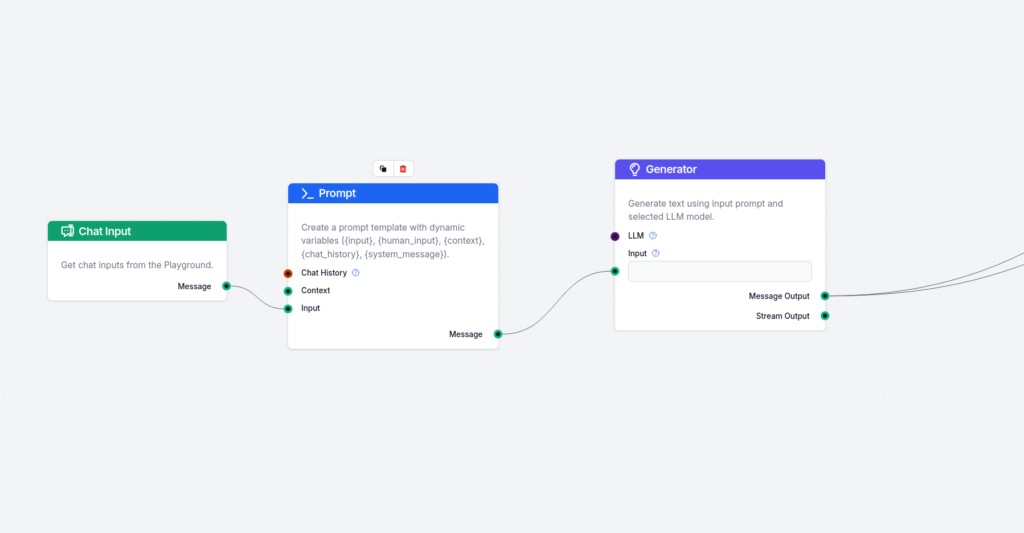
Přidejte první fázi (hloupý generátor ukázkové odpovědi):
První část toku se skládá z Chat inputu, šablony promptu a generátoru. Stačí je propojit. Nejpodstatnější je šablona promptu. Použil jsem tuto:
Zadán je uživatelský dotaz. Na základě uživatelského dotazu vygenerujte nejlepší možnou odpověď s falešnými daty nebo procenty. Po každé různé sekci vaší odpovědi uveďte, který zdroj dat použít k získání správných údajů a zpřesnění dané sekce. Můžete specifikovat buď interní znalostní zdroj k získání dat v případě, že existují vlastní data k uživatelskému produktu nebo službě, nebo použít Wikipedii coby obecný znalostní zdroj.
Přihlaste se k odběru newsletteru
Získejte nejnovější tipy, trendy a nabídky zdarma.
Příklad vstupu: Které země jsou nejlepší v obnovitelných zdrojích energie a jaká je nejlepší metrika pro měření a jaké je to číslo pro nejlepší zemi? Příklad výstupu: Nejlepší země v obnovitelné energii jsou Norsko, Švédsko, Portugalsko, USA [Hledat na Wikipedii s dotazem “Top Countries in renewable Energy”], obvyklá metrika je Capacity factor [Hledat na Wikipedii s dotazem “metric for renewable energy”], a první země má 20% capacity factor [hledat na Wikipedii “biggest capacity factor”]
Začněme! Uživatelský vstup: {input}
Zde využíváme Few Shot prompting, abychom docílili přesně takového formátu výstupu generátoru, jaký potřebujeme.
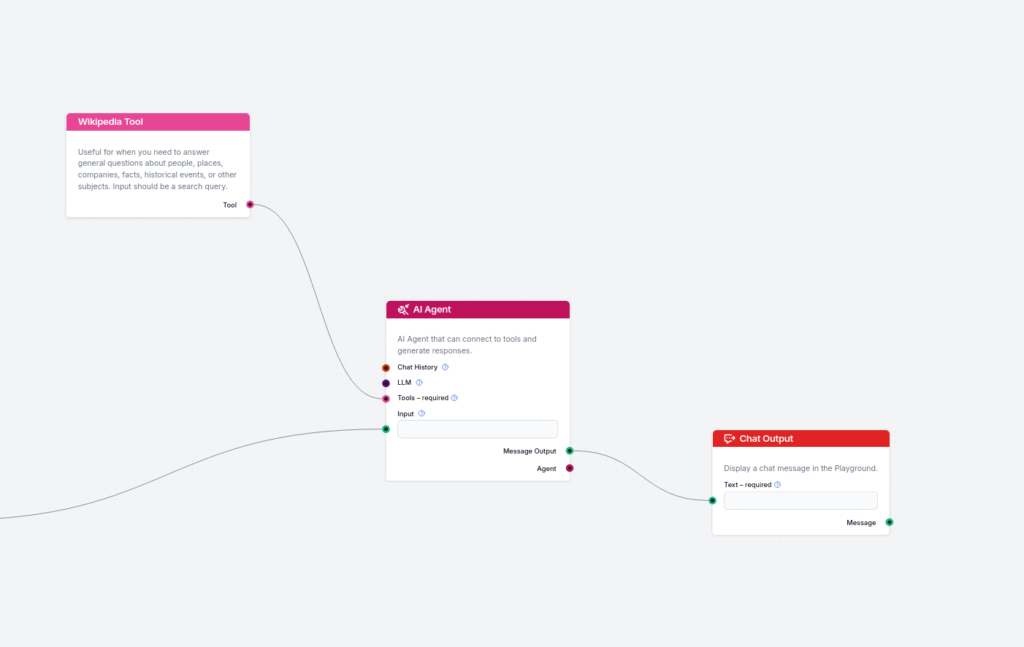
Přidejte část pro ověření faktů:
Nyní přidejte druhou část, která ověřuje výstup ukázkové odpovědi a upravuje odpověď na základě skutečných zdrojů pravdy. Zde využíváme Wikipedii a AI Agenty, protože je jednodušší a flexibilnější připojit Wikipedii k AI Agentům než k jednoduchým generátorům. Propojte výstup generátoru s AI Agentem a připojte nástroj Wikipedia k AI Agentovi. Zde je cíl, který používám pro AI Agenta:
Dostanete ukázkovou odpověď na uživatelskou otázku. Ukázková odpověď může obsahovat chybné údaje. Použijte nástroj Wikipedia v daných sekcích s určeným dotazem, abyste využili informace z Wikipedie k upřesnění odpovědi. Přidejte odkaz na Wikipedii do každé ze specifikovaných sekcí. ZÍSKEJTE DATA Z VAŠICH NÁSTROJŮ A UPRAVTE ODPOVĚĎ V DANÉ SEKCI. PŘIDEJTE ODKAZ NA ZDROJ DO TÉTO KONKRÉTNÍ SEKCE, NIKOLI NA KONEC.
Podobně můžete k AI Agentovi přidat Document Retriever, který se napojí na vaši vlastní znalostní bázi pro vyhledávání dokumentů.
Pro skutečné ocenění RIG je dobré se nejprve podívat na jeho předchůdce, Retrieval-Augmented Generation (RAG). RAG spojuje silné stránky systémů, které získávají relevantní data, a modelů, které generují koherentní a vhodný obsah. Přechod od RAG k RIG je velkým krokem vpřed. RIG nejen získává a generuje, ale také tyto procesy mísí pro lepší přesnost a efektivitu. To umožňuje AI systémům zlepšovat porozumění i výstupy krok za krokem a poskytovat výsledky, které jsou nejen přesné, ale i relevantní a přínosné. Propojením retrievalu a generování mohou AI systémy čerpat z obrovského množství informací a zároveň udržovat odpovědi soudržné a relevantní.
Budoucnost Retrieval Interleaved Generation
Budoucnost Retrieval Interleaved Generation vypadá slibně, s mnoha pokroky a směry výzkumu na obzoru. Jak AI nadále roste, RIG se stává klíčovým prvkem formování světa strojového učení a AI aplikací. Jeho potenciál přesahuje současné možnosti a slibuje proměnit způsob, jakým AI systémy zpracovávají a generují informace. S pokračujícím výzkumem očekáváme další inovace, které posílí integraci RIG do různých AI rámců a povedou k efektivnějším, přesnějším a spolehlivějším AI systémům. Jak se tyto změny rozvíjejí, význam RIG jen poroste a upevní jeho roli jako základního stavebního kamene přesnosti a výkonu AI.
Závěrem, Retrieval Interleaved Generation znamená zásadní krok vpřed v hledání přesnosti a efektivity AI. Umným propojením retrievalu a generování RIG zvyšuje výkon velkých jazykových modelů, zlepšuje vícekrokové uvažování a přináší vzrušující možnosti do vzdělávání i ověřování faktů. Do budoucna bude další vývoj RIG bezpochyby pohánět nové inovace v AI a upevní jeho roli jako klíčového nástroje v cestě za chytřejšími a spolehlivějšími systémy umělé inteligence.
Často kladené otázky
Co je Retrieval Interleaved Generation (RIG)?
RIG je AI metoda, která kombinuje získávání informací a generování odpovědí, což umožňuje chatbotům ověřovat vlastní odpovědi a poskytovat přesné výstupy podložené zdroji.
Jak RIG zlepšuje přesnost chatbotů?
RIG propojuje kroky získávání a generování, používá nástroje jako Wikipedia nebo vaše vlastní data, takže každá část odpovědi je podložena spolehlivými zdroji a ověřena na přesnost.
Jak mohu vytvořit RIG chatbota ve FlowHunt?
S FlowHunt můžete navrhnout RIG chatbota propojením šablon promptů, generátorů a AI Agentů jak s interními, tak externími znalostními zdroji, což umožňuje automatické ověřování faktů a citaci zdrojů.
Jaký je rozdíl mezi RAG a RIG?
Zatímco RAG (Retrieval Augmented Generation) nejprve získává informace a poté generuje odpovědi, RIG tyto kroky pro každou část odpovědi střídá, což vede k vyšší přesnosti a spolehlivějším, zdrojovaným odpovědím.
Yasha je talentovaný softwarový vývojář specializující se na Python, Javu a strojové učení. Yasha píše technické články o AI, inženýrství promptů a vývoji chatbotů.
Yasha Boroumand
CTO, FlowHunt
Připraveni vytvořit vlastní AI?
Začněte stavět chytré chatboty a AI nástroje s intuitivní platformou FlowHunt bez kódování. Propojujte bloky a automatizujte své nápady snadno.
Retrieval vs Cache Augmented Generation (CAG vs. RAG)
Objevte klíčové rozdíly mezi Retrieval-Augmented Generation (RAG) a Cache-Augmented Generation (CAG) v AI. Zjistěte, jak RAG dynamicky vyhledává aktuální inform...
Retrieval Augmented Generation (RAG) je pokročilý AI framework, který kombinuje tradiční systémy pro vyhledávání informací s generativními velkými jazykovými mo...
Objevte, jak agentní RAG mění tradiční retrieval-augmented generation tím, že umožňuje AI agentům činit inteligentní rozhodnutí, řešit složité problémy a dynami...
14 min čtení
AI Agents
RAG
+3
Souhlas s cookies Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.