
Datum vydání GPT-5 od OpenAI: Nejnovější novinky, modely o1 a co nás čeká dál
Prozkoumejte oficiální datum vydání GPT-5 od OpenAI, jak navazuje na o1 a GPT-4o a co další generace AI modelů znamená pro vývojáře a firmy.
6 min čtení
OpenAI
GPT-5
+1

OpenAI O1 využívá posilované učení a nativní řetězec myšlení k překonání GPT4o v komplexních RAG úlohách, ovšem za vyšší cenu.
OpenAI právě vydalo nový model s názvem OpenAI O1 ze série modelů O1. Hlavní architektonickou změnou těchto modelů je schopnost „přemýšlet“ před odpovědí na dotaz uživatele. V tomto blogu se podíváme detailněji na klíčové změny v OpenAI O1, nové paradigmata, která tyto modely využívají, a jak může tento model významně zvýšit přesnost RAG. Porovnáme jednoduchý RAG tok využívající OpenAI GPT4o a model OpenAI O1.
Model O1 využívá algoritmy rozsáhlého posilovaného učení během svého trénování. To modelu umožňuje rozvinout robustní „řetězec myšlení“, díky němuž přemýšlí o problémech hlouběji a strategičtěji. Neustálou optimalizací svých uvažovacích cest pomocí posilovaného učení model O1 výrazně zlepšuje schopnost analyzovat a efektivně řešit složité úkoly.
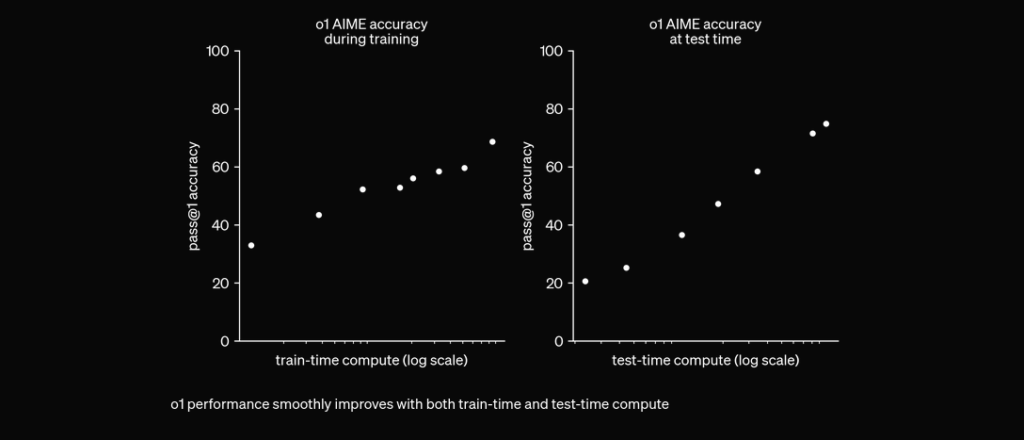
Dříve se řetězec myšlení osvědčil jako užitečný mechanismus prompt engineering, díky kterému LLM „samo přemýšlí“ a odpovídá na složité otázky krok za krokem. U modelů O1 je tento krok nativně integrován přímo do modelu v čase inference, což je užitečné pro matematické a programovací úlohy.
O1 je trénován pomocí RL, aby „přemýšlel“ před odpovědí prostřednictvím soukromého řetězce myšlení. Čím déle přemýšlí, tím lépe si vede v úlohách vyžadujících uvažování. To otevírá novou dimenzi škálování. Již nejsme limitováni pretrénováním. Lze škálovat i inference compute. pic.twitter.com/niqRO9hhg1
— Noam Brown (@polynoamial) 12. září 2024
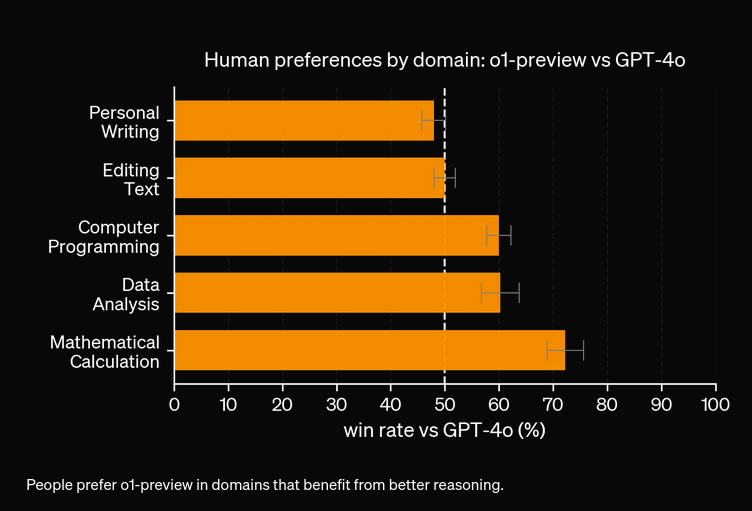
V rozsáhlých hodnoceních model O1 prokázal pozoruhodné výsledky v různých benchmarcích:
Pro otestování přesnosti OpenAI O1 a GPT4o jsme vytvořili dva identické toky, ale s různými LLM. Porovnáme schopnost odpovídat na otázky na základě dvou zdrojů indexovaných z technické zprávy OpenAI O1.
Nejprve vytvoříme jednoduchý RAG tok ve FlowHunt. Sestává z Chat Input, Document Retrieveru (načítá relevantní dokumenty), Promptu, Generátoru a Chat Outputu. Komponenta LLM OpenAI je přidána pro určení modelu (jinak je výchozí GPT4o).
Zde je odpověď od GPT4o:
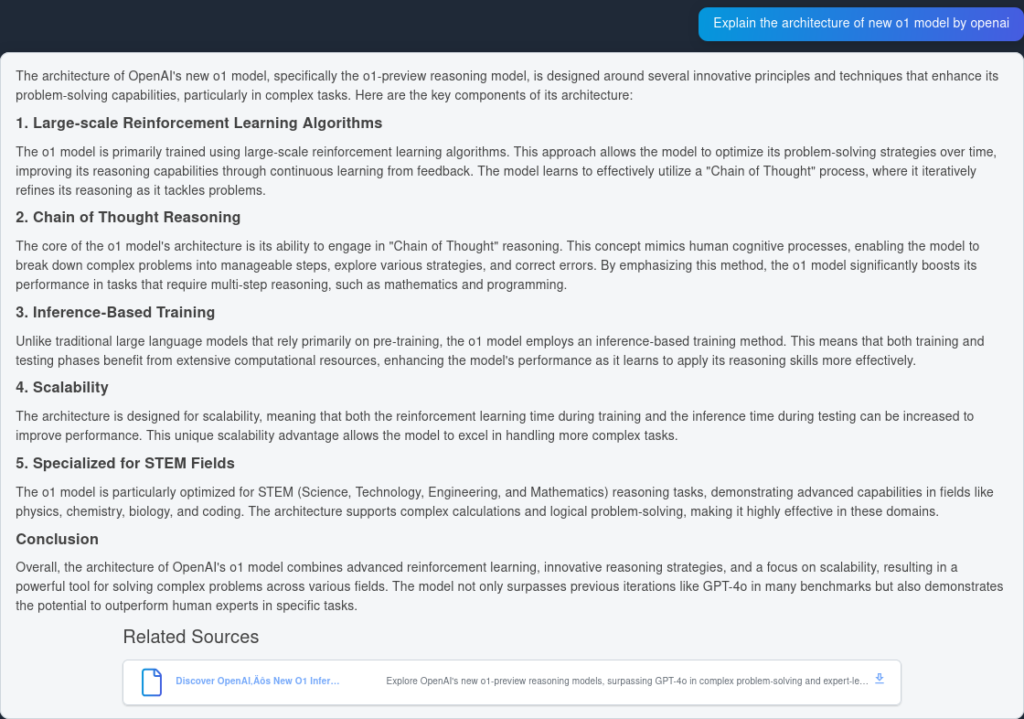
A zde je výsledek od OpenAI O1:
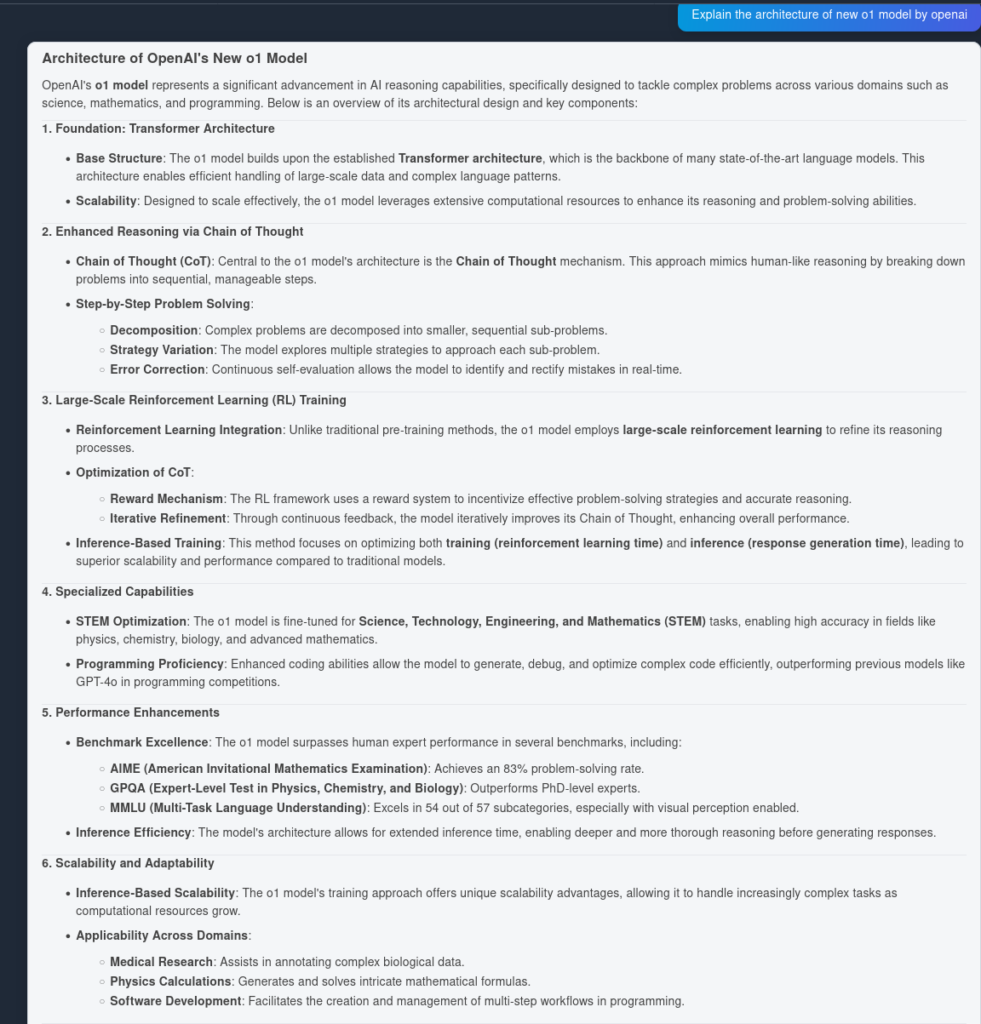
Jak je vidět, OpenAI O1 zachytilo více architektonických výhod přímo z článku—6 bodů oproti 4. Navíc O1 ke každému bodu přidává logické implikace, čímž dokument obohacuje o další vhledy do užitečnosti architektonických změn.
Začněte svou bezplatnou zkušební verzi ještě dnes a viďte výsledky během několika dní.
Z našich experimentů plyne, že model O1 bude stát více za vyšší přesnost. Nový model má 3 typy tokenů: Prompt Token, Completion Token a Reason Token (nově přidaný typ tokenu), což jej může činit nákladnějším. Ve většině případů poskytuje OpenAI O1 odpovědi, které jsou užitečnější, pokud jsou podloženy fakty. Existují však případy, kdy GPT4o překonává OpenAI O1—některé úkoly prostě nevyžadují uvažování.
Yasha je talentovaný softwarový vývojář specializující se na Python, Javu a strojové učení. Yasha píše technické články o AI, inženýrství promptů a vývoji chatbotů.

Vyzkoušejte FlowHunt a využijte nejnovější LLM jako OpenAI O1 a GPT4o pro špičkové uvažování a retrieval-augmented generation.
Prozkoumejte oficiální datum vydání GPT-5 od OpenAI, jak navazuje na o1 a GPT-4o a co další generace AI modelů znamená pro vývojáře a firmy.

Objevte, jak OpenAI o1 Preview překonává GPT-4 díky zvládnutí složitých zadání pro psaní prostřednictvím interního plánování, kreativity a dodržování omezení, c...

GPT-4.1 od OpenAI znamená zásadní skok ve výkonu AI. Tento článek analyzuje jeho silné a slabé stránky napříč pěti klíčovými AI úlohami – generování obsahu, mat...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.