AI dokáže analyzovat velké množství dat během několika sekund, ale pouze některá data budou relevantní nebo vhodná pro výstup. Komponenta Dokument na text vám dává kontrolu nad tím, jak jsou data z retrieverů zpracována a transformována do textu.
Komponenta Dokument na text je navržena pro převod vstupních znalostních dokumentů do formátu prostého textu. To je obzvláště užitečné v AI a datových workflowech, kde je vyžadován textový výstup pro další zpracování, analýzu nebo jako vstup pro jazykové modely.
Co komponenta dělá
Tato komponenta přijímá jeden nebo více strukturovaných dokumentů (například HTML, Markdown, PDF nebo jiné podporované formáty) a extrahuje z nich textový obsah. Umožňuje přesně určit, které části dokumentů exportovat, zda zahrnout metadata a jak nakládat se sekcemi nebo záhlavími dokumentu. Výstupem je sjednocený objekt zprávy obsahující extrahovaný text, připravený pro následné úkoly jako sumarizace, klasifikace nebo odpovědi na dotazy.
Vstupy
Komponenta přijímá několik konfigurovatelných vstupů:
| Název vstupu | Typ | Povinné | Popis | Výchozí hodnota |
|---|---|---|---|---|
| Dokumenty | List[Document] | Ano | Znalostní dokumenty, které se mají převést na text. | N/A (zadává uživatel) |
| Od H1 pokud existuje | Boolean | Ano | Zahájit extrakci od prvního H1 záhlaví, pokud je přítomno. | true |
| Načítat z pointeru | Boolean | Ano | Zahájit extrakci z pointeru, který nejlépe odpovídá vstupnímu dotazu, nebo načíst vše. | true |
| Max Tokenů | Integer | Ne | Maximální počet tokenů ve výstupním textu. | 3000 |
| Přeskočit poslední záhlaví | Boolean | Ano | Přeskočit poslední záhlaví (často patička) pro optimalizaci výstupu. | false |
| Strategie | String | Ano | Strategie extrakce textu: spojení dokumentů nebo zahrnutí stejné velikosti z každého. | “Include equal size from each documents” |
| Exportovat obsah | Multi-select | Ne | Které typy obsahu zahrnout (např. H1, H2, Odstavec). | Všechny typy vybrány |
| Zahrnout metadata | Multi-select | Ne | Metadata pole, která mají být zahrnuta ve výstupu, pokud jsou k dispozici. | Product |
Dostupné typy obsahu: H1, H2, H3, H4, H5, H6, Odstavec
Možnosti metadat: Autor, Produkt, BreadcrumbList, VideoObject, BlogPosting, FAQPage, WebSite, opengraph
Výstupy
Komponenta produkuje následující výstup:
- Zpráva: Objekt zprávy obsahující převedený text a případně zahrnutá metadata.
Klíčové vlastnosti & užitečnost
- Flexibilní extrakce obsahu: Přesně určete, které části vašich dokumentů budou extrahovány (např. pouze hlavní záhlaví a odstavce, nebo veškerý obsah).
- Zahrnutí metadat: Volitelné zahrnutí bohatých metadat (např. autor, produkt nebo strukturovaná data) do výstupu, což je užitečné pro následnou kontextualizaci.
- Omezení počtu tokenů: Omezte velikost výstupu dle požadavků následných modelů nastavením maximálního počtu tokenů.
- Vlastní strategie extrakce:
- Spojit dokumenty, naplnit od prvního až do limitu tokenů: Prioritizuje postupné naplňování výstupu od prvního dokumentu.
- Zahrnout stejnou velikost z každého dokumentu: Vyvažuje obsah z více dokumentů v rámci tokenového limitu.
- Chytrá práce se sekcemi: Možnost přeskočit patičky dokumentů nebo začít od nejrelevantnější sekce k vašemu dotazu, což zvyšuje relevanci extrahovaného textu.
Typické příklady použití
- Předzpracování znalostních bází pro AI modely (např. před embedováním nebo indexací).
- Sumarizace či zhuštění rozsáhlých dokumentů extrakcí pouze relevantních částí.
- Poskytování strukturovaného obsahu chatbotům, vyhledávačům nebo dalším NLP pipeline.
- Budování hybridních retrieval systémů, které kombinují text s metadaty pro bohatší kontext.
Souhrnná tabulka
| Schopnost | Popis |
|---|---|
| Typy vstupů | Seznam dokumentů |
| Typ výstupu | Zpráva (Text + Metadata) |
| Granularita obsahu | Výběr záhlaví/odstavců k zahrnutí |
| Možnosti metadat | Výběr více polí metadat k exportu |
| Řízení velikosti výstupu | Nastavení max. počtu tokenů |
| Strategie extrakce | Spojit nebo vyvážit mezi dokumenty |
| Výběr sekce | Začít od H1, z pointeru nebo přeskočit poslední záhlaví |
Strategie
Bot může pro vytvoření textového výstupu procházet mnoho dokumentů. Nastavení Strategie vám umožní řídit, jak tyto dokumenty využívá chytře a zároveň zůstává v rámci limitu tokenů.
Aktuálně jsou možné dvě strategie:
- Zahrnout stejnou velikost z každého dokumentu: Využívá všechny nalezené dokumenty rovnoměrně.
- Spojit dokumenty, naplnit od prvního až do limitu tokenů: Spojí dokumenty dohromady a upřednostní je dle relevance k dotazu.
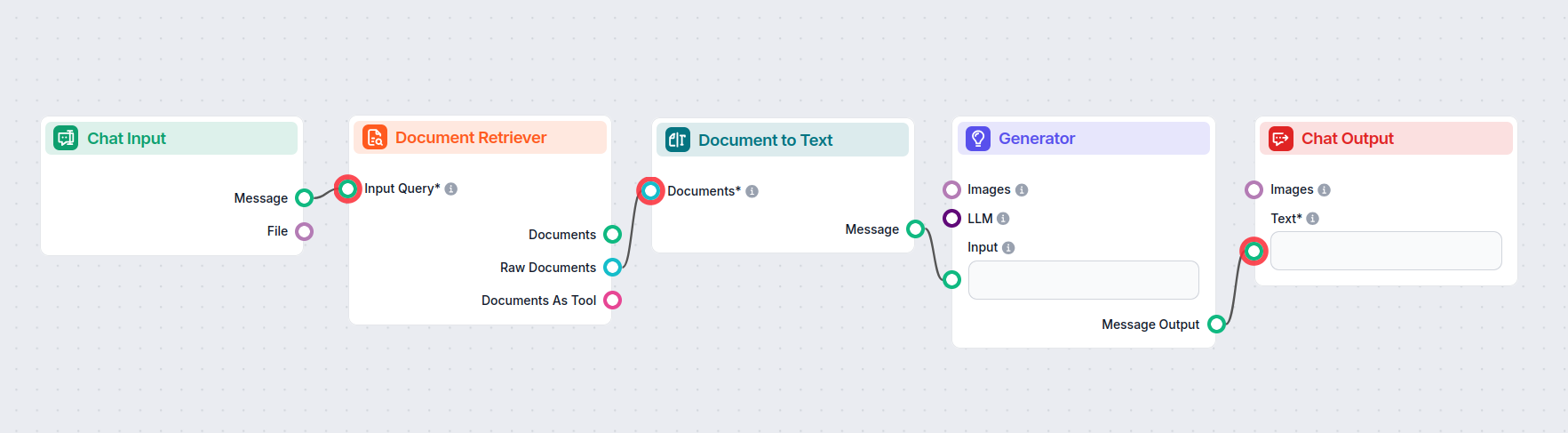
Jak propojit komponentu Dokument na text do vašeho flow
Jedná se o transformer komponentu, což znamená, že spojuje výstupy dvou komponent. Dokument na text přijímá Dokumenty, které vrací komponenty Retriever:
- Document Retriever – získává znalosti z připojených znalostních zdrojů (stránky, dokumenty apod.).
- URL Retriever – Umožňuje určit URL, ze které má bot načíst znalosti.
- GoogleSearch – Dává botovi možnost vyhledávat znalosti na webu.
Znalosti jsou při průchodu transformerem převedeny do čitelného Markdown textu. Tento text pak lze připojit ke komponentám vyžadujícím textový vstup, jako jsou splittery, widgety nebo výstupní komponenty.
Zde je příklad flow, který používá komponentu Dokument na text jako most mezi retrievery dokumentů a AI generátorem: