
Vyhledávání informací
Vyhledávání informací využívá AI, NLP a strojové učení k efektivnímu a přesnému získávání dat, která odpovídají požadavkům uživatelů. Je základem webových vyhle...
6 min čtení
Information Retrieval
AI
+4

AI vyhledávání využívá strojové učení a vektorové reprezentace k pochopení záměru hledání a kontextu, čímž poskytuje vysoce relevantní výsledky nad rámec přesné shody klíčových slov.
AI vyhledávání využívá strojové učení k pochopení kontextu a záměru vyhledávacích dotazů, převádí je na číselné vektory pro přesnější výsledky. Na rozdíl od tradičních vyhledávání podle klíčových slov AI vyhledávání interpretuje sémantické vztahy, což jej činí efektivním pro různorodé typy dat a jazyky.
AI vyhledávání, často označované jako sémantické nebo vektorové vyhledávání, je metoda vyhledávání, která využívá modely strojového učení k pochopení záměru a kontextového významu za vyhledávacími dotazy. Na rozdíl od tradičního vyhledávání podle klíčových slov AI vyhledávání převádí data a dotazy do číselných reprezentací známých jako vektory nebo vektorizace. To umožňuje vyhledávači chápat sémantické vztahy mezi různými částmi dat a poskytovat relevantnější a přesnější výsledky, i když přesná klíčová slova nejsou přítomna.
AI vyhledávání představuje významnou evoluci v technologiích vyhledávání. Tradiční vyhledávače se silně spoléhají na shodu klíčových slov, kde přítomnost konkrétních termínů v dotazu i dokumentech určuje relevanci. AI vyhledávání však využívá modely strojového učení k pochopení základního kontextu a smyslu dotazů i dat.
Převodem textu, obrázků, audia a dalších nestrukturovaných dat do vícerozměrných vektorů dokáže AI vyhledávání měřit podobnost mezi různými částmi obsahu. Tento přístup umožňuje vyhledávači dodávat výsledky, které jsou kontextově relevantní, i když neobsahují přesná klíčová slova použitá v dotazu.
Klíčové komponenty:
Základem AI vyhledávání je koncept vektorových reprezentací. Vektorové reprezentace jsou číselné reprezentace dat, které zachycují sémantický význam textu, obrázků nebo jiných typů dat. Tyto reprezentace umisťují podobný obsah blízko sebe v vícerozměrném vektorovém prostoru.
Jak to funguje:
Příklad:
Tradiční vyhledávače podle klíčových slov fungují na principu shody výrazů v dotazu s dokumenty obsahujícími tyto výrazy. Pro řazení výsledků využívají techniky jako invertované indexy a frekvenci termínů.
Omezení vyhledávání podle klíčových slov:
Výhody AI vyhledávání:
| Aspekt | Vyhledávání podle klíčových slov | AI vyhledávání (sémantické/vektorové) |
|---|---|---|
| Shoda | Přesná shoda klíčových slov | Sémantická podobnost |
| Kontextové povědomí | Omezené | Vysoké |
| Synonyma | Vyžaduje manuální seznam synonym | Automaticky díky vektorům |
| Překlepy | Může selhat bez fuzzy vyhledávání | Více tolerantní díky kontextu |
| Pochopení záměru | Minimální | Výrazné |
Sémantické vyhledávání je klíčovým využitím AI vyhledávání – soustředí se na pochopení záměru uživatele a kontextového významu dotazu.
Proces:
Klíčové techniky:
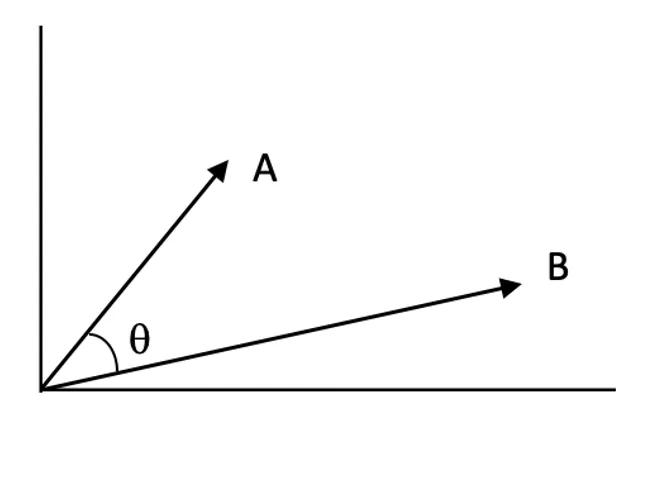
Skóre podobnosti:
Skóre podobnosti vyjadřuje, jak blízko jsou dva vektory ve vektorovém prostoru. Vyšší skóre znamená vyšší relevanci mezi dotazem a dokumentem.
Algoritmy Approximate Nearest Neighbor (ANN):
Najít přesné nejbližší sousedy ve vysokodimenzionálních prostorech je výpočetně náročné. ANN algoritmy poskytují efektivní aproximace.
AI vyhledávání otevírá širokou škálu aplikací v různých odvětvích díky schopnosti chápat a interpretovat data nad rámec pouhé shody klíčových slov.
Popis: Sémantické vyhledávání zlepšuje uživatelský zážitek interpretací záměru dotazu a poskytováním kontextově relevantních výsledků.
Příklady:
Popis: Díky pochopení preferencí a chování uživatele může AI vyhledávání poskytovat personalizovaný obsah nebo doporučení produktů.
Příklady:
Popis: AI vyhledávání umožňuje systémům přesně odpovídat na dotazy uživatelů na základě extrakce informací z dokumentů.
Příklady:
Popis: AI vyhledávání indexuje a umožňuje hledání v nestrukturovaných datech jako obrázky, audio či video převodem na vektorizace.
Příklady:
Integrace AI vyhledávání do AI automatizace a chatbotů významně zvyšuje jejich možnosti.
Výhody:
Kroky implementace:
Příklad využití:
Přestože AI vyhledávání přináší mnoho výhod, je třeba počítat s určitými výzvami:
Strategie zmírnění rizik:
Sémantické a vektorové vyhledávání v AI se stalo silnou alternativou tradičního vyhledávání podle klíčových slov a fuzzy vyhledávání – významně zvyšuje relevanci a přesnost výsledků díky pochopení kontextu a významu dotazů.
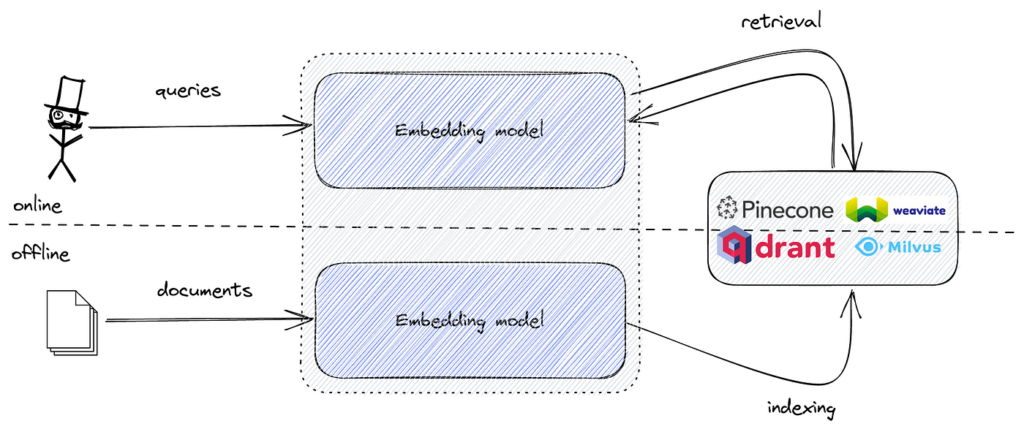
Při implementaci sémantického vyhledávání se textová data převádějí na vektorové reprezentace, které zachycují sémantický význam textu. Tyto reprezentace jsou vysokodimenzionální číselné vektory. Pro efektivní vyhledávání a nalezení nejpodobnějších vektorů k dotazovému vektoru je třeba nástroj optimalizovaný pro podobnostní vyhledávání ve vysokodimenzionálním prostoru.
FAISS poskytuje potřebné algoritmy a datové struktury pro efektivní provádění tohoto úkolu. Kombinací sémantických vektorů s FAISS můžeme vytvořit výkonný sémantický vyhledávač, který zvládne velké datové sady s nízkou latencí.
Implementace sémantického vyhledávání s FAISS v Pythonu zahrnuje několik kroků:
Pojďme se na každý krok podívat podrobněji.
Připravte si dataset (např. články, tikety podpory, popisy produktů).
Příklad:
documents = [
"Jak resetovat heslo na naší platformě.",
"Řešení problémů s připojením k síti.",
"Průvodce instalací softwarových aktualizací.",
"Nejlepší postupy pro zálohování a obnovu dat.",
"Nastavení dvoufaktorové autentizace pro zvýšenou bezpečnost."
]
Vyčistěte a naformátujte textová data dle potřeby.
Převeďte textová data na vektorové reprezentace pomocí předtrénovaných Transformer modelů z knihoven jako Hugging Face (transformers nebo sentence-transformers).
Příklad:
from sentence_transformers import SentenceTransformer
import numpy as np
# Načtení předtrénovaného modelu
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
# Generování vektorů pro všechny dokumenty
embeddings = model.encode(documents, convert_to_tensor=False)
embeddings = np.array(embeddings).astype('float32')
float32, jak FAISS vyžaduje.Vytvořte FAISS index pro uložení vektorů a efektivní podobnostní vyhledávání.
Příklad:
import faiss
embedding_dim = embeddings.shape[1]
index = faiss.IndexFlatL2(embedding_dim)
index.add(embeddings)
IndexFlatL2 provádí přesné vyhledávání pomocí L2 (eukleidovské) vzdálenosti.Převeďte dotaz uživatele na vektor a najděte nejbližší sousedy.
Příklad:
query = "Jak změním heslo k účtu?"
query_embedding = model.encode([query], convert_to_tensor=False)
query_embedding = np.array(query_embedding).astype('float32')
k = 3
distances, indices = index.search(query_embedding, k)
Pomocí indexů zobrazte nejrelevantnější dokumenty.
Příklad:
print("Nejlepší výsledky pro váš dotaz:")
for idx in indices[0]:
print(documents[idx])
Očekávaný výstup:
Nejlepší výsledky pro váš dotaz:
Jak resetovat heslo na naší platformě.
Nastavení dvoufaktorové autentizace pro zvýšenou bezpečnost.
Nejlepší postupy pro zálohování a obnovu dat.
FAISS poskytuje několik typů indexů:
Použití invertovaného indexu (IndexIVFFlat):
nlist = 100
quantizer = faiss.IndexFlatL2(embedding_dim)
index = faiss.IndexIVFFlat(quantizer, embedding_dim, nlist, faiss.METRIC_L2)
index.train(embeddings)
index.add(embeddings)
Normalizace a vyhledávání podle skalárního součinu:
Použití kosinové podobnosti může být pro textová data efektivnější.
AI vyhledávání je moderní metoda vyhledávání, která využívá strojové učení a vektorové reprezentace k pochopení záměru a kontextového významu dotazů, čímž poskytuje přesnější a relevantnější výsledky než tradiční vyhledávání podle klíčových slov.
Na rozdíl od vyhledávání podle klíčových slov, které spoléhá na přesné shody, AI vyhledávání interpretuje sémantické vztahy a záměr dotazu, což ho činí efektivním pro přirozený jazyk a nejednoznačné vstupy.
Vektorové reprezentace jsou číselné reprezentace textu, obrázků nebo jiných typů dat, které zachycují jejich sémantický význam a umožňují vyhledávači měřit podobnost a kontext mezi různými daty.
AI vyhledávání pohání sémantické vyhledávání v e-commerce, personalizovaná doporučení ve streamování, systémy otázek a odpovědí v zákaznické podpoře, procházení nestrukturovaných dat a vyhledávání dokumentů ve výzkumu a podnikání.
Oblíbené nástroje zahrnují FAISS pro efektivní vyhledávání vektorové podobnosti a vektorové databáze jako Pinecone, Milvus, Qdrant, Weaviate, Elasticsearch a Pgvector pro škálovatelné ukládání a vyhledávání reprezentací.
Integrací AI vyhledávání mohou chatboti a automatizační systémy lépe rozumět dotazům uživatelů, vyhledávat kontextově relevantní odpovědi a poskytovat dynamické, personalizované reakce.
Výzvy zahrnují vysoké nároky na výpočetní výkon, složitost interpretace modelů, potřebu kvalitních dat a zajištění soukromí a bezpečnosti při práci s citlivými informacemi.
FAISS je open-source knihovna pro efektivní vyhledávání podobnosti ve vysokodimenzionálních vektorových reprezentacích, široce používaná pro stavbu sémantických vyhledávačů pracujících s velkými datovými sadami.
Objevte, jak může sémantické vyhledávání poháněné AI změnit vaše informační vyhledávání, chatboty a automatizační workflow.
Vyhledávání informací využívá AI, NLP a strojové učení k efektivnímu a přesnému získávání dat, která odpovídají požadavkům uživatelů. Je základem webových vyhle...
Zjistěte, co je Insight Engine—pokročilá platforma poháněná AI, která zlepšuje vyhledávání a analýzu dat díky pochopení kontextu a záměru. Naučte se, jak Insigh...
Objevte, jak AI mění SEO automatizací analýzy klíčových slov, optimalizací obsahu a zapojením uživatelů. Prozkoumejte klíčové strategie, nástroje a budoucí tren...
