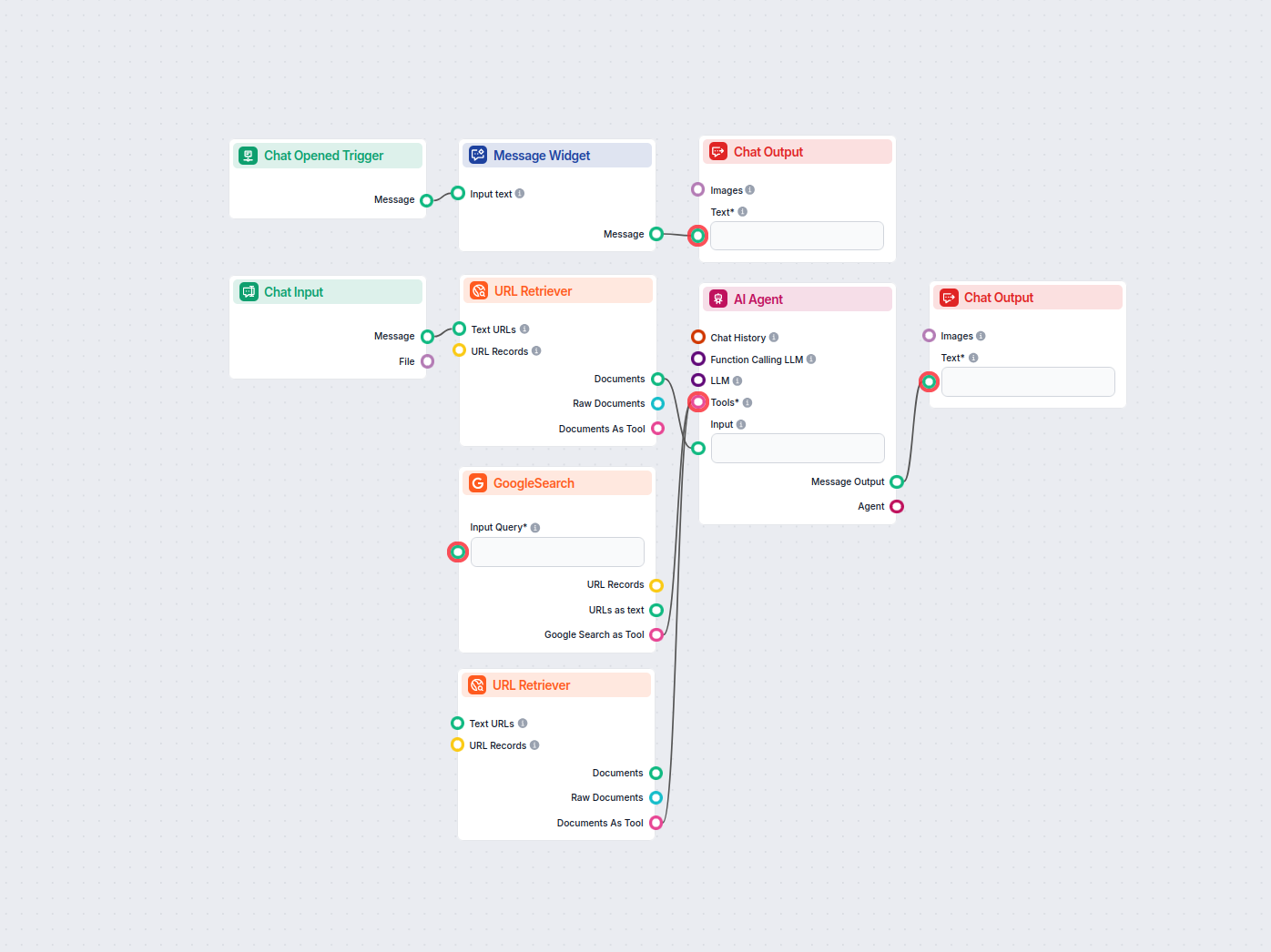
Sitemap na LLM.txt AI Konvertor
Proměňte sitemapu svého webu sitemap.xml automaticky do formátu dokumentace vhodného pro LLM. Tento nástroj využívající AI extrahuje, zpracuje a strukturuje váš...
2 min čtení
AI
Documentation
+4
llms.txt je Markdown soubor, který zjednodušuje obsah webu pro LLM a zlepšuje AI interakce poskytnutím strukturovaného, strojově čitelného indexu.
Soubor llms.txt je standardizovaný textový soubor ve formátu Markdown, navržený ke zlepšení způsobu, jakým velké jazykové modely (LLM) přistupují k informacím z webových stránek, rozumí jim a zpracovávají je. Umístěn v kořenové složce webu (například /llms.txt), tento soubor slouží jako kurátorovaný index, který poskytuje strukturovaný a zestručněný obsah speciálně optimalizovaný pro strojové zpracování při inferenci. Jeho hlavním cílem je obejít složitosti tradičního HTML obsahu – jako jsou navigační menu, reklamy a JavaScript – tím, že prezentuje jasná data čitelná pro lidi i stroje.
Na rozdíl od jiných webových standardů jako robots.txt nebo sitemap.xml je llms.txt určen výslovně pro rozumové AI enginy, jako jsou ChatGPT, Claude či Google Gemini, nikoli pro vyhledávače. Pomáhá AI systémům získávat pouze ty nejrelevantnější a nejhodnotnější informace v rámci omezení jejich kontextových oken, která často nestačí na celý obsah webu.
Koncept navrhl Jeremy Howard, spoluzakladatel Answer.AI, v září 2024. Vznikl jako řešení neefektivity, s níž se LLM potýkají při interakci se složitými weby. Tradiční způsoby zpracování HTML často vedou k plýtvání výpočetními zdroji a špatné interpretaci obsahu. Zavedením standardu jako llms.txt mohou majitelé webů zajistit, že jejich obsah bude AI systémy správně a efektivně zpracován.
Soubor llms.txt slouží především v oblasti umělé inteligence a AI interakcí řízených LLM. Jeho strukturovaný formát umožňuje efektivní vyhledávání a zpracování obsahu webu LLM, čímž překonává omezení velikosti kontextového okna a efektivity zpracování.
Soubor llms.txt se řídí specifickým schématem založeným na Markdownu, aby byla zaručena kompatibilita jak s lidmi, tak se stroji. Struktura zahrnuje:
Příklad:
# Ukázkový web
> Platforma pro sdílení znalostí a zdrojů o umělé inteligenci.
## Dokumentace
- [Průvodce rychlým startem](https://example.com/docs/quickstart.md): Průvodce pro začátečníky.
- [API Reference](https://example.com/docs/api.md): Podrobná dokumentace API.
## Pravidla
- [Podmínky užívání](https://example.com/terms.md): Právní podmínky používání platformy.
- [Zásady ochrany osobních údajů](https://example.com/privacy.md): Informace o zpracování dat a soukromí uživatelů.
## Volitelně
- [Historie společnosti](https://example.com/history.md): Časová osa důležitých milníků a úspěchů.
llms.txt nasměrovat AI na produktové kategorie, zásady vracení zboží a velikostní tabulky.FastHTML, Python knihovna pro tvorbu serverem renderovaných webových aplikací, používá llms.txt ke zjednodušení přístupu k dokumentaci. Soubor obsahuje odkazy na průvodce začátkem, reference HTMX a ukázkové aplikace, takže vývojáři rychle naleznou potřebné zdroje.
Ukázka:
# FastHTML
> Python knihovna pro tvorbu serverem renderovaných hypermediálních aplikací.
## Dokumentace
- [Rychlý start](https://fastht.ml/docs/quickstart.md): Přehled hlavních funkcí.
- [HTMX Reference](https://github.com/bigskysoftware/htmx/blob/master/www/content/reference.md): Kompletní atributy a metody HTMX.
E-commerce gigant jako Nike by mohl využít llms.txt k poskytnutí informací o svých produktových řadách, ekologických iniciativách a zákaznické podpoře AI systémům.
Ukázka:
# Nike
> Světový lídr ve sportovní obuvi a oblečení, kladoucí důraz na udržitelnost a inovace.
## Produktové řady
- [Běžecké boty](https://nike.com/products/running.md): Detaily o technologiích React foam a Vaporweave.
- [Ekologické iniciativy](https://nike.com/sustainability.md): Cíle pro rok 2025 a materiály šetrné k přírodě.
## Zákaznická podpora
- [Zásady vracení](https://nike.com/returns.md): 60denní lhůta na vrácení a výjimky.
- [Velikostní tabulky](https://nike.com/sizing.md): Přehled velikostí obuvi a oblečení.
Ačkoliv všechny tři standardy pomáhají automatizovaným systémům, jejich účel a cílové skupiny se výrazně liší.
llms.txt:
robots.txt:
sitemap.xml:
robots.txt a sitemap.xml je llms.txt navržen pro rozumové enginy, ne pro tradiční vyhledávače.llms.txt a llms-full.txt pro hostovanou dokumentaci.llms.txt.https://example.com/llms.txt).llms_txt2ctx, abyste zajistili soulad se standardem.llms.txt nebo llms-full.txt (např. Claude nebo ChatGPT).llms.txt získal oblibu mezi vývojáři a menšími platformami, zatím jej oficiálně nepodporují velcí poskytovatelé LLM jako OpenAI nebo Google.llms-full.txt překročit velikost kontextového okna některých LLM.I přes tyto výzvy představuje llms.txt progresivní přístup k optimalizaci obsahu pro AI systémy. Zavedením tohoto standardu si organizace zajistí, že jejich obsah bude v AI světě dostupný, přesný a upřednostňovaný.
Výzkum: Velké jazykové modely (LLM)
Velké jazykové modely (LLM) se staly klíčovou technologií pro zpracování přirozeného jazyka, pohánějící aplikace jako chatboty, moderaci obsahu a vyhledávače. Ve studii “Lost in Translation: Large Language Models in Non-English Content Analysis” od Nicholase a Bhatia (2023) autoři jasně technicky vysvětlují, jak LLM fungují, upozorňují na rozdíl v dostupnosti dat mezi angličtinou a ostatními jazyky a rozebírají snahy o překlenutí této mezery pomocí vícejazyčných modelů. Práce detailně popisuje výzvy analýzy obsahu pomocí LLM, zvláště v multilingválním prostředí, a nabízí doporučení výzkumníkům, firmám i tvůrcům politik ohledně nasazení a vývoje LLM. Zdůrazňuje, že navzdory pokroku zůstávají pro neanglické jazyky významná omezení. Přečíst článek
Práce “Cedille: A large autoregressive French language model” od Müllera a Laurenta (2022) představuje Cedille, rozsáhlý jazykový model zaměřený na francouzštinu. Cedille je open source a předvádí vynikající výsledky na francouzských zero-shot benchmarcích, v několika úlohách dokonce konkuruje GPT-3. Studie hodnotí i bezpečnost Cedille a ukazuje zlepšení v toxicitě díky filtrování datasetu. Tato práce zdůrazňuje důležitost jazykově specifických LLM a potřebu jazykových zdrojů v této oblasti. Přečíst článek
V článku “How Good are Commercial Large Language Models on African Languages?” od Ojo a Ogueji (2023) autoři hodnotí výkonnost komerčních LLM u afrických jazyků v překladech i klasifikaci textů. Zjišťují, že tyto modely mají obecně slabé výsledky v afrických jazycích, přičemž lepší výsledky dosahují v klasifikaci než v překladu. Analýza pokrývá osm afrických jazyků z různých rodin a regionů. Autoři vyzývají k většímu zastoupení afrických jazyků v komerčních LLM s ohledem na jejich rostoucí využití. Studie poukazuje na aktuální nedostatky a potřebu inkluzivnějšího vývoje jazykových modelů. Přečíst článek
“Goldfish: Monolingual Language Models for 350 Languages” od Chang a kol. (2024) zkoumá výkon jednojazyčných versus vícejazyčných modelů pro jazyky s málo daty. Výzkum ukazuje, že velké vícejazyčné modely často dosahují horších výsledků než jednoduché bigramové modely (měřeno FLORES perplexitou). Goldfish předkládá jednojazyčné modely pro 350 jazyků, které výrazně zlepšují výkon pro minoritní jazyky. Autoři podporují cílený vývoj modelů pro méně zastoupené jazyky. Práce přináší cenné poznatky o omezeních vícejazyčných LLM a potenciálu jednojazyčných alternativ. Přečíst článek
llms.txt je standardizovaný Markdown soubor umístěný v kořenovém adresáři webu (např. /llms.txt), který poskytuje kurátorovaný index obsahu optimalizovaného pro velké jazykové modely, což umožňuje efektivní AI interakce.
Na rozdíl od robots.txt (pro procházení vyhledávači) nebo sitemap.xml (pro indexaci) je llms.txt navržen pro LLM, nabízí zjednodušenou strukturu založenou na Markdownu k upřednostnění hodnotného obsahu pro AI zpracování.
Obsahuje H1 nadpis (název webu), shrnutí v blokové citaci, detailní sekce pro kontext, seznamy zdrojů oddělené H2 s odkazy a popisy a volitelnou sekci pro sekundární zdroje.
llms.txt navrhl Jeremy Howard, spoluzakladatel Answer.AI, v září 2024 jako odpověď na neefektivitu, se kterou LLM zpracovávají komplexní webový obsah.
llms.txt zvyšuje efektivitu LLM tím, že snižuje šum (např. reklamy, JavaScript), optimalizuje obsah pro kontextová okna a umožňuje přesné parsování pro aplikace jako technická dokumentace nebo e-commerce.
Lze jej napsat ručně v Markdownu nebo vygenerovat pomocí nástrojů jako Mintlify nebo Firecrawl. Ověřovací nástroje jako llms_txt2ctx zajistí soulad se standardem.
Zjistěte, jak implementovat llms.txt s FlowHunt a připravit svůj obsah pro AI a vylepšit interakci s velkými jazykovými modely.
Proměňte sitemapu svého webu sitemap.xml automaticky do formátu dokumentace vhodného pro LLM. Tento nástroj využívající AI extrahuje, zpracuje a strukturuje váš...
Otestovali jsme a seřadili schopnosti psaní 5 populárních modelů dostupných ve FlowHunt, abychom našli nejlepší LLM pro tvorbu obsahu.
Převádějte jakýkoli sitemap.xml do dobře strukturovaného formátu llms.txt pomocí AI. Tento workflow získává URL ze sitemapu, načítá a zpracovává jejich obsah a ...