
Strojové učení
Strojové učení (ML) je podmnožinou umělé inteligence (AI), která umožňuje strojům učit se z dat, rozpoznávat vzory, předpovídat a zlepšovat rozhodování v čase b...
3 min čtení
Machine Learning
AI
+4
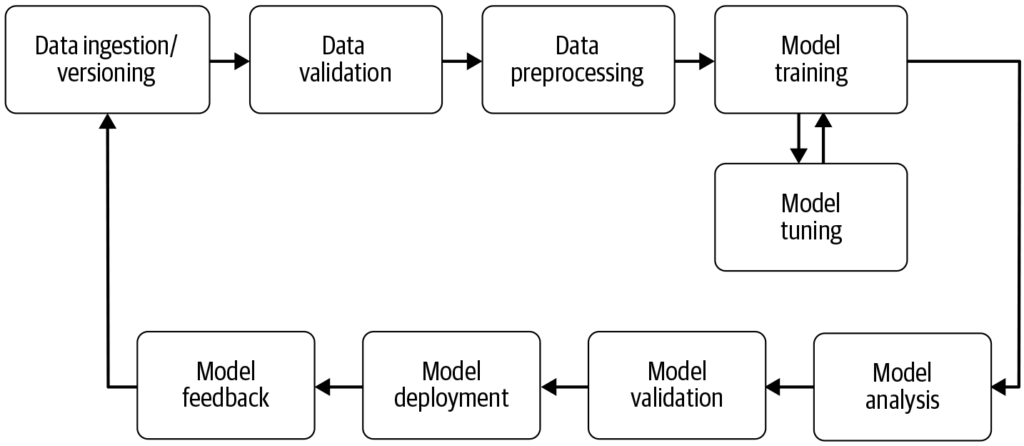
Pipeline strojového učení automatizuje kroky od sběru dat po nasazení modelu, čímž zvyšuje efektivitu, reprodukovatelnost a škálovatelnost v projektech strojového učení.
Pipeline strojového učení je automatizovaný pracovní postup, který zefektivňuje vývoj, trénování, vyhodnocování a nasazení modelů. Zvyšuje efektivitu, reprodukovatelnost a škálovatelnost, usnadňuje úkoly od sběru dat po nasazení a údržbu modelu.
Pipeline strojového učení je automatizovaný pracovní postup zahrnující řadu kroků potřebných pro vývoj, trénování, vyhodnocování a nasazení modelů strojového učení. Je navržena tak, aby zefektivnila a standardizovala procesy potřebné k přeměně surových dat na využitelné poznatky pomocí algoritmů strojového učení. Přístup s pipeline umožňuje efektivní zpracování dat, trénování modelů i jejich nasazení, což usnadňuje správu a škálování operací strojového učení.
Zdroj: Building Machine Learning
Sběr dat: Počáteční fáze, kdy jsou data shromažďována z různých zdrojů, jako jsou databáze, API nebo soubory. Sběr dat je systematická činnost zaměřená na získání smysluplných informací k vytvoření konzistentního a úplného datasetu pro daný podnikatelský účel. Tato surová data jsou zásadní pro stavbu modelů strojového učení, ale často vyžadují předzpracování, aby byla užitečná. Jak uvádí AltexSoft, sběr dat zahrnuje systematické shromažďování informací na podporu analytiky a rozhodování. Tento proces je klíčový, protože tvoří základ pro všechny další kroky v pipeline a často je kontinuální, aby byly modely trénovány na relevantních a aktuálních datech.
Předzpracování dat: Surová data jsou očištěna a převedena do vhodného formátu pro trénování modelu. Běžné kroky zahrnují řešení chybějících hodnot, kódování kategoriálních proměnných, škálování numerických znaků a rozdělení dat na trénovací a testovací sady. Tato fáze zajišťuje, že data mají správný formát a jsou zbavená nekonzistencí, které by mohly ovlivnit výkon modelu.
Tvorba příznaků (feature engineering): Vytváření nových příznaků nebo výběr relevantních příznaků z dat za účelem zvýšení prediktivní síly modelu. Tento krok může vyžadovat oborové znalosti a kreativitu. Feature engineering je kreativní proces, který převádí surová data na smysluplné příznaky lépe vystihující základní problém a zvyšující výkon modelů strojového učení.
Výběr modelu: Výběr vhodného algoritmu strojového učení na základě typu úlohy (např. klasifikace, regrese), charakteru dat a požadavků na výkon. V této fázi může probíhat také ladění hyperparametrů. Výběr správného modelu je zásadní, protože ovlivňuje přesnost a efektivitu predikcí.
Trénování modelu: Vybraný model (nebo modely) je trénován na trénovací datasetu. To zahrnuje učení vzorů a vztahů v datech. Místo trénování nového modelu lze využít i předtrénované modely. Trénování je zásadní krok, kdy se model učí z dat a získává schopnost dělat informovaná rozhodnutí.
Vyhodnocení modelu: Po trénování je výkon modelu otestován na odděleném testovacím datasetu nebo pomocí křížové validace. Metody vyhodnocení závisí na konkrétní úloze, ale mohou zahrnovat přesnost, preciznost, recall, F1 skóre, střední kvadratickou chybu a další. Tento krok je důležitý pro zajištění dobrého výkonu modelu na neznámých datech.
Nasazení modelu: Po vývoji a vyhodnocení uspokojivého modelu může být nasazen do produkčního prostředí pro predikce na nových, dosud neznámých datech. Nasazení může zahrnovat tvorbu API a integraci s dalšími systémy. Nasazení je závěrečnou fází pipeline, kde je model zpřístupněn pro reálné použití.
Monitoring a údržba: Po nasazení je klíčové kontinuálně sledovat výkon modelu a podle potřeby jej přeškolovat, aby se přizpůsobil měnícím se vzorcům v datech. To zajišťuje, že model zůstává přesný a spolehlivý v reálném prostředí. Tento průběžný proces zajišťuje aktuálnost a relevanci modelu i v čase.
Zpracování přirozeného jazyka (NLP): NLP úlohy často zahrnují opakující se kroky, jako je načítání dat, čištění textu, tokenizace a analýza sentimentu. Pipeline tyto kroky modularizují a umožňují snadné úpravy a aktualizace bez ovlivnění ostatních komponent.
Prediktivní údržba: Ve výrobě lze pipeline využít k predikci poruch zařízení analýzou dat ze senzorů, což umožňuje proaktivní údržbu a snižuje prostoje.
Finance: Pipeline může automatizovat zpracování finančních dat pro detekci podvodů, hodnocení úvěrových rizik nebo predikci cen akcií, čímž zvyšuje efektivitu rozhodovacích procesů.
Zdravotnictví: Ve zdravotnictví mohou pipeline zpracovávat medicínské snímky nebo záznamy pacientů a pomáhat v diagnostice či predikci výsledků léčby, což zlepšuje strategie péče.
Pipeline strojového učení jsou nedílnou součástí AI a automatizace, protože poskytují strukturovaný rámec pro automatizaci úloh strojového učení. V oblasti automatizace AI pipeline zajišťují efektivní trénování a nasazení modelů, což umožňuje systémům jako [chatboty] učit se a přizpůsobovat novým datům bez manuálního zásahu. Tato automatizace je klíčová pro škálování AI aplikací a zajištění jejich konzistentního a spolehlivého výkonu v různých oblastech. Využitím pipeline mohou organizace posílit své AI schopnosti a zajistit, že jejich modely strojového učení zůstanou relevantní a efektivní i v proměnlivém prostředí.
Výzkum pipeline strojového učení
“Deep Pipeline Embeddings for AutoML” od Sebastiana Pineda Arango a Josifa Grabocky (2023) se zaměřuje na optimalizaci pipeline strojového učení v rámci automatizovaného strojového učení (AutoML). Práce představuje novou neuronovou architekturu, která zachycuje hluboké interakce mezi jednotlivými komponentami pipeline. Autoři navrhují vkládání pipeline do latentních reprezentací pomocí unikátního enkodéru pro každou komponentu. Tyto embeddingy jsou pak využity v rámci bayesovské optimalizace pro hledání optimálních pipeline. Práce zdůrazňuje využití meta-learningu pro doladění parametrů embeddingové sítě pipeline a ukazuje špičkové výsledky v optimalizaci pipeline na více datasetech. Více zde.
“AVATAR — Machine Learning Pipeline Evaluation Using Surrogate Model” od Tien-Dung Nguyena a kol. (2020) se zabývá časově náročným vyhodnocováním pipeline během AutoML procesů. Studie kritizuje tradiční metody, jako jsou bayesovská a genetická optimalizace, za jejich neefektivnost. Autoři představují AVATAR, surrogátní model pro efektivní vyhodnocování validity pipeline bez jejího spuštění. Tento přístup výrazně urychluje sestavování a optimalizaci složitých pipeline tím, že včas vyřazuje neplatné pipeline. Více zde.
“Data Pricing in Machine Learning Pipelines” od Zicun Conga a kol. (2021) zkoumá zásadní roli dat v pipeline strojového učení a potřebu oceňování dat za účelem spolupráce více stran. Práce shrnuje nejnovější vývoj v oblasti oceňování dat v kontextu pipeline strojového učení, se zaměřením na jeho význam v různých fázích pipeline. Přináší vhled do strategií oceňování pro sběr trénovacích dat, kolaborativní trénink modelů a poskytování služeb strojového učení, přičemž zdůrazňuje tvorbu dynamického ekosystému. Více zde.
Pipeline strojového učení je automatizovaná sekvence kroků – od sběru a předzpracování dat přes trénování modelu, jeho vyhodnocení až po nasazení – která zefektivňuje a standardizuje proces vytváření a správy modelů strojového učení.
Klíčové komponenty zahrnují sběr dat, předzpracování dat, tvorbu příznaků (feature engineering), výběr modelu, trénování modelu, vyhodnocení modelu, nasazení modelu a průběžné monitorování a údržbu.
Pipeline strojového učení přinášejí modularizaci, efektivitu, reprodukovatelnost, škálovatelnost, lepší spolupráci a snadnější nasazení modelů do produkčního prostředí.
Příklady použití zahrnují zpracování přirozeného jazyka (NLP), prediktivní údržbu ve výrobě, finanční hodnocení rizik a detekci podvodů a diagnostiku ve zdravotnictví.
Výzvy zahrnují zajištění kvality dat, správu složitosti pipeline, integraci se stávajícími systémy a kontrolu nákladů spojených s výpočetními zdroji a infrastrukturou.
Naplánujte si demo a zjistěte, jak vám FlowHunt může pomoci automatizovat a škálovat pracovní postupy strojového učení jednoduše.
Strojové učení (ML) je podmnožinou umělé inteligence (AI), která umožňuje strojům učit se z dat, rozpoznávat vzory, předpovídat a zlepšovat rozhodování v čase b...
Učené učení je základní koncept umělé inteligence a strojového učení, při kterém jsou algoritmy trénovány na označených datech za účelem přesných předpovědí neb...
MLflow je open-source platforma navržená pro zjednodušení a správu životního cyklu strojového učení (ML). Poskytuje nástroje pro sledování experimentů, balení k...
