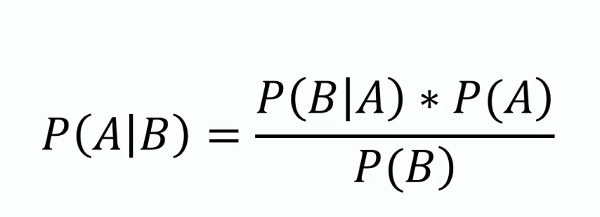
Bayesovské sítě
Bayesovská síť (BN) je pravděpodobnostní grafický model, který reprezentuje proměnné a jejich podmíněné závislosti pomocí orientovaného acyklického grafu (DAG)....
3 min čtení
Bayesian Networks
AI
+3
Naivní Bayes je jednoduchá, ale výkonná rodina klasifikačních algoritmů využívající Bayesův teorém, běžně používaná pro škálovatelné úlohy jako detekce spamu a klasifikace textu.
Naivní Bayes je rodina jednoduchých a efektivních klasifikačních algoritmů založených na Bayesově teorému s předpokladem podmíněné nezávislosti mezi příznaky. Díky své jednoduchosti a škálovatelnosti se hojně využívá při detekci spamu, klasifikaci textu a dalších úlohách.
Naivní Bayes je rodina klasifikačních algoritmů založených na Bayesově teorému, který využívá princip podmíněné pravděpodobnosti. Označení „naivní“ odkazuje na zjednodušující předpoklad, že všechny příznaky v datové sadě jsou vzhledem k třídnímu štítku podmíněně nezávislé. Přestože je tento předpoklad v reálných datech často porušován, jsou Naivní Bayesovy klasifikátory uznávány pro svou jednoduchost a efektivitu v různých aplikacích, jako je klasifikace textu a detekce spamu.
Bayesův teorém
Tento teorém tvoří základ Naivního Bayese a poskytuje způsob, jak aktualizovat odhad pravděpodobnosti hypotézy při získání nových důkazů či informací. Matematicky je vyjádřen jako:
kde ( P(A|B) ) je posteriorní pravděpodobnost, ( P(B|A) ) je pravděpodobnost, ( P(A) ) je apriorní pravděpodobnost a ( P(B) ) je důkaz.
Podmíněná nezávislost
Naivní předpoklad, že každý příznak je nezávislý na všech ostatních příznacích vzhledem k třídnímu štítku. Tento předpoklad zjednodušuje výpočty a umožňuje algoritmu dobře škálovat na velké datové sady.
Posteriorní pravděpodobnost
Pravděpodobnost třídního štítku vzhledem k hodnotám příznaků, vypočítaná pomocí Bayesova teorému. Je to klíčová složka při předpovídání pomocí Naivního Bayese.
Typy Naivních Bayesových klasifikátorů
Naivní Bayesovy klasifikátory fungují tak, že pro každou třídu vypočítají posteriorní pravděpodobnost na základě daných příznaků a zvolí třídu s nejvyšší posteriorní pravděpodobností. Postup zahrnuje následující kroky:
Naivní Bayesovy klasifikátory jsou obzvlášť efektivní v následujících oblastech:
Představme si aplikaci na filtrování spamu využívající Naivní Bayes. Trénovací data tvoří e-maily označené jako „spam“ nebo „ne-spam“. Každý e-mail je reprezentován sadou příznaků, například přítomností konkrétních slov. Během trénování algoritmus vypočítá pravděpodobnost výskytu každého slova vzhledem k třídnímu štítku. U nového e-mailu pak algoritmus spočítá posteriorní pravděpodobnosti pro „spam“ i „ne-spam“ a přiřadí štítek s vyšší pravděpodobností.
Naivní Bayesovy klasifikátory lze integrovat do AI systémů a chatbotů pro posílení jejich schopností zpracování přirozeného jazyka a zlepšení interakce člověk–počítač. Například lze použít k detekci záměru uživatelských dotazů, klasifikaci textů do předem definovaných kategorií nebo filtrování nevhodného obsahu. Tato funkcionalita zvyšuje kvalitu a relevanci odpovědí AI řešení. Díky své efektivitě je algoritmus vhodný i pro aplikace v reálném čase, což je důležité pro automatizaci a chatbot systémy.
Naivní Bayes je rodina jednoduchých, ale výkonných pravděpodobnostních algoritmů založených na aplikaci Bayesova teorému se silnými předpoklady nezávislosti mezi příznaky. Díky své jednoduchosti a efektivitě je široce využíván pro klasifikační úlohy. Zde je několik vědeckých článků, které pojednávají o různých aplikacích a vylepšeních Naivního Bayesova klasifikátoru:
Zlepšení filtrování spamu kombinací Naivního Bayese s jednoduchým vyhledáváním nejbližších sousedů
Autor: Daniel Etzold
Publikováno: 30. listopadu 2003
Tento článek zkoumá využití Naivního Bayese pro klasifikaci e-mailů, zdůrazňuje jeho snadnou implementaci a efektivitu. Studie prezentuje empirické výsledky, jak kombinace Naivního Bayese s vyhledáváním nejbližších sousedů může zvýšit přesnost filtrování spamu. Kombinace přinesla mírné zlepšení přesnosti při velkém počtu příznaků a výrazné zlepšení při menším počtu příznaků. Přečíst článek.
Lokálně vážený Naivní Bayes
Autoři: Eibe Frank, Mark Hall, Bernhard Pfahringer
Publikováno: 19. října 2012
Tento článek se zabývá hlavní slabinou Naivního Bayese, kterou je předpoklad nezávislosti atributů. Představuje lokálně váženou verzi Naivního Bayese, která se učí lokální modely při predikci a tím uvolňuje předpoklad nezávislosti. Experimentální výsledky ukazují, že tento přístup zřídka snižuje přesnost a často ji významně zlepšuje. Metoda je oceňována pro svou koncepční i výpočetní jednoduchost oproti jiným technikám. Přečíst článek.
Detekce uvíznutí planetárních roverů pomocí Naivního Bayese
Autor: Dicong Qiu
Publikováno: 31. ledna 2018
Tato studie se zabývá aplikací Naivního Bayese pro detekci uvíznutí planetárních roverů. Definuje kritéria pro uvíznutí roveru a demonstruje využití Naivního Bayese pro detekci těchto scénářů. Článek popisuje experimenty prováděné s roboty AutoKrawler a poskytuje vhled do efektivity Naivního Bayese pro autonomní záchranné procedury. Přečíst článek.
Naivní Bayes je rodina klasifikačních algoritmů založených na Bayesově teorému, která předpokládá, že všechny příznaky jsou podmíněně nezávislé vzhledem k třídnímu štítku. Široce se používá pro klasifikaci textu, filtrování spamu a analýzu sentimentu.
Hlavními typy jsou Gaussovský Naivní Bayes (pro spojité příznaky), Multinomický Naivní Bayes (pro diskrétní příznaky jako počty slov) a Bernoulliho Naivní Bayes (pro binární/booleovské příznaky).
Naivní Bayes je snadný na implementaci, výpočetně efektivní, škálovatelný na velké datové sady a dobře zvládá data s vysokou dimenzionalitou.
Hlavním omezením je předpoklad nezávislosti příznaků, který často u reálných dat neplatí. Také může přiřadit nulovou pravděpodobnost neviděným příznakům, což lze zmírnit technikami jako je Laplaceovo vyhlazování.
Naivní Bayes se v AI systémech a chatbotech používá pro detekci záměru, klasifikaci textu, filtrování spamu a analýzu sentimentu, čímž posiluje schopnosti zpracování přirozeného jazyka a umožňuje rozhodování v reálném čase.
Chytří chatboti a AI nástroje pod jednou střechou. Propojte intuitivní bloky a proměňte své nápady v automatizované toky.
Bayesovská síť (BN) je pravděpodobnostní grafický model, který reprezentuje proměnné a jejich podmíněné závislosti pomocí orientovaného acyklického grafu (DAG)....
AI klasifikátor je algoritmus strojového učení, který přiřazuje vstupním datům třídy, kategorizuje informace do předem definovaných tříd na základě naučených vz...
Neuromorfní výpočetní technika je špičkový přístup k počítačovému inženýrství, který modeluje jak hardwarové, tak softwarové prvky podle lidského mozku a nervov...