
Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation (RAG) je pokročilý AI framework, který kombinuje tradiční systémy pro vyhledávání informací s generativními velkými jazykovými mo...
3 min čtení
RAG
AI
+4

Odpovídání na otázky s RAG vylepšuje LLM integrací vyhledávání v reálném čase a generování přirozeného jazyka pro přesné, kontextově relevantní odpovědi.
Odpovídání na otázky s Retrieval-Augmented Generation (RAG) vylepšuje jazykové modely integrací externích dat v reálném čase pro přesné a relevantní odpovědi. Optimalizuje výkon v dynamických oblastech a přináší vyšší přesnost, dynamický obsah a zvýšenou relevanci.
Odpovídání na otázky s Retrieval-Augmented Generation (RAG) je inovativní metoda, která spojuje silné stránky vyhledávání informací a generování přirozeného jazyka – vytváří lidsky znějící text z dat, čímž vylepšuje AI, chatboty, reporty i personalizaci zážitků. Tento hybridní přístup rozšiřuje možnosti velkých jazykových modelů (LLM) tím, že jejich odpovědi doplňuje o relevantní a aktuální informace získané z externích datových zdrojů. Na rozdíl od tradičních metod, které spoléhají pouze na předtrénované modely, RAG dynamicky integruje externí data, což umožňuje poskytovat přesnější a kontextově vhodnější odpovědi – obzvlášť v oblastech, kde jsou potřeba nejnovější informace nebo specializované znalosti.
RAG optimalizuje výkon LLM tím, že odpovědi nejsou generovány jen z interní databáze, ale jsou podloženy i aktuálními a autoritativními zdroji. Tento přístup je zásadní pro úkoly odpovídání na otázky v dynamických oborech, kde se informace neustále vyvíjejí.
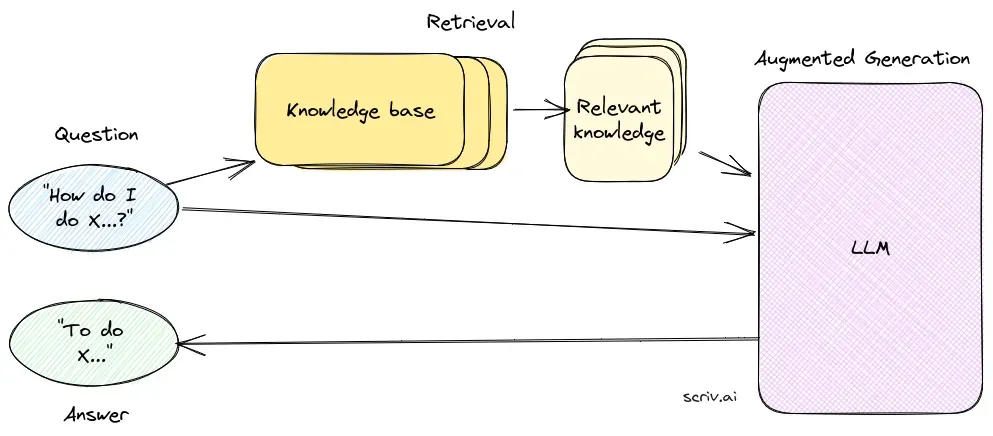
Vyhledávací komponenta zajišťuje získávání relevantních informací z rozsáhlých datových sad, obvykle uložených ve vektorové databázi. Využívá sémantické vyhledávání k identifikaci a extrakci textových úryvků nebo dokumentů, které jsou vysoce relevantní k dotazu uživatele.
Generační komponenta, obvykle LLM jako GPT-3 či BERT, syntetizuje odpověď kombinací původního dotazu uživatele se získaným kontextem. Je klíčová pro generování koherentních a kontextově vhodných odpovědí.
Implementace systému RAG zahrnuje několik technických kroků:
Výzkum v oblasti odpovídání na otázky s Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) je metoda, která vylepšuje systémy odpovídání na otázky kombinací vyhledávacích mechanismů s generativními modely. Nedávný výzkum zkoumá účinnost a optimalizaci RAG v různých kontextech.
RAG je metoda, která kombinuje vyhledávání informací a generování přirozeného jazyka, aby poskytovala přesné a aktuální odpovědi integrací externích datových zdrojů do velkých jazykových modelů.
Systém RAG se skládá z vyhledávací komponenty, která získává relevantní informace z vektorových databází pomocí sémantického vyhledávání, a generovací komponenty, obvykle LLM, která syntetizuje odpovědi na základě dotazu uživatele i získaného kontextu.
RAG zvyšuje přesnost vyhledáváním kontextově relevantních informací, podporuje dynamickou aktualizaci obsahu z externích znalostních bází a zlepšuje relevanci a kvalitu generovaných odpovědí.
Běžné využití zahrnuje AI chatboty, zákaznickou podporu, automatizovanou tvorbu obsahu a vzdělávací nástroje, které vyžadují přesné, kontextově závislé a aktuální odpovědi.
Systémy RAG mohou být náročné na zdroje, vyžadují pečlivou integraci pro optimální výkon a je nutné zajistit faktickou přesnost získaných informací, aby se předešlo zavádějícím nebo zastaralým odpovědím.
Zjistěte, jak může Retrieval-Augmented Generation posílit vaše chatboty a podporu díky přesným odpovědím v reálném čase.
Retrieval Augmented Generation (RAG) je pokročilý AI framework, který kombinuje tradiční systémy pro vyhledávání informací s generativními velkými jazykovými mo...
Objevte klíčové rozdíly mezi Retrieval-Augmented Generation (RAG) a Cache-Augmented Generation (CAG) v AI. Zjistěte, jak RAG dynamicky vyhledává aktuální inform...
Přerovnání dokumentů je proces přeřazení nalezených dokumentů na základě jejich relevance k uživatelskému dotazu, což zpřesňuje výsledky vyhledávání a zvýrazňuj...

