Chatbot RAG v reálném čase pro konkrétní doménu
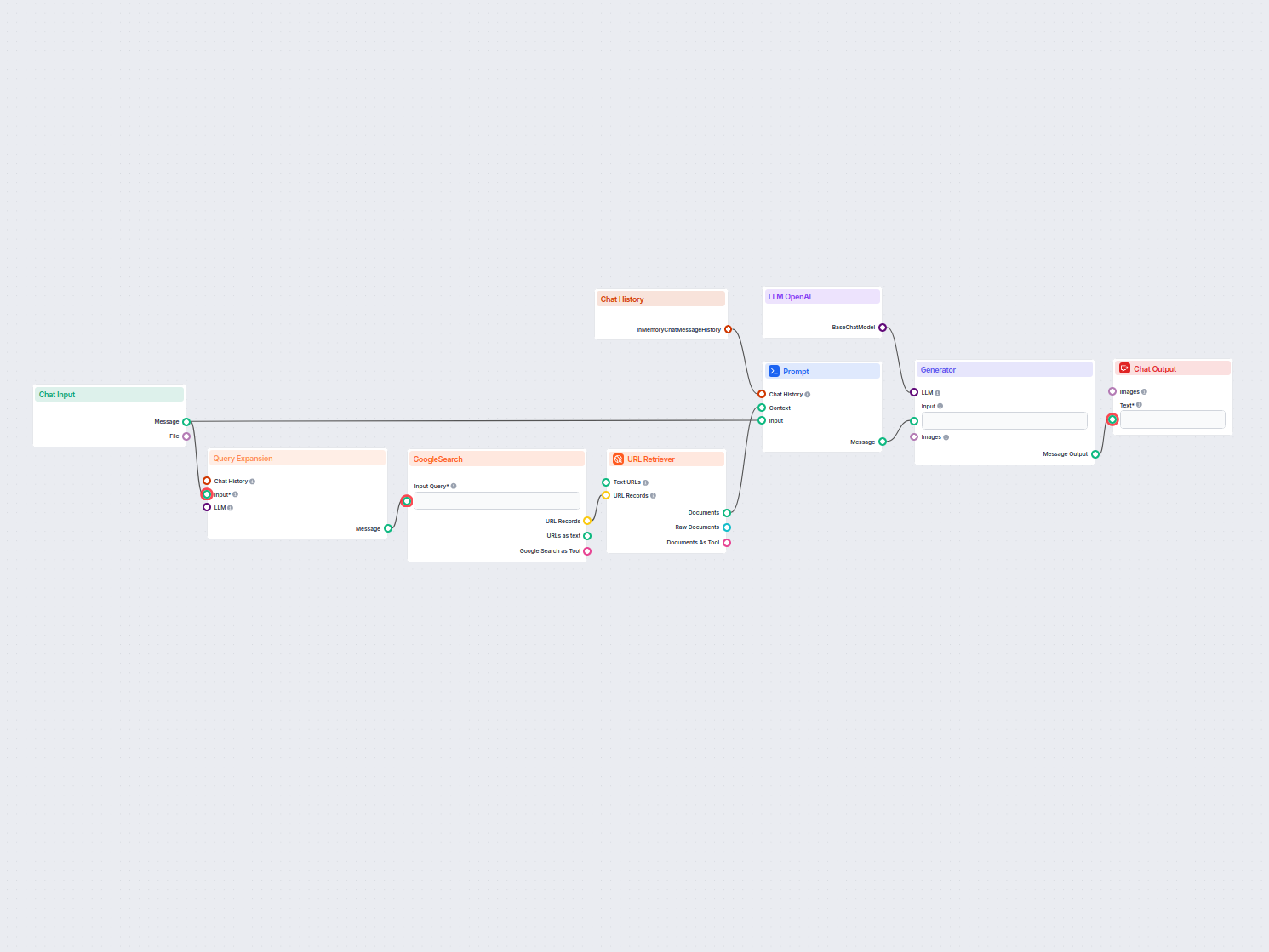
Chatbot v reálném čase, který využívá Google Search omezený na vaši vlastní doménu, získává relevantní webový obsah a pomocí OpenAI LLM odpovídá na dotazy uživa...
4 min čtení
Vyhledávací pipeline umožňuje chatbotům získávat a zpracovávat relevantní externí znalosti pro přesné, aktuální a kontextově zaměřené odpovědi pomocí RAG, embeddingů a vektorových databází.
Vyhledávací pipeline pro chatboty označuje technickou architekturu a proces, které umožňují chatbotům získávat, zpracovávat a vyhledávat relevantní informace v reakci na dotazy uživatelů. Na rozdíl od jednoduchých systémů otázek a odpovědí, které se spoléhají pouze na předtrénované jazykové modely, vyhledávací pipelines začleňují externí znalostní báze nebo datové zdroje. Díky tomu může chatbot poskytovat přesné, kontextově vhodné a aktuální odpovědi i v případě, že data nejsou přímo součástí samotného jazykového modelu.
Typická vyhledávací pipeline se skládá z několika částí, jako je ingestování dat, tvorba embeddingů, vektorové úložiště, vyhledávání kontextu a generování odpovědi. V praxi se často využívá Retrieval-Augmented Generation (RAG), která kombinuje silné stránky systémů pro vyhledávání dat a velkých jazykových modelů (LLM) pro generování odpovědí.
Vyhledávací pipeline rozšiřuje možnosti chatbota tím, že umožňuje:
Ingestování dokumentů
Sběr a předzpracování surových dat, která mohou zahrnovat PDF, textové soubory, databáze nebo API. Nástroje jako LangChain či LlamaIndex často usnadňují ingestování dat.
Příklad: Nahrání FAQ zákaznické podpory nebo specifikací produktů do systému.
Předzpracování dokumentů
Dlouhé dokumenty se rozdělují na menší, sémanticky smysluplné části, což je důležité pro použití v embeddingových modelech s omezením na počet tokenů (např. 512 tokenů).
Ukázka kódu:
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = text_splitter.split_documents(document_list)
Generování embeddingů
Textová data se převádějí do vektorových reprezentací pomocí embeddingových modelů. Embeddingy číselně kódují sémantický význam dat.
Příklad embeddingového modelu: OpenAI text-embedding-ada-002 nebo Hugging Face e5-large-v2.
Vektorové úložiště
Embeddingy se ukládají do vektorových databází optimalizovaných pro hledání podobností. Často se používají nástroje jako Milvus, Chroma nebo PGVector.
Příklad: Uložení popisů produktů a jejich embeddingů pro efektivní vyhledání.
Zpracování dotazů
Při doručení dotazu uživatele se tento převede na vektor dotazu stejným embeddingovým modelem. To umožňuje sémantické porovnání s uloženými embeddingy.
Ukázka kódu:
query_vector = embedding_model.encode("Jaké jsou technické specifikace produktu X?")
retrieved_docs = vector_db.similarity_search(query_vector, k=5)
Vyhledání dat
Systém získá nejrelevantnější části dat na základě skóre podobnosti (např. kosinová podobnost). Multimodální vyhledávání může kombinovat SQL databáze, znalostní grafy a vektorové vyhledávání pro robustnější výsledky.
Generování odpovědi
Získaná data se spojí s dotazem uživatele a předají velkému jazykovému modelu (LLM) k vytvoření finální odpovědi v přirozeném jazyce. Tento krok se často označuje jako augmentované generování.
Ukázka šablony promptu:
prompt_template = """
Kontext: {context}
Otázka: {question}
Prosím, poskytněte podrobnou odpověď s využitím výše uvedeného kontextu.
"""
Následné zpracování a validace
Pokročilé pipelines obsahují detekci halucinací, kontrolu relevance nebo hodnocení odpovědí, aby byl výstup faktický a relevantní.
Zákaznická podpora
Chatbot může získávat návody, průvodce řešením problémů nebo FAQ pro rychlé odpovědi na dotazy zákazníků.
Příklad: Chatbot pomáhající zákazníkovi resetovat router vyhledáním příslušné části uživatelské příručky.
Podniková správa znalostí
Interní chatboty mohou přistupovat ke specifickým firemním datům, jako jsou HR směrnice, IT dokumentace nebo pravidla compliance.
Příklad: Zaměstnanec se ptá interního chatbota na pravidla pro nemocenskou dovolenou.
E-commerce
Chatboty pomáhají uživatelům získat informace o produktech, recenze nebo dostupnost skladových zásob.
Příklad: „Jaké jsou hlavní vlastnosti produktu Y?“
Zdravotnictví
Chatbot získává lékařskou literaturu, doporučení nebo pacientská data pro podporu zdravotníků či pacientů.
Příklad: Chatbot vyhledá upozornění na lékové interakce z farmaceutické databáze.
Vzdělávání a výzkum
Akademické chatboty využívají RAG pipelines pro vyhledání vědeckých článků, odpovědi na dotazy nebo sumarizaci výzkumných výsledků.
Příklad: „Můžete shrnout závěry této studie o změně klimatu z roku 2023?“
Právo a compliance
Chatbot vyhledává právní dokumenty, judikaturu nebo požadavky na shodu pro podporu právníků.
Příklad: „Jaká je poslední aktualizace GDPR?“
Chatbot vytvořený pro odpovídání na otázky z výroční finanční zprávy společnosti ve formátu PDF.
Chatbot kombinující SQL, vektorové vyhledávání a znalostní grafy pro zodpovězení dotazu zaměstnance.
Díky využití vyhledávacích pipelines nejsou chatboty omezeny pouze na statická tréninková data a mohou poskytovat dynamickou, přesnou a kontextově bohatou interakci.
Vyhledávací pipelines hrají klíčovou roli v moderních chatbot systémech, které umožňují inteligentní a kontextově citlivé interakce.
„Lingke: A Fine-grained Multi-turn Chatbot for Customer Service“ – Pengfei Zhu a kol. (2018)
Představuje Lingke, chatbota, který integruje vyhledávání informací pro zvládání vícekrokových konverzací. Využívá detailní pipeline zpracování pro získávání odpovědí z nestrukturovaných dokumentů a zaměřuje se na přesné párování kontextu a odpovědi pro sekvenční interakce, což výrazně zlepšuje schopnost chatbota reagovat na složité uživatelské dotazy.
Přečtěte si článek zde.
„FACTS About Building Retrieval Augmented Generation-based Chatbots“ – Rama Akkiraju a kol. (2024)
Zkoumá výzvy a metodiky při vývoji podnikových chatbotů s využitím Retrieval Augmented Generation (RAG) pipelines a velkých jazykových modelů (LLM). Autoři navrhují rámec FACTS, který zdůrazňuje čerstvost dat, architekturu, náklady, testování a bezpečnost při návrhu RAG pipelines. Jejich empirické poznatky ukazují na kompromisy mezi přesností a latencí při škálování LLM a přinášejí cenné poznatky pro tvorbu bezpečných a výkonných chatbotů. Přečtěte si článek zde.
„From Questions to Insightful Answers: Building an Informed Chatbot for University Resources“ – Subash Neupane a kol. (2024)
Představuje BARKPLUG V.2, systém chatbota navržený pro univerzitní prostředí. Využitím RAG pipelines systém poskytuje přesné a oborově specifické odpovědi uživatelům na otázky týkající se univerzitních zdrojů a zlepšuje přístup k informacím. Studie hodnotí efektivitu chatbota pomocí frameworků jako RAG Assessment (RAGAS) a ukazuje jeho použitelnost v akademickém prostředí. Přečtěte si článek zde.
Vyhledávací pipeline je technická architektura, která umožňuje chatbotům získávat, zpracovávat a vyhledávat relevantní informace z externích zdrojů v reakci na dotazy uživatelů. Kombinuje ingestování dat, embedding, vektorové úložiště a generování odpovědí pomocí LLM pro dynamické, kontextové odpovědi.
RAG spojuje silné stránky vyhledávacích systémů a velkých jazykových modelů (LLM), což umožňuje chatbotům zakládat odpovědi na faktických, aktuálních externích datech, čímž snižuje halucinace a zvyšuje přesnost.
Klíčové komponenty zahrnují ingestování dokumentů, předzpracování, generování embeddingů, vektorové úložiště, zpracování dotazů, vyhledání dat, generování odpovědí a následnou validaci.
Příklady použití zahrnují zákaznickou podporu, podnikovou správu znalostí, informace o produktech v e-commerce, zdravotnické poradenství, vzdělávání a výzkum či podporu souladu s legislativou.
Výzvy zahrnují latenci při vyhledávání v reálném čase, provozní náklady, otázky ochrany dat a požadavky na škálovatelnost při práci s velkým objemem dat.
Odemkněte sílu Retrieval-Augmented Generation (RAG) a integrace externích dat pro inteligentní a přesné odpovědi chatbotů. Vyzkoušejte platformu FlowHunt bez kódu ještě dnes.
Chatbot v reálném čase, který využívá Google Search omezený na vaši vlastní doménu, získává relevantní webový obsah a pomocí OpenAI LLM odpovídá na dotazy uživa...
Objevte šablonu Jednoduchého chatbota s Google Search, navrženou pro firmy k efektivnímu poskytování doménově specifických informací. Zvyšte uživatelský zážitek...
Zdroje znalostí usnadňují přizpůsobení AI vašim potřebám. Objevte všechny možnosti propojení znalostí s FlowHunt. Jednoduše propojte weby, dokumenty a videa pro...