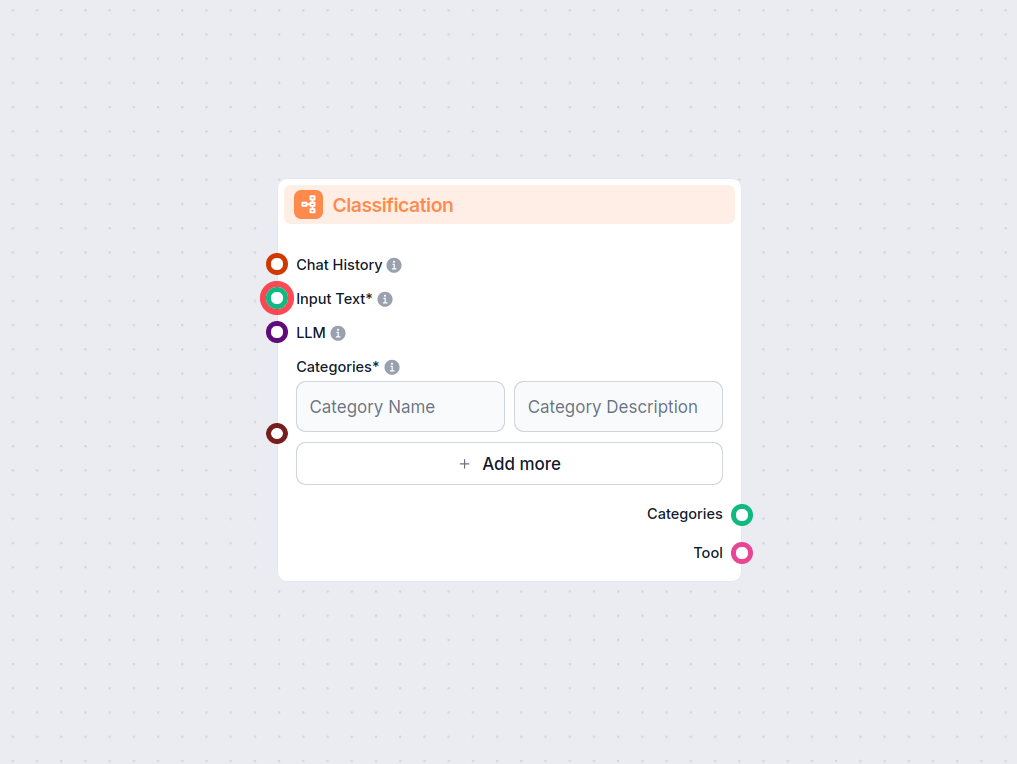
Klasifikace textu
Odemkněte automatizované kategorizování textu ve vašich workflowech pomocí komponenty Klasifikace textu pro FlowHunt. Snadno zařazujte vstupní text do uživatele...
2 min čtení
AI
Classification
+3
Klasifikace textu využívá NLP a strojové učení k automatickému přiřazení kategorií textu, což pohání aplikace jako analýza sentimentu, detekce spamu a organizace dat.
Klasifikace textu, známá také jako kategorizace nebo označování textu, je základní úkol zpracování přirozeného jazyka (NLP), který spočívá v přiřazení předem definovaných kategorií textovým dokumentům. Tato metoda organizuje, strukturuje a kategorizuje nestrukturovaná textová data, což usnadňuje jejich analýzu a interpretaci. Klasifikace textu se využívá v různých aplikacích, včetně analýzy sentimentu, detekce spamu a kategorizace témat.
Podle AWS slouží klasifikace textu jako první krok při organizaci, strukturování a kategorizaci dat pro další analytiku. Umožňuje automatické označování a kategorizaci dokumentů, což firmám umožňuje efektivně spravovat a analyzovat velké objemy textových dat. Tato schopnost automatizovat označování dokumentů snižuje potřebu manuálních zásahů a zvyšuje efektivitu procesů řízených daty.
Klasifikace textu je poháněná strojovým učením, kde jsou AI modely trénovány na označených datových sadách, aby se naučily vzorce a souvislosti mezi textovými znaky a jejich příslušnými kategoriemi. Po natrénování mohou tyto modely klasifikovat nové a dosud neviděné textové dokumenty s vysokou přesností a efektivitou. Jak uvádí Towards Data Science, tento proces zjednodušuje organizaci obsahu, díky čemuž je pro uživatele snazší vyhledávat a orientovat se na webu nebo v aplikacích.
Modely klasifikace textu jsou algoritmy, které automatizují kategorizaci textových dat. Tyto modely se učí z příkladů v trénovací datové sadě a aplikují získané znalosti na klasifikaci nových textových vstupů. Mezi oblíbené modely patří:
Support Vector Machines (SVM): Supervizovaný algoritmus vhodný pro binární i vícetřídní klasifikaci. SVM identifikuje hyperrovinu, která nejlépe odděluje body různých kategorií. Tato metoda je vhodná tam, kde je potřeba jasně definovat rozhodovací hranici.
Naivní Bayes: Pravděpodobnostní klasifikátor využívající Bayesovu větu s předpokladem nezávislosti znaků. Je zvláště efektivní u velkých datových sad díky své jednoduchosti a rychlosti. Naivní Bayes se hojně využívá v detekci spamu a textové analytice, kde je vyžadováno rychlé zpracování.
Modely hlubokého učení: Zahrnují konvoluční neuronové sítě (CNN) a rekurentní neuronové sítě (RNN), které dokáží zachytit složité vzorce v textových datech díky vícestupňovému zpracování. Modely hlubokého učení jsou výhodné pro rozsáhlé úlohy klasifikace textu a dosahují vysoké přesnosti v analýze sentimentu a modelování jazyka.
Rozhodovací stromy a náhodné lesy: Stromové metody, které klasifikují text učením rozhodovacích pravidel odvozených z datových znaků. Tyto modely jsou oblíbené díky své interpretovatelnosti a lze je využít například při kategorizaci zákaznické zpětné vazby či dokumentů.
Proces klasifikace textu zahrnuje několik kroků:
Sbírání a příprava dat: Textová data jsou shromážděna a předzpracována. Tento krok může zahrnovat tokenizaci, stemming a odstranění stop slov pro očištění dat. Podle Levity AI jsou textová data cenným zdrojem pro pochopení chování zákazníků a správné předzpracování je klíčové pro získání použitelných poznatků.
Extrakce příznaků: Převod textu do číselných reprezentací, které lze zpracovat algoritmy strojového učení. Mezi techniky patří:
Trénování modelu: Model strojového učení je trénován na označené datové sadě. Model se tak učí spojovat příznaky s odpovídajícími kategoriemi.
Vyhodnocení modelu: Výkon modelu je hodnocen pomocí metrik jako přesnost, preciznost, recall a F1 skóre. Často se používá křížová validace pro zajištění zobecnění na dosud neviděná data. AWS zdůrazňuje důležitost vyhodnocování výkonu klasifikace textu pro dosažení požadované přesnosti a spolehlivosti.
Predikce a nasazení: Jakmile je model ověřen, může být nasazen pro klasifikaci nových textových dat.
Klasifikace textu je široce využívána v různých oblastech:
Analýza sentimentu: Detekce vyjádřeného sentimentu v textu, často využívaná pro zákaznickou zpětnou vazbu a analýzu sociálních sítí k určení veřejného mínění. Levity AI zdůrazňuje roli klasifikace textu v sociálním naslouchání, které firmám pomáhá pochopit zákaznické pocity vyjádřené v komentářích a zpětné vazbě.
Detekce spamu: Filtrování nevyžádaných a potenciálně škodlivých e-mailů jejich klasifikací jako spam nebo legitimní poštu. Automatické filtrování a označování, například v Gmailu, je klasickým příkladem využití klasifikace textu k detekci spamu.
Kategorizace témat: Organizace obsahu do předem definovaných témat, což je užitečné pro zpravodajské články, blogy a vědecké práce. Tato aplikace zjednodušuje správu a vyhledávání obsahu a zlepšuje uživatelský zážitek.
Kategorizace zákaznických požadavků: Automatické směrování požadavků na podporu na příslušné oddělení podle obsahu. Tato automatizace zvyšuje efektivitu zpracování zákaznických dotazů a snižuje zátěž podpůrných týmů.
Detekce jazyka: Identifikace jazyka textového dokumentu pro vícejazyčné aplikace. Tato schopnost je zásadní pro globální firmy působící v různých jazycích a regionech.
S klasifikací textu je spojeno několik výzev:
Kvalita a množství dat: Výkon modelů klasifikace textu výrazně závisí na kvalitě a množství trénovacích dat. Nedostatečná nebo šumová data mohou vést ke špatnému výkonu modelu. AWS upozorňuje, že organizace musí zajistit kvalitní sběr a označování dat pro dosažení přesných výsledků klasifikace.
Výběr příznaků: Správná volba příznaků je klíčová pro přesnost modelu. Pokud je model trénován na nerelevantních příznacích, může dojít k přeučení.
Interpretovatelnost modelu: Modely hlubokého učení, ačkoliv jsou velmi výkonné, často fungují jako „černá skříňka“, což ztěžuje pochopení rozhodovacího procesu. Tato neprůhlednost může být překážkou v odvětvích, kde je interpretovatelnost zásadní.
Škálovatelnost: S růstem objemu textových dat musejí modely efektivně škálovat pro zpracování velkých datových sad. Jsou zapotřebí efektivní techniky zpracování a škálovatelná infrastruktura pro zvládnutí rostoucího datového zatížení.
Klasifikace textu je nedílnou součástí automatizace poháněné AI a chatbotů. Automatickým kategorizováním a interpretací textových vstupů mohou chatboti poskytovat relevantní odpovědi, zlepšovat zákaznické interakce a zefektivňovat firemní procesy. V AI automatizaci klasifikace textu umožňuje systémům zpracovávat a analyzovat velké objemy dat s minimálním lidským zásahem, což zvyšuje efektivitu a schopnost rozhodování.
Pokrok v NLP a hlubokém učení navíc vybavil chatboty sofistikovanými schopnostmi klasifikace textu, což jim umožňuje chápat kontext, sentiment i záměr a poskytovat tak personalizovanější a přesnější interakce s uživateli. AWS uvádí, že integrace klasifikace textu do AI aplikací může výrazně zlepšit uživatelskou zkušenost díky včasnému a relevantnímu poskytování informací.
Výzkum v oblasti klasifikace textu
Klasifikace textu je zásadním úkolem v oblasti zpracování přirozeného jazyka a zahrnuje automatické přiřazení textu předem definovaným štítkům. Níže jsou shrnuty nejnovější vědecké práce, které poskytují přehled různých metod a výzev spojených s klasifikací textu:
Model a hodnocení: Směrem ke spravedlnosti v mnohojazyčné klasifikaci textu
Autoři: Nankai Lin, Junheng He, Zhenghang Tang, Dong Zhou, Aimin Yang
Publikováno: 2023-03-28
Tato práce se zabývá problémem zaujatosti v modelech mnohojazyčné klasifikace textu. Navrhuje framework pro odstranění zaujatosti pomocí kontrastního učení, který není závislý na externích jazykových zdrojích. Framework obsahuje moduly pro mnohojazyčnou reprezentaci textu, jazykovou fúzi, odstranění zaujatosti a klasifikaci. Součástí je i nový rámec pro víceúrovňové hodnocení spravedlnosti, jehož cílem je zvýšit spravedlnost napříč různými jazyky. Tato práce je významná pro zlepšení spravedlnosti a přesnosti mnohojazyčných modelů klasifikace textu. Více zde
Klasifikace textu pomocí asociačních pravidel s hybridním konceptem Naivního Bayesu a genetického algoritmu
Autoři: S. M. Kamruzzaman, Farhana Haider, Ahmed Ryadh Hasan
Publikováno: 2010-09-25
Tento výzkum představuje inovativní přístup ke klasifikaci textu využívající asociační pravidla v kombinaci s Naivním Bayesem a genetickým algoritmem. Metoda získává příznaky z předem klasifikovaných dokumentů na základě vztahů mezi slovy, nikoliv pouze jednotlivých slov. Integrace genetických algoritmů zvyšuje konečný výkon klasifikace. Výsledky ukazují efektivitu tohoto hybridního přístupu při úspěšné klasifikaci textu. Více zde
Klasifikace textu: Pohled na metody hlubokého učení
Autor: Zhongwei Wan
Publikováno: 2023-09-24
S explozivním růstem internetových dat tato práce zdůrazňuje význam metod hlubokého učení pro klasifikaci textu. Diskutuje různé techniky hlubokého učení, které zlepšují přesnost a efektivitu kategorizace složitých textů. Studie podtrhuje vyvíjející se roli hlubokého učení při zpracování velkých datových sad a dosažení přesných výsledků klasifikace. Více zde
Klasifikace textu je úkol zpracování přirozeného jazyka (NLP), při kterém jsou textovým dokumentům přiřazeny předem definované kategorie, což umožňuje automatizovanou organizaci, analýzu a interpretaci nestrukturovaných dat.
Běžné modely zahrnují Support Vector Machines (SVM), Naivní Bayes, hluboké učení jako CNN a RNN a stromové metody jako rozhodovací stromy a náhodné lesy.
Klasifikace textu se široce používá v analýze sentimentu, detekci spamu, kategorizaci témat, směrování zákaznických požadavků a detekci jazyka.
Výzvy zahrnují zajištění kvality a množství dat, správný výběr příznaků, interpretovatelnost modelu a škálovatelnost při zpracování velkých objemů dat.
Klasifikace textu umožňuje AI automatizaci a chatbotům efektivně interpretovat, kategorizovat a odpovídat na uživatelské vstupy, což zlepšuje zákaznické interakce a firemní procesy.
Začněte budovat chytré chatboty a AI nástroje, které využívají automatizovanou klasifikaci textu ke zvýšení efektivity a přehledu.
Odemkněte automatizované kategorizování textu ve vašich workflowech pomocí komponenty Klasifikace textu pro FlowHunt. Snadno zařazujte vstupní text do uživatele...
AI klasifikátor je algoritmus strojového učení, který přiřazuje vstupním datům třídy, kategorizuje informace do předem definovaných tříd na základě naučených vz...
Automatická klasifikace automatizuje kategorizaci obsahu analýzou vlastností a přiřazováním štítků pomocí technologií jako strojové učení, NLP a sémantická anal...
