Transformátor
Transformátor je typ neuronové sítě speciálně navržený pro zpracování sekvenčních dat, jako jsou text, řeč nebo časové řady. Na rozdíl od tradičních modelů, jak...
3 min čtení
Transformer
Neural Networks
+3
Transformery jsou průlomové neuronové sítě využívající self-attention pro paralelní zpracování dat, pohánějící modely jako BERT a GPT v NLP, počítačovém vidění a dalších oblastech.
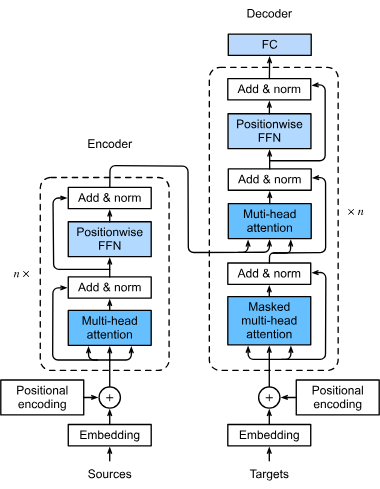
Prvním krokem ve zpracovatelském řetězci transformeru je převod slov nebo tokenů ve vstupní sekvenci na číselné vektory zvané embeddingy. Tyto embeddingy zachycují sémantiku a jsou klíčové pro to, aby model porozuměl vztahům mezi tokeny. Tato transformace je nezbytná, aby model dokázal textová data zpracovat matematicky.
Transformery samy o sobě nezpracovávají data sekvenčně; proto se používá pozicové kódování, které vnáší informaci o pozici každého tokenu v sekvenci. To je zásadní pro zachování pořadí, což je důležité například při strojovém překladu, kde kontext závisí na pořadí slov.
Mechanismus multi-head attention umožňuje modelu zaměřit se současně na různé části vstupní sekvence. Výpočtem více attention skóre dokáže model zachytit různorodé vztahy a závislosti v datech, což zvyšuje jeho schopnost porozumět a generovat složité vzory.
Transformery obvykle využívají architekturu encoder-decoder:
Po attention mechanizmu prochází data skrze feedforward neuronové sítě, které aplikují nelineární transformace a umožňují modelu učit se komplexní vzory. Tyto sítě dále zpracovávají data a zpřesňují výstup generovaný modelem.
Tyto techniky stabilizují a urychlují proces učení. Normalizace vrstev zajišťuje, že výstupy zůstávají v určitém rozsahu, což usnadňuje efektivní trénování. Reziduální propojení umožňuje volný průchod gradientů a napomáhá trénování hlubokých neuronových sítí.
Transformery pracují se sekvencemi dat, což mohou být například slova ve větě nebo jiné sekvenční informace. Uplatňují self-attention, aby určily význam jednotlivých částí sekvence vůči ostatním, čímž umožňují modelu zaměřit se na klíčové prvky ovlivňující výsledek.
Při self-attention je každý token v sekvenci porovnán se všemi ostatními tokeny a vypočítají se attention skóre. Tato skóre určují význam jednotlivých tokenů ve vztahu k ostatním, což modelu umožňuje soustředit se na nejrelevantnější části sekvence. To je klíčové pro pochopení kontextu a významu v jazykových úlohách.
Jde o stavební bloky transformer modelu, skládající se z vrstev self-attention a feedforward sítí. Více těchto bloků je navrstveno za sebou, čímž vznikají hluboké modely schopné zachytit složité vzory v datech. Tento modulární návrh umožňuje škálovat transformery podle náročnosti úlohy.
Transformery jsou efektivnější než RNN a CNN díky schopnosti zpracovávat celé sekvence najednou. Tato efektivita umožňuje škálovat až na velmi rozsáhlé modely, například GPT-3 s 175 miliardami parametrů. Škálovatelnost umožňuje pracovat s velkým množstvím dat.
Tradiční modely mají potíže s dlouhými závislostmi kvůli sekvenčnímu zpracování. Transformery tuto bariéru překonávají díky self-attention, která umí vzít v úvahu všechny části sekvence současně. Proto jsou mimořádně účinné při úlohách vyžadujících pochopení kontextu v dlouhém textu.
Ačkoli byly transformery původně vyvinuty pro NLP, byly adaptovány i do dalších oblastí, včetně počítačového vidění, skládání proteinů či predikce časových řad. Tato všestrannost dokládá širokou využitelnost transformerů napříč různými obory.
Transformery zásadně zlepšily výkon NLP úloh, jako je překlad, sumarizace nebo analýza sentimentu. Modely jako BERT a GPT využívají architekturu transformerů k porozumění a generování textu, čímž nastavily nové standardy v oblasti NLP.
Ve strojovém překladu excelují transformery tím, že chápou kontext slov v rámci věty, což vede k přesnějším překladům než dřívější metody. Díky zpracování celých vět najednou jsou překlady soudržnější a kontextově správnější.
Transformery lze využít k modelování sekvencí aminokyselin v proteinech a tím předpovídat jejich strukturu, což je zásadní například pro vývoj léků nebo poznání biologických procesů. Toto využití podtrhuje potenciál transformerů ve vědeckém výzkumu.
Adaptací architektury transformeru lze předpovídat budoucí hodnoty v časových řadách, například poptávku po elektřině, na základě analýzy předchozích sekvencí. To otevírá nové možnosti využití transformerů ve financích či řízení zdrojů.
Modely BERT jsou navrženy tak, aby chápaly kontext slova nahlížením na jeho okolní slova, a jsou tak velmi efektivní pro úlohy vyžadující porozumění vztahům ve větě. Tento obousměrný přístup umožňuje BERT lépe zachytit kontext než jednosměrné modely.
Modely GPT jsou autoregresivní, generují text predikováním dalšího slova na základě předchozích slov v sekvenci. Široce se využívají například pro doplňování textu nebo generování dialogů a jsou schopné vytvářet text podobný lidskému projevu.
Transformery byly původně vyvinuty pro NLP, ale byly adaptovány i pro úlohy počítačového vidění. Vision transformery zpracovávají obrazová data jako sekvence, což umožňuje aplikovat transformer techniky na vizuální vstupy. Tato adaptace vedla k pokroku v rozpoznávání a zpracování obrazů.
Trénování velkých transformer modelů vyžaduje značné výpočetní prostředky, často masivní datasety a výkonný hardware (např. GPU). To představuje překážku z hlediska nákladů a dostupnosti pro řadu organizací.
S rostoucím rozšířením transformerů nabývají na důležitosti témata jako zkreslení v modelech AI a etické využití AI-generovaného obsahu. Výzkumníci pracují na metodách, jak tyto otázky zmírnit a zajistit odpovědný rozvoj AI, což podtrhuje potřebu etických rámců ve výzkumu AI.
Všestrannost transformerů otevírá nové oblasti výzkumu a uplatnění – od vylepšování AI chatbotů až po zlepšování analýz dat ve zdravotnictví a finančnictví. Budoucnost transformerů přináší slibné možnosti inovací napříč různými odvětvími.
Závěrem lze říci, že transformery představují zásadní posun v technologiích AI, nabízejí bezkonkurenční možnosti při zpracování sekvenčních dat. Jejich inovativní architektura a efektivita nastavily nový standard v oboru a posunuly AI aplikace na novou úroveň. Ať už jde o porozumění jazyku, vědecký výzkum nebo zpracování vizuálních dat, transformery stále posouvají hranice možného v oblasti umělé inteligence.
Transformery zásadně změnily oblast umělé inteligence, zejména v oblasti zpracování přirozeného jazyka a porozumění. Studie “AI Thinking: A framework for rethinking artificial intelligence in practice” od Denise Newman-Griffise (vydáno 2024) zkoumá nový koncepční rámec zvaný AI Thinking. Tento rámec modeluje klíčová rozhodnutí a úvahy při využívání AI napříč obory a řeší kompetence v motivaci využití AI, formování AI metod a zasazování AI do sociotechnických kontextů. Jeho cílem je překlenout rozdíly mezi akademickými disciplínami a utvářet budoucnost AI v praxi. Číst více.
Dalším významným příspěvkem je “Artificial intelligence and the transformation of higher education institutions” od Evangelose Katsamakase a kol. (vydáno 2024), který využívá přístup komplexních systémů k mapování zpětnovazebních mechanismů AI transformace na vysokých školách. Studie analyzuje síly pohánějící AI transformaci a její vliv na vytváření hodnoty a zdůrazňuje nutnost, aby se vysoké školy přizpůsobily rozvoji AI technologií při současném udržení akademické integrity a řízení změn v zaměstnanosti. Číst více.
V oblasti vývoje softwaru se studie “Can Artificial Intelligence Transform DevOps?” od Mamdouha Aleneziho a kolegů (vydáno 2022) zabývá propojením AI a DevOps. Studie zdůrazňuje, jak může AI zefektivnit DevOps procesy a přinést efektivnější softwarovou dodávku. Upozorňuje na praktické dopady pro vývojáře i firmy, kteří mohou využít AI k proměně DevOps praxe. Číst více
Transformery jsou architektura neuronových sítí představená v roce 2017, která využívá mechanismus self-attention k paralelnímu zpracování sekvenčních dat. Zásadně ovlivnily oblast umělé inteligence, zejména v přirozeném jazyce a počítačovém vidění.
Na rozdíl od RNN a CNN zpracovávají transformery všechny prvky sekvence najednou pomocí self-attention, což umožňuje větší efektivitu, škálovatelnost a schopnost zachytit dlouhodobé závislosti.
Transformery jsou široce využívány v úlohách NLP, jako je překlad, sumarizace nebo analýza sentimentu, stejně jako v počítačovém vidění, predikci struktury proteinů a predikci časových řad.
Mezi významné modely transformerů patří BERT (Bidirectional Encoder Representations from Transformers), GPT (Generative Pre-trained Transformers) a Vision Transformers pro zpracování obrazových dat.
Transformery vyžadují značné výpočetní zdroje pro trénink i nasazení. Přinášejí také etické otázky, například potenciální zkreslení AI modelů a odpovědné používání generativního AI obsahu.
Chytré chatboty a AI nástroje na jednom místě. Propojte intuitivní bloky a proměňte své nápady v automatizované toky.
Transformátor je typ neuronové sítě speciálně navržený pro zpracování sekvenčních dat, jako jsou text, řeč nebo časové řady. Na rozdíl od tradičních modelů, jak...
Generativní předtrénovaný transformátor (GPT) je AI model, který využívá techniky hlubokého učení k produkci textu, jenž velmi věrně napodobuje lidské psaní. Je...
Deep Belief Network (DBN) je sofistikovaný generativní model využívající hluboké architektury a Restricted Boltzmann Machines (RBM) k učení hierarchických repre...