Dokumenty
Váš chatbot může okamžitě přistupovat k dokumentům, HTML stránkám i YouTube videím a používat je pro přizpůsobení vašemu unikátnímu kontextu. Ideální pro přidán...
2 min čtení
AI Chatbot
Knowledge Management
+3
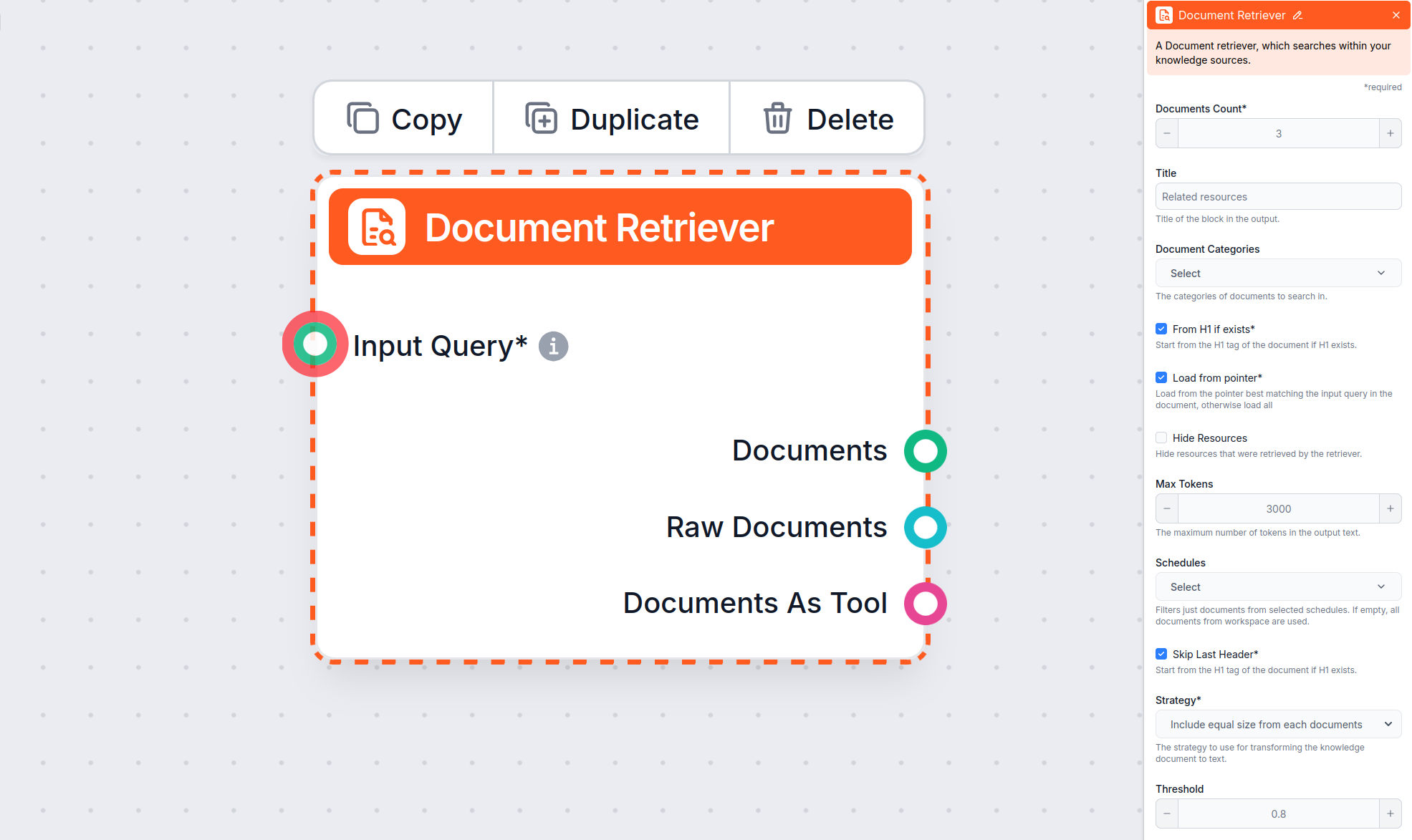
Naučte se nastavit parametry ‘Od H1 pokud existuje’, ‘Načíst z ukazatele’ a ‘Přeskočit poslední nadpis’.
Komponent Document Retriever umožňuje chatbotovi získávat znalosti ze zdrojů, které určíte v sekci Dokumenty a Plány. Úkolem této komponenty je řídit načítání informací a různé parametry ovlivňují, jakým způsobem jsou informace z těchto dokumentů získávány.
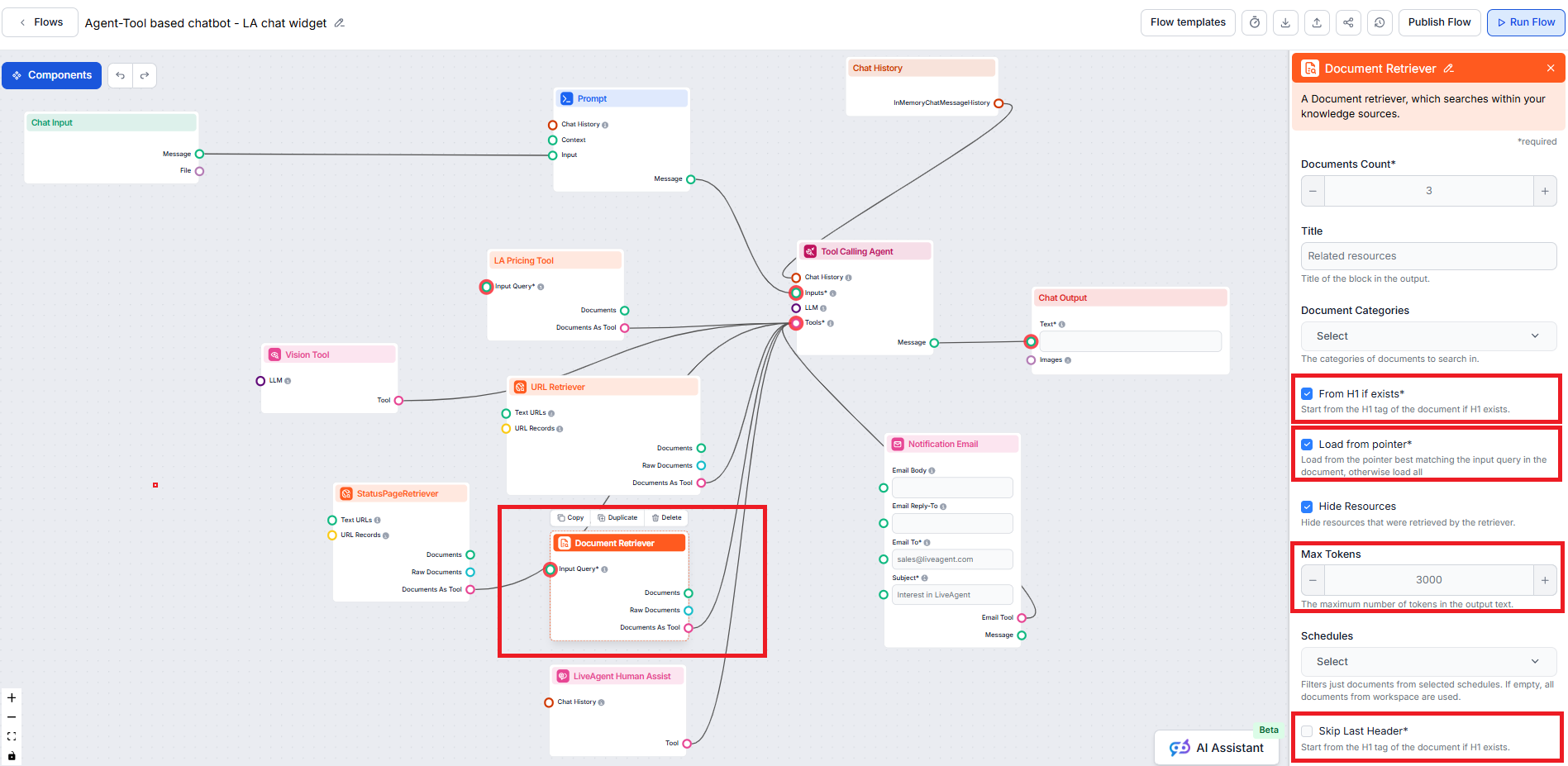
Možnost Od H1 pokud existuje říká retrieveru, aby začal extrahovat obsah od H1 nadpisu, který najde (obvykle hlavního titulku článku).
Co se stane?
Příklad využití:
Chcete získat pouze vlastní návod, bez jakýchkoliv navigačních prvků nebo záhlaví stránky, které se nacházejí na vašem webu.
Poznámka:
Od H1 pokud existuje je v komponentě Document Retriever povoleno ve výchozím nastavení.
Možnost Načíst z ukazatele vám poskytuje větší přesnost tím, že umožňuje Document Retrieveru načíst pouze data od určitého ukazatele v případně delším článku.
Co se stane?
Co je to “ukazatel”?
Ukazatel je obvykle unikátní řetězec nebo nadpis v dokumentu (například H2, specifická fráze nebo název sekce).
Příklad využití:
Chcete přeskočit úvodní části a získat informace pro konkrétní relevantní sekci v případně dlouhém článku nebo dokumentu (například od “Krok 4: Přidejte tlačítko živého chatu” v instalačním návodu).
Možnost Přeskočit poslední nadpis je užitečná pro ignorování posledního nadpisu v dokumentu, který bývá často opakován nebo slouží k navigaci či patičce.
Co se stane?
Příklad využití:
Chcete zabránit tomu, aby Document Retriever načetl navigační patičkový nadpis (například “Další články” na konci nápovědy), a zajistit tak, aby byl zpracován pouze hlavní obsah.
Poznámka:
Přeskočit poslední nadpis pomáhá u dokumentů, které automaticky generují patičky nebo opakující se navigační prvky. Pokud však takové sekce nemáte, může použití tohoto parametru způsobit, že část článku s platnými informacemi nebude načtena. Proto doporučujeme tuto možnost nechávat neoznačenou, dokud k jejímu zapnutí nebude dobrý důvod.
Parametr Max tokens vám umožňuje nastavit maximální počet tokenů (slov a interpunkčních znaků, jak je počítá model AI), které Document Retriever z extrahovaného textu vrátí.
Co se stane?
Výchozí hodnota:
Výchozí hodnota je obvykle 3000 tokenů, ale můžete ji podle potřeby upravit.
Příklad využití:
Pokud zpracováváte rozsáhlé dokumenty, nastavení nižší hodnoty Max tokens pomůže udržet odpovědi stručné. Pro nejlepší výsledky však zvažte povolení parametru “Načíst z ukazatele”. Tím zajistíte, že extrahovaný text začne v nejrelevantnější části dokumentu, nikoli od začátku, a získáte tak soustředěný a zvládnutelný úsek informací v rámci stanoveného limitu tokenů. Tato kombinace je zvlášť užitečná, když potřebujete stručné, kontextově relevantní výstupy z rozsáhlých zdrojů.
Poznámka:
Pokud zjistíte, že se informace ztrácejí kvůli limitu, zkuste hodnotu Max tokens zvýšit. Naopak, pokud chcete kratší a zaměřenější výstupy, hodnotu Max tokens snižte.
Když Document Retriever najde několik relevantních dokumentů, parametr Strategie určuje, jak budou sloučeny do jednoho textového výstupu pro váš chatbot s ohledem na limit “Max tokens”.
Dvě možnosti strategie:
Zahrnout stejný rozsah z každého dokumentu:
Limit tokenů se rozdělí rovnoměrně. Například u tří dokumentů a limitu 3 000 tokenů má každý maximálně 1 000 tokenů. To zajistí, že všechny zdroje přispějí stejnou měrou, což je užitečné, pokud chcete vyváženou odpověď čerpající z více dokumentů.
Spojit dokumenty, naplnit od prvního až do limitu tokenů:
Dokumenty jsou přidávány podle relevance, dokud není vyčerpán limit tokenů. Nejrelevantnější dokument zaplní prostor jako první; pokud zbývá místo, přidají se méně relevantní dokumenty. Pokud je první dokument dlouhý, může využít celý limit sám.
Jak vybrat?
Poznámka:
Tyto strategie ovlivňují pouze způsob sestavení textu z načtených dokumentů před předáním do dalšího kroku (například AI generace). Nemění, které dokumenty jsou načteny – pouze to, jak je jejich obsah sloučen a zkrácen, aby se vešel do limitu Max tokens.
Tento článek se zaměřuje na nastavení parametrů ‘Od H1 pokud existuje’, ‘Načíst z ukazatele’, ‘Přeskočit poslední nadpis’ a ‘Max tokens’, ale Document Retriever nabízí i další parametry, které pomáhají kontrolovat způsob výběru a načítání dokumentů:
Toto nastavení omezuje počet dokumentů, které má tok načíst, aby byly výsledky relevantní a odpovědi se generovaly rychle.
Toto volitelné nastavení umožňuje omezit načítání na jednu nebo více kategorií, které jste vytvořili v sekci Dokumenty ve Zdroji znalostí.
To vám umožní zahrnout nebo skrýt samostatnou sekci před samotnou odpovědí chatbota, kde je seznam zdrojů načtených retrieverem. Pro integraci s LiveAgent musí být tato možnost zaškrtnutá, protože tuto sekci widget LiveAgent chatbota nepodporuje a nezobrazí ji správně.
Umožňuje omezit načítání na jeden nebo více Plánů, které jste nastavili pro procházení nebo aktualizaci obsahu ve Zdroji znalostí.
Ovládá, jak přesně se musí načtené dokumenty shodovat se vstupním dotazem, pomocí skóre relevance (od 0 do 1). Například práh 0,7–0,8 je doporučen pro vysoce relevantní odpovědi. Vyšší prahy dávají přesnější shody, zatímco nižší mohou zahrnovat méně relevantní dokumenty.
Příklad:
Pokud nastavíte práh na 0,6 a máte čtyři články se skóre relevance 0,8, 0,65, 0,5 a 0,9, pro extrakci budou použity pouze ty nad 0,6 (tedy 0,8, 0,65 a 0,9).
Pokud odpověď chatbota neobsahuje informace, o kterých víte, že je chatbot má k dispozici ve vašich dokumentech nebo plánech, zkuste zkontrolovat historii konverzace s volbou “Verbose” a zjistit podrobné záznamy o tom, zda byl použit Document Retriever a jaké dokumenty byly načteny. V případě potřeby podle těchto záznamů upravte svá nastavení a prompt.
Váš chatbot může okamžitě přistupovat k dokumentům, HTML stránkám i YouTube videím a používat je pro přizpůsobení vašemu unikátnímu kontextu. Ideální pro přidán...

Podrobný návod, jak importovat pouze konkrétní sekce z docs.cpanel.net do vašeho FlowHunt chatbota, aby se stal expertem na cílená témata cPanelu bez nutnosti v...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.