Odpovídání na otázky s Retrieval-Augmented Generation (RAG) kombinuje vyhledávání informací a generování přirozeného jazyka za účelem vylepšení velkých jazykových modelů (LLM) doplňováním odpovědí o relevantní, aktuální data z externích zdrojů. Tento hybridní přístup zvyšuje přesnost, relevanci a přizpůsobivost v dynamických oblastech.
Odpovídání na otázky
Odpovídání na otázky s Retrieval-Augmented Generation (RAG) vylepšuje jazykové modely integrací externích dat v reálném čase pro přesné a relevantní odpovědi. Optimalizuje výkon v dynamických oblastech a přináší vyšší přesnost, dynamický obsah a zvýšenou relevanci.
Odpovídání na otázky s Retrieval-Augmented Generation (RAG) je inovativní metoda, která spojuje silné stránky vyhledávání informací a generování přirozeného jazyka – vytváří lidsky znějící text z dat, čímž vylepšuje AI, chatboty, reporty i personalizaci zážitků. Tento hybridní přístup rozšiřuje možnosti velkých jazykových modelů (LLM) tím, že jejich odpovědi doplňuje o relevantní a aktuální informace získané z externích datových zdrojů. Na rozdíl od tradičních metod, které spoléhají pouze na předtrénované modely, RAG dynamicky integruje externí data, což umožňuje poskytovat přesnější a kontextově vhodnější odpovědi – obzvlášť v oblastech, kde jsou potřeba nejnovější informace nebo specializované znalosti.
RAG optimalizuje výkon LLM tím, že odpovědi nejsou generovány jen z interní databáze, ale jsou podloženy i aktuálními a autoritativními zdroji. Tento přístup je zásadní pro úkoly odpovídání na otázky v dynamických oborech, kde se informace neustále vyvíjejí.
Hlavní komponenty RAG
1. Vyhledávací komponenta
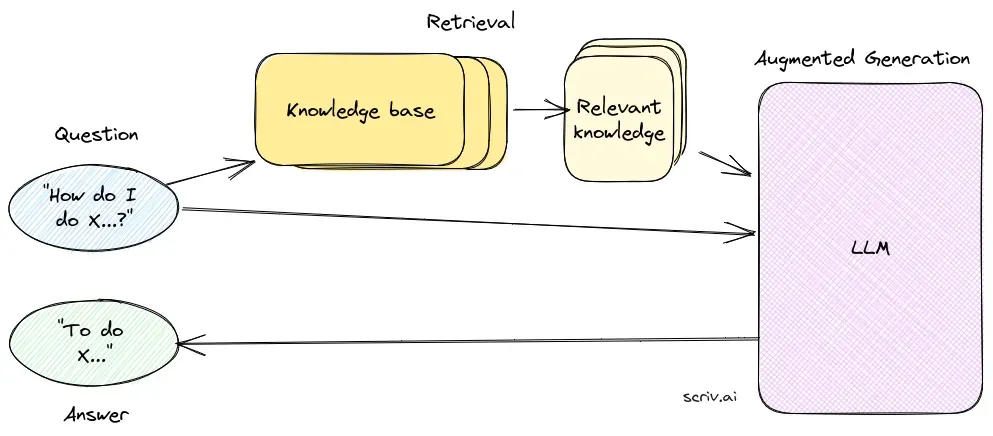
Vyhledávací komponenta zajišťuje získávání relevantních informací z rozsáhlých datových sad, obvykle uložených ve vektorové databázi. Využívá sémantické vyhledávání k identifikaci a extrakci textových úryvků nebo dokumentů, které jsou vysoce relevantní k dotazu uživatele.
Vektorová databáze: Specializovaná databáze ukládající vektorové reprezentace dokumentů. Tyto embeddingy umožňují efektivní vyhledávání a získávání informací na základě shody sémantického významu dotazu uživatele s relevantními textovými úryvky.
Sémantické vyhledávání: Využívá vektorové embeddingy pro nalezení dokumentů na základě sémantické podobnosti místo prostého shody klíčových slov, což zvyšuje relevanci a přesnost získaných informací.
2. Generační komponenta
Generační komponenta, obvykle LLM jako GPT-3 či BERT, syntetizuje odpověď kombinací původního dotazu uživatele se získaným kontextem. Je klíčová pro generování koherentních a kontextově vhodných odpovědí.
Jazykové modely (LLMs): Trénované na generování textu na základě vstupních promptů, LLM v systémech RAG využívají získané dokumenty jako kontext ke zvýšení kvality a relevance generovaných odpovědí.
Pracovní postup systému RAG
Příprava dokumentů: Systém začíná načtením rozsáhlého korpusu dokumentů a jejich převedením do formátu vhodného pro analýzu, často rozdělením na menší, lépe zvládnutelné části.
Vektorové embeddingy: Každý úryvek dokumentu je převeden do vektorové reprezentace pomocí embeddingů generovaných jazykovými modely. Tyto vektory jsou uloženy ve vektorové databázi pro efektivní vyhledávání.
Zpracování dotazu: Po obdržení dotazu uživatele systém převede dotaz na vektor a provede srovnání s vektorovou databází za účelem nalezení relevantních úryvků dokumentů.
Generování odpovědi s kontextem: Získané úryvky dokumentů jsou zkombinovány s uživatelským dotazem a předány do LLM, který vygeneruje finální, kontextově obohacenou odpověď.
Výstup: Systém poskytne odpověď, která je přesná a relevantní ke zadanému dotazu a obsahuje vhodný kontext.
Připraveni rozšířit své podnikání?
Začněte svou bezplatnou zkušební verzi ještě dnes a viďte výsledky během několika dní.
Vyšší přesnost: Díky získávání relevantního kontextu RAG minimalizuje riziko generování nesprávných nebo zastaralých odpovědí, což je běžný problém u samostatných LLM.
Dynamický obsah: Systémy RAG mohou integrovat nejnovější informace z aktualizovaných znalostních bází, což je činí ideálními pro oblasti vyžadující aktuální data.
Zvýšená relevance: Vyhledávací proces zajišťuje, že generované odpovědi jsou přizpůsobeny konkrétnímu kontextu dotazu, čímž se zvyšuje jejich kvalita a relevance.
Příklady použití
Chatboti a virtuální asistenti: Systémy využívající RAG vylepšují chatboty a asistenty o přesné a kontextově závislé odpovědi, což zvyšuje uživatelský komfort a spokojenost.
Zákaznická podpora: V oblasti podpory zákazníků dokáže RAG vyhledat relevantní podkladové dokumenty nebo informace o produktech a poskytovat tak přesné odpovědi na dotazy uživatelů.
Tvorba obsahu: Modely RAG mohou generovat dokumenty a reporty integrací získaných informací, což je užitečné pro automatizované úkoly tvorby obsahu.
Vzdělávací nástroje: Ve vzdělávání mohou systémy RAG pohánět výukové asistenty, kteří poskytují vysvětlení a shrnutí na základě nejnovějších vzdělávacích materiálů.
Přihlaste se k odběru newsletteru
Získejte nejnovější tipy, trendy a nabídky zdarma.
Technická implementace
Implementace systému RAG zahrnuje několik technických kroků:
Ukládání a vyhledávání vektorů: Použijte vektorové databáze jako Pinecone nebo FAISS pro efektivní ukládání a vyhledávání embeddingů dokumentů.
Integrace jazykových modelů: Zapojte LLM jako GPT-3 nebo vlastní modely prostřednictvím frameworků jako HuggingFace Transformers pro správu generování odpovědí.
Konfigurace pipeline: Nastavte pipeline, která řídí tok od vyhledání dokumentu po generování odpovědi a zajišťuje plynulou integraci všech komponent.
Výzvy a úskalí
Náklady a správa zdrojů: Systémy RAG mohou být náročné na výpočetní zdroje, a proto vyžadují optimalizaci pro efektivní správu nákladů.
Faktická přesnost: Je nezbytné zajistit, aby získané informace byly přesné a aktuální, aby nedocházelo ke generování zavádějících odpovědí.
Složitost implementace: Počáteční nastavení systému RAG může být složité, protože je potřeba integrovat a optimalizovat více komponent.
Výzkum v oblasti odpovídání na otázky s Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) je metoda, která vylepšuje systémy odpovídání na otázky kombinací vyhledávacích mechanismů s generativními modely. Nedávný výzkum zkoumá účinnost a optimalizaci RAG v různých kontextech.
In Defense of RAG in the Era of Long-Context Language Models: Tento článek obhajuje pokračující význam RAG i přes nástup jazykových modelů s dlouhým kontextem, které zpracovávají delší textové sekvence. Autoři navrhují mechanismus Order-Preserve Retrieval-Augmented Generation (OP-RAG), který optimalizuje výkon RAG při zpracování dotazů na dlouhé kontexty. Experimenty ukazují, že OP-RAG dosahuje vysoké kvality odpovědí s menším počtem tokenů oproti modelům s dlouhým kontextem. Čtěte více.
CLAPNQ: Cohesive Long-form Answers from Passages in Natural Questions for RAG systems: Tato studie představuje benchmarkovou datovou sadu ClapNQ pro hodnocení systémů RAG při generování koherentních dlouhých odpovědí. Datová sada se zaměřuje na odpovědi založené na konkrétních pasážích bez halucinací a motivuje RAG modely k adaptaci na stručné a soudržné odpovědi. Autoři poskytují základní experimenty, které odhalují potenciální možnosti zlepšení RAG systémů. Čtěte více
.
Optimizing Retrieval-Augmented Generation with Elasticsearch for Enhanced Question-Answering Systems: Výzkum integruje Elasticsearch do frameworku RAG za účelem zvýšení efektivity a přesnosti odpovídání na otázky. Pomocí Stanford Question Answering Dataset (SQuAD) verze 2.0 studie porovnává různé metody vyhledávání a vyzdvihuje výhody schématu ES-RAG z hlediska efektivity a přesnosti, přičemž překonává jiné metody o 0,51 procentního bodu. Článek doporučuje další zkoumání interakce mezi Elasticsearch a jazykovými modely pro zlepšení odpovědí systému. Čtěte více.
Často kladené otázky
RAG je metoda, která kombinuje vyhledávání informací a generování přirozeného jazyka, aby poskytovala přesné a aktuální odpovědi integrací externích datových zdrojů do velkých jazykových modelů.
Systém RAG se skládá z vyhledávací komponenty, která získává relevantní informace z vektorových databází pomocí sémantického vyhledávání, a generovací komponenty, obvykle LLM, která syntetizuje odpovědi na základě dotazu uživatele i získaného kontextu.
RAG zvyšuje přesnost vyhledáváním kontextově relevantních informací, podporuje dynamickou aktualizaci obsahu z externích znalostních bází a zlepšuje relevanci a kvalitu generovaných odpovědí.
Běžné využití zahrnuje AI chatboty, zákaznickou podporu, automatizovanou tvorbu obsahu a vzdělávací nástroje, které vyžadují přesné, kontextově závislé a aktuální odpovědi.
Systémy RAG mohou být náročné na zdroje, vyžadují pečlivou integraci pro optimální výkon a je nutné zajistit faktickou přesnost získaných informací, aby se předešlo zavádějícím nebo zastaralým odpovědím.
Začněte budovat AI odpovídání na otázky
Zjistěte, jak může Retrieval-Augmented Generation posílit vaše chatboty a podporu díky přesným odpovědím v reálném čase.
Retrieval Augmented Generation (RAG) je pokročilý AI framework, který kombinuje tradiční systémy pro vyhledávání informací s generativními velkými jazykovými mo...
Retrieval vs Cache Augmented Generation (CAG vs. RAG)
Objevte klíčové rozdíly mezi Retrieval-Augmented Generation (RAG) a Cache-Augmented Generation (CAG) v AI. Zjistěte, jak RAG dynamicky vyhledává aktuální inform...
RAG AI: Definitivní průvodce Retrieval-Augmented Generation a agentickými workflow
Objevte, jak Retrieval-Augmented Generation (RAG) mění podnikové AI – od základních principů po pokročilé agentické architektury, jako je FlowHunt. Zjistěte, ja...
6 min čtení
RAG
Agentic RAG
+2
Souhlas s cookies Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.