Integrace Neo4j MCP Serveru
Neo4j MCP Server propojuje AI asistenty s grafovou databází Neo4j, což umožňuje bezpečné operace s grafy pomocí přirozeného jazyka, Cypher dotazy a automatizova...
4 min čtení
AI
Graph Database
+5
Neo4j MCP Server propojuje AI asistenty s grafovou databází Neo4j, což umožňuje bezpečné operace s grafy pomocí přirozeného jazyka, Cypher dotazy a automatizova...
NASA MCP Server poskytuje jednotné rozhraní pro AI modely a vývojáře k přístupu k více než 20 NASA datovým zdrojům. Standardizuje načítání, zpracování a správu ...
MCP Code Executor MCP Server umožňuje FlowHunt a dalším nástrojům poháněným LLM bezpečně spouštět Python kód v izolovaných prostředích, spravovat závislosti a d...
MCP server pro průzkum dat propojuje AI asistenty s externími datovými sadami pro interaktivní analýzu. Uživatelům umožňuje prozkoumávat CSV i Kaggle datasety, ...
Reexpress MCP Server přináší statistické ověřování do pracovních postupů s LLM. Pomocí odhadovače Similarity-Distance-Magnitude (SDM) poskytuje robustní odhady ...
Databricks Genie MCP Server umožňuje velkým jazykovým modelům interagovat s prostředím Databricks prostřednictvím Genie API a podporuje konverzační průzkum dat,...
JupyterMCP umožňuje bezproblémovou integraci Jupyter Notebooku (6.x) s AI asistenty prostřednictvím Model Context Protocolu. Automatizujte spouštění kódu, sprav...
AI datový analytik spojuje tradiční dovednosti v oblasti analýzy dat s umělou inteligencí (AI) a strojovým učením (ML) za účelem získávání poznatků, predikce tr...
BigML je platforma strojového učení navržená tak, aby zjednodušila tvorbu a nasazení prediktivních modelů. Byla založena v roce 2011 a jejím posláním je zpřístu...
Čištění dat je zásadní proces detekce a opravy chyb nebo nesrovnalostí v datech za účelem zvýšení jejich kvality, což zajišťuje přesnost, konzistenci a spolehli...
Dolování dat je sofistikovaný proces analýzy rozsáhlých souborů surových dat s cílem odhalit vzorce, vztahy a poznatky, které mohou informovat obchodní strategi...
Google Colaboratory (Google Colab) je cloudová platforma Jupyter notebooků od Googlu, která uživatelům umožňuje psát a spouštět Python kód v prohlížeči s bezpla...
Gradient Boosting je výkonná ensemble metoda strojového učení pro regresi i klasifikaci. Modely buduje sekvenčně, obvykle s použitím rozhodovacích stromů, za úč...
Prozkoumejte, jak inženýrství a extrakce příznaků zvyšují výkon AI modelů transformací surových dat na hodnotné poznatky. Objevte klíčové techniky jako tvorbu p...
Jupyter Notebook je open-source webová aplikace, která uživatelům umožňuje vytvářet a sdílet dokumenty s živým kódem, rovnicemi, vizualizacemi a narativním text...
K-Means shlukování je oblíbený algoritmus neřízeného strojového učení pro rozdělení datových sad do předem definovaného počtu odlišných, nepřekrývajících se shl...
Algoritmus k-nejbližších sousedů (KNN) je neparametrický, řízený algoritmus strojového učení používaný pro klasifikaci a regresi. Předpovídá výsledky hledáním '...
Kaggle je online komunita a platforma pro datové vědce a strojové inženýry, kteří zde mohou spolupracovat, učit se, soutěžit a sdílet poznatky. Kaggle, které by...
Kauzální inference je metodologický přístup používaný k určování příčinných vztahů mezi proměnnými, který je klíčový ve vědách pro pochopení kauzálních mechanis...
AI klasifikátor je algoritmus strojového učení, který přiřazuje vstupním datům třídy, kategorizuje informace do předem definovaných tříd na základě naučených vz...
Anaconda je komplexní open-source distribuce Pythonu a R, navržená pro zjednodušení správy balíčků a nasazení pro vědecké výpočty, datovou vědu a strojové učení...
Lineární regrese je základní analytická technika ve statistice a strojovém učení, která modeluje vztah mezi závislými a nezávislými proměnnými. Díky své jednodu...
NumPy je open-source Python knihovna klíčová pro numerické výpočty, která poskytuje efektivní operace s poli a matematické funkce. Je základem vědeckých výpočtů...
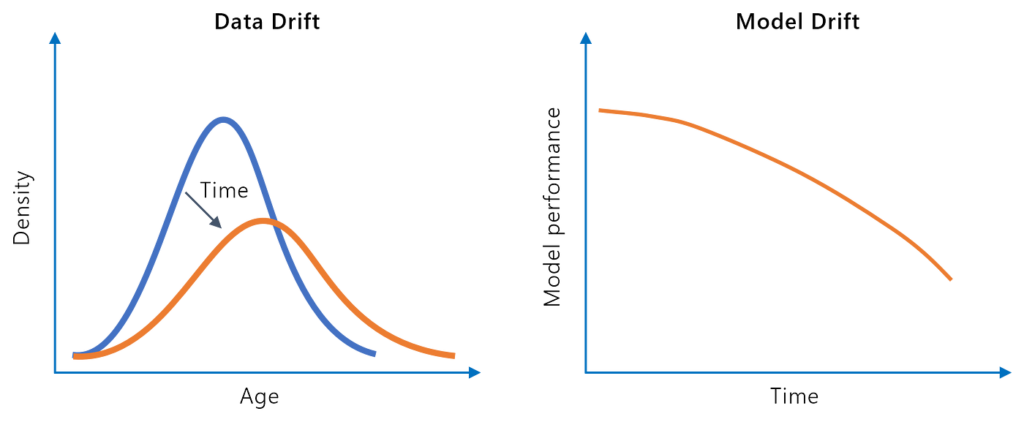
Odklon modelu, nebo také degradace modelu, označuje pokles prediktivní výkonnosti modelu strojového učení v čase v důsledku změn v reálném světě. Zjistěte, jaké...
Pandas je open-source knihovna pro manipulaci a analýzu dat v Pythonu, proslulá svou univerzálností, robustními datovými strukturami a snadným použitím při prác...
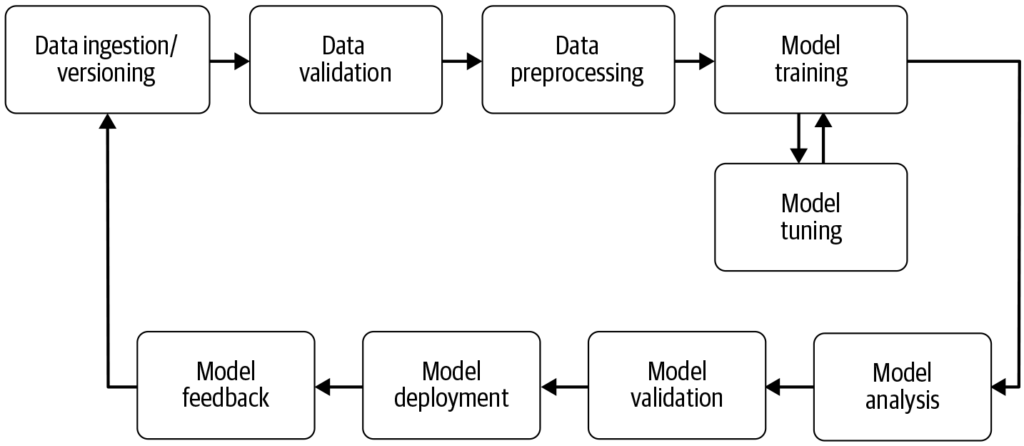
Pipeline strojového učení je automatizovaný pracovní postup, který zefektivňuje a standardizuje vývoj, trénování, vyhodnocování a nasazení modelů strojového uče...
Plocha pod křivkou (AUC) je základní metrika ve strojovém učení používaná k hodnocení výkonnosti binárních klasifikačních modelů. Kvantifikuje celkovou schopnos...
Polouzívané učení (SSL) je technika strojového učení, která využívá jak označená, tak neoznačená data k trénování modelů, což je ideální v případech, kdy je ozn...
Prediktivní modelování je sofistikovaný proces v datové vědě a statistice, který předpovídá budoucí výsledky analýzou historických datových vzorců. Využívá stat...
Redukce dimenzionality je klíčová technika při zpracování dat a strojovém učení, která snižuje počet vstupních proměnných v datové sadě a zároveň zachovává pods...
Rozhodovací strom je výkonný a intuitivní nástroj pro rozhodování a prediktivní analýzu, používaný jak pro klasifikační, tak regresní úlohy. Jeho stromová struk...
Řetězení modelů je technika strojového učení, při které jsou více modely propojeny sekvenčně, přičemž výstup každého modelu slouží jako vstup pro model následuj...
Scikit-learn je výkonná open-source knihovna strojového učení pro Python, která poskytuje jednoduché a efektivní nástroje pro prediktivní analýzu dat. Je široce...
Upravené R-kvadrát je statistická míra používaná k hodnocení kvality přizpůsobení regresního modelu, která zohledňuje počet prediktorů, aby se zabránilo přeplně...
Prozkoumejte zkreslení v AI: pochopte jeho zdroje, dopad na strojové učení, příklady z praxe a strategie pro jeho zmírnění, abyste vytvořili spravedlivé a spole...