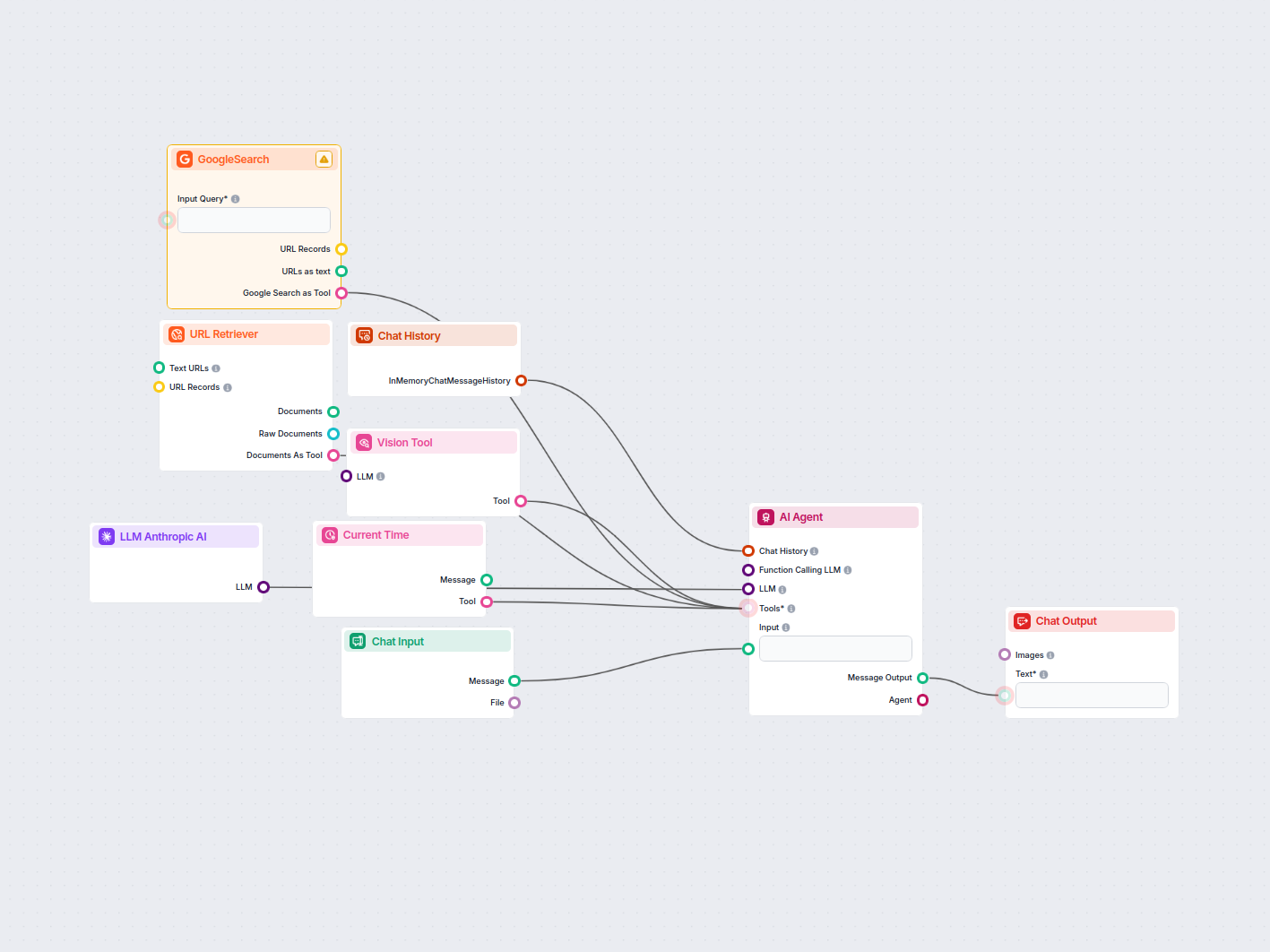
LinkedIn Annonce Konkurrentanalysator
Dette workflow automatiserer LinkedIn annoncer markedsundersøgelser ved at identificere de førende konkurrenter for et nøgleord, analysere deres annoncematerial...
4 min læsning
Visionværktøjet lader AI analysere billeder, udtrække værdifulde indsigter og besvare spørgsmål baseret på visuelt indhold i dine arbejdsgange.
Komponentbeskrivelse
Visionværktøjet er en komponent designet til at gøre det muligt for AI-arbejdsgange at behandle og analysere billeder, der leveres som vedhæftede filer. Det gør AI-agenter i stand til at “se” billeder, udtrække meningsfuld information og besvare spørgsmål om det visuelle indhold. Dette gør det særligt værdifuldt i scenarier, hvor forståelse eller fortolkning af billeder er afgørende, såsom dokumentbehandling, visuel QA, indholdsmoderering eller multimedieanalyse.
| Inputnavn | Type | Beskrivelse | Påkrævet | Avanceret |
|---|---|---|---|---|
| LLM (model) | BaseChatModel | Sprogsmodellen, der bruges til at generere tekstsvar baseret på billedanalyse. | Nej | Nej |
| Værktøjsbeskrivelse | String (multi) | Beskrivelse, der hjælper agenten med at forstå, hvordan dette værktøj skal bruges. | Nej | Ja |
| Værktøjsnavn | String | Referencenavn for dette værktøj i agentarbejdsgange. | Nej | Ja |
| Uddybende | Boolean | Mulighed for at aktivere detaljeret (uddybende) output til fejlfinding eller gennemsigtighed. | Nej | Ja |
| Outputnavn | Type | Beskrivelse |
|---|---|---|
| Værktøj | Tool | Den konfigurerede Visionværktøjs-instans klar til integration |
Visionværktøjet returnerer en værktøjsinstans, som AI-agenter kan bruge til at behandle billeder og levere relevante svar.
Ved at integrere Visionværktøjet i dine AI-processer åbnes muligheden for at arbejde med visuelle data, ikke kun tekst. Det bygger bro mellem sprog- og billedforståelse og skaber muligheder for mere dynamiske, interaktive og intelligente applikationer.
Sammenfatning af fordele:
Ved at bruge Visionværktøjet kan dine AI-arbejdsgange blive mere kapable og alsidige, hvilket baner vejen for næste generations applikationer, der udnytter både tekst- og billedintelligens.
For at hjælpe dig med at komme hurtigt i gang, har vi forberedt flere eksempel-flow-skabeloner, der demonstrerer, hvordan du bruger Visionværktøj-komponenten effektivt. Disse skabeloner viser forskellige brugssituationer og bedste praksis, hvilket gør det lettere for dig at forstå og implementere komponenten i dine egne projekter.
Dette workflow automatiserer LinkedIn annoncer markedsundersøgelser ved at identificere de førende konkurrenter for et nøgleord, analysere deres annoncematerial...
Visionværktøjet gør det muligt for dit flow at behandle billeder, udtrække meningsfuld information og besvare spørgsmål om billedindhold ved hjælp af AI.
Ja, Visionværktøjet er designet til at fortolke billeder i konteksten af din arbejdsgang, så AI-agenter kan kombinere visuel og tekstuel information for mere intelligent automatisering.
Typiske anvendelser omfatter dokumentbehandling, automatiseret visuel inspektion, udtrækning af data fra billeder og forbedring af chatbot-samtaler med billedforståelse.
Absolut. Visionværktøjet er en plug-and-play-komponent i FlowHunt, der nemt kan forbindes til andre workflow-elementer, der kræver billedanalyse.
Du kan vælge eller konfigurere en AI-model, men FlowHunt leverer fornuftige standardindstillinger til hurtig opsætning og eksperimentering.
Forbedr dine arbejdsgange med AI-drevet billedforståelse—prøv Visionværktøjet i FlowHunt i dag.
Udforsk Photomatic AI-billedgenerator-komponenten—omdan tekstprompter til AI-genererede billeder i høj kvalitet med avancerede modeller, tilpassede effekter og ...
Generer fantastiske billeder ud fra tekstprompter med Flux Billedgenerator-komponenten i FlowHunt. Tilpas output med modelvalg, billedformat og vejledningsmulig...
Dette workflow tager brugerindsendte billedgenereringsprompter og forfiner dem ved hjælp af AI-best practices, hvilket sikrer, at prompterne er detaljerede, bes...