
Insight Engine
Opdag, hvad en Insight Engine er—en avanceret, AI-drevet platform, der forbedrer datasøgning og analyse ved at forstå kontekst og hensigt. Lær hvordan Insight E...
10 min læsning
AI
Insight Engine
+5

AI-søgning udnytter maskinlæring og vektorembeddings til at forstå søgeintention og kontekst og leverer meget relevante resultater ud over præcise nøgleordsmatch.
AI-søgning bruger maskinlæring til at forstå konteksten og intentionen bag søgeforespørgsler ved at omdanne dem til numeriske vektorer for mere præcise resultater. I modsætning til traditionelle nøgleordssøgninger fortolker AI-søgning semantiske relationer, hvilket gør den effektiv til forskellige datatyper og sprog.
AI-søgning, ofte kaldet semantisk eller vektorsøgning, er en søgemetode, der udnytter maskinlæringsmodeller til at forstå intentionen og den kontekstuelle betydning bag søgeforespørgsler. I modsætning til traditionel søgning baseret på nøgleord omdanner AI-søgning data og forespørgsler til numeriske repræsentationer kendt som vektorer eller embeddings. Dette gør det muligt for søgemaskinen at forstå de semantiske relationer mellem forskellige datastykker, så den kan levere mere relevante og præcise resultater, selv når de præcise nøgleord ikke er til stede.
AI-søgning repræsenterer en betydelig udvikling inden for søgeteknologier. Traditionelle søgemaskiner er stærkt afhængige af nøgleordsmatch, hvor tilstedeværelsen af specifikke termer i både forespørgslen og dokumenterne afgør relevansen. AI-søgning bruger derimod maskinlæringsmodeller til at opfange den underliggende kontekst og betydning af forespørgsler og data.
Ved at omdanne tekst, billeder, lyd og andre ustrukturerede data til høj-dimensionelle vektorer kan AI-søgning måle ligheden mellem forskellige indholdsstykker. Denne tilgang gør det muligt for søgemaskinen at levere resultater, der er kontekstuelt relevante, selvom de ikke indeholder de præcise nøgleord, der anvendes i søgeforespørgslen.
Nøglekomponenter:
Kernen i AI-søgning er vektorembeddings. Vektorembeddings er numeriske repræsentationer af data, der indfanger den semantiske betydning af tekst, billeder eller andre datatyper. Disse embeddings placerer lignende datastykker tæt på hinanden i et multi-dimensionelt vektor-rum.
Sådan fungerer det:
Eksempel:
Traditionelle søgemaskiner baseret på nøgleord fungerer ved at matche termer i søgeforespørgslen med dokumenter, der indeholder disse termer. De er afhængige af teknikker som omvendte indeks og termfrekvens til at rangere resultater.
Begrænsninger ved nøgleordssøgning:
Fordele ved AI-søgning:
| Aspekt | Nøgleordssøgning | AI-søgning (Semantisk/Vektor) |
|---|---|---|
| Matchning | Præcise nøgleordsmatch | Semantisk lighed |
| Kontekstforståelse | Begrænset | Høj |
| Håndtering af synonymer | Kræver manuelle synonym-lister | Automatisk via embeddings |
| Stavefejl | Kan fejle uden “fuzzy search” | Mere tolerant pga. semantisk kontekst |
| Forståelse af intention | Minimal | Betydelig |
Semantisk søgning er en kerneapplikation af AI-søgning, der fokuserer på at forstå brugerens intention og den kontekstuelle betydning af forespørgsler.
Proces:
Nøgleteknikker:
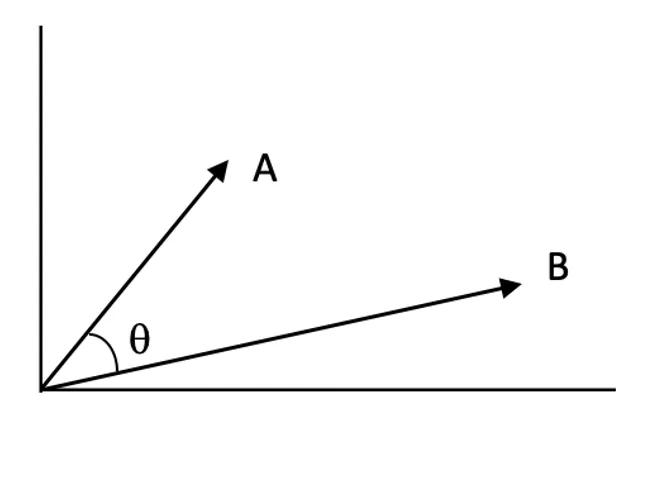
Ligedhedsscorer:
Ligedhedsscorer kvantificerer, hvor tæt to vektorer er på hinanden i vektor-rummet. En højere score indikerer større relevans mellem forespørgslen og et dokument.
Approximate Nearest Neighbor (ANN)-algoritmer:
At finde præcise nærmeste naboer i høj-dimensionelle rum er ressourcekrævende. ANN-algoritmer giver effektive tilnærmelser.
AI-søgning åbner op for en bred vifte af anvendelser på tværs af brancher, fordi den kan forstå og fortolke data ud over simple nøgleordsmatch.
Beskrivelse: Semantisk søgning forbedrer brugeroplevelsen ved at fortolke intentionen bag forespørgsler og levere kontekstuelt relevante resultater.
Eksempler:
Beskrivelse: Ved at forstå brugerpræferencer og -adfærd kan AI-søgning levere personlige anbefalinger på indhold eller produkter.
Eksempler:
Beskrivelse: AI-søgning gør systemer i stand til at forstå og besvare brugerforespørgsler med præcis information, der er udtrukket fra dokumenter.
Eksempler:
Beskrivelse: AI-søgning kan indeksere og søge i ustrukturerede datatyper som billeder, lyd og video ved at konvertere dem til embeddings.
Eksempler:
Integration af AI-søgning i AI-automatisering og chatbots forbedrer deres evner betydeligt.
Fordele:
Implementeringstrin:
Anvendelsestilfælde:
Selvom AI-søgning tilbyder mange fordele, er der udfordringer at tage højde for:
Afhjælpningsstrategier:
Semantisk og vektorsøgning i AI er opstået som kraftfulde alternativer til traditionel søgning baseret på nøgleord og fuzzy search og forbedrer væsentligt relevansen og nøjagtigheden af søgeresultater ved at forstå konteksten og betydningen bag forespørgsler.
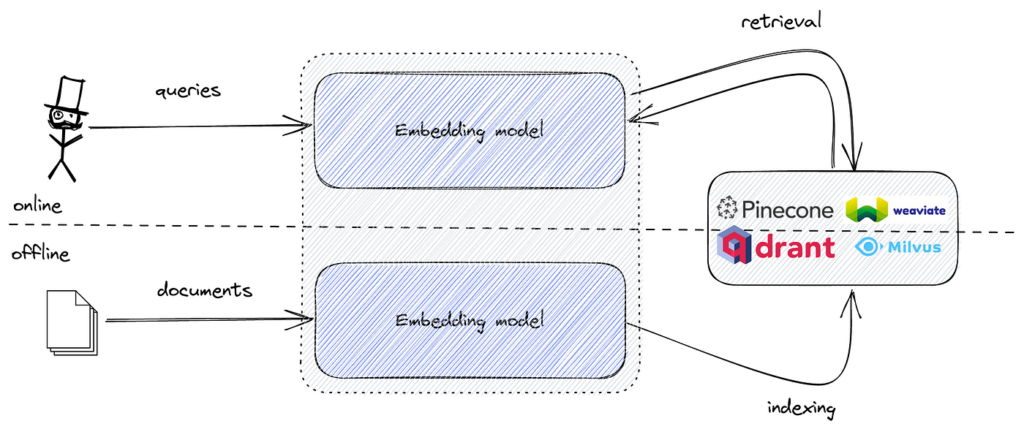
Når man implementerer semantisk søgning, omdannes tekstdata til vektorembeddings, der indfanger tekstens semantiske betydning. Disse embeddings er høj-dimensionelle numeriske repræsentationer. For effektivt at søge i disse embeddings og finde de mest lignende i forhold til en forespørgselsembedding, kræves et værktøj, der er optimeret til lignende søgning i høj-dimensionelle rum.
FAISS leverer de nødvendige algoritmer og datastrukturer til at udføre denne opgave effektivt. Ved at kombinere semantiske embeddings med FAISS kan man oprette en kraftfuld semantisk søgemaskine, der kan håndtere store datasæt med lav latenstid.
Implementering af semantisk søgning med FAISS i Python omfatter flere trin:
Lad os gennemgå hvert trin i detaljer.
Forbered dit datasæt (f.eks. artikler, supporthenvendelser, produktbeskrivelser).
Eksempel:
documents = [
"How to reset your password on our platform.",
"Troubleshooting network connectivity issues.",
"Guide to installing software updates.",
"Best practices for data backup and recovery.",
"Setting up two-factor authentication for enhanced security."
]
Rens og formater tekstdataene efter behov.
Konverter tekstdataene til vektorembeddings ved hjælp af prætrænede Transformer-modeller fra biblioteker som Hugging Face (transformers eller sentence-transformers).
Eksempel:
from sentence_transformers import SentenceTransformer
import numpy as np
# Indlæs en prætrænet model
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
# Generer embeddings for alle dokumenter
embeddings = model.encode(documents, convert_to_tensor=False)
embeddings = np.array(embeddings).astype('float32')
float32, som krævet af FAISS.Opret et FAISS-indeks til at lagre embeddings og muliggøre effektiv lignende søgning.
Eksempel:
import faiss
embedding_dim = embeddings.shape[1]
index = faiss.IndexFlatL2(embedding_dim)
index.add(embeddings)
IndexFlatL2 udfører brute-force-søgning med L2 (euklidisk) afstand.Konverter brugerens forespørgsel til en embedding og find de nærmeste naboer.
Eksempel:
query = "How do I change my account password?"
query_embedding = model.encode([query], convert_to_tensor=False)
query_embedding = np.array(query_embedding).astype('float32')
k = 3
distances, indices = index.search(query_embedding, k)
Brug indeksene til at vise de mest relevante dokumenter.
Eksempel:
print("Top results for your query:")
for idx in indices[0]:
print(documents[idx])
Forventet output:
Top results for your query:
How to reset your password on our platform.
Setting up two-factor authentication for enhanced security.
Best practices for data backup and recovery.
FAISS tilbyder flere typer indekser:
Brug af et Inverted File Index (IndexIVFFlat):
nlist = 100
quantizer = faiss.IndexFlatL2(embedding_dim)
index = faiss.IndexIVFFlat(quantizer, embedding_dim, nlist, faiss.METRIC_L2)
index.train(embeddings)
index.add(embeddings)
Normalisering og søgning med indre produkt:
Brug af cosinuslighed kan være mere effektivt for tekstdata
AI-søgning er en moderne søgemetode, der bruger maskinlæring og vektorembeddings til at forstå intentionen og den kontekstuelle betydning af forespørgsler og leverer mere præcise og relevante resultater end traditionel søgning baseret på nøgleord.
I modsætning til søgning baseret på nøgleord, som er afhængig af præcise match, fortolker AI-søgning de semantiske relationer og intentionen bag forespørgsler, hvilket gør den effektiv til naturligt sprog og tvetydige input.
Vektorembeddings er numeriske repræsentationer af tekst, billeder eller andre datatyper, der indfanger deres semantiske betydning og gør det muligt for søgemaskinen at måle lighed og kontekst mellem forskellige datastykker.
AI-søgning driver semantisk søgning i e-handel, personlige anbefalinger i streaming, spørgsmål-svar-systemer i kundesupport, browsing i ustrukturerede data og dokumenthentning i forskning og virksomheder.
Populære værktøjer inkluderer FAISS til effektiv vektorlignende søgning og vektordatabaser som Pinecone, Milvus, Qdrant, Weaviate, Elasticsearch og Pgvector til skalerbar lagring og hentning af embeddings.
Ved at integrere AI-søgning kan chatbots og automatiseringssystemer forstå brugerforespørgsler dybere, hente kontekstuelt relevante svar og levere dynamiske, personlige svar.
Udfordringer inkluderer høje computerkrav, kompleksitet i model-fortolkning, behov for data af høj kvalitet samt sikring af privatliv og sikkerhed med følsomme oplysninger.
FAISS er et open source-bibliotek til effektiv lignende søgning på høj-dimensionelle vektorembeddings og bruges bredt til at bygge semantiske søgemaskiner, der kan håndtere store datasæt.
Opdag, hvordan AI-drevet semantisk søgning kan transformere din informationssøgning, chatbots og automatiseringsworkflows.
Opdag, hvad en Insight Engine er—en avanceret, AI-drevet platform, der forbedrer datasøgning og analyse ved at forstå kontekst og hensigt. Lær hvordan Insight E...
Informationssøgning udnytter AI, NLP og maskinlæring til effektivt og præcist at hente data, der opfylder brugerens behov. Grundlæggende for websøgemaskiner, di...
FlowHunts GoogleSearch-komponent forbedrer chatbot-præcisionen ved hjælp af Retrieval-Augmented Generation (RAG) til at få adgang til opdateret viden fra Google...