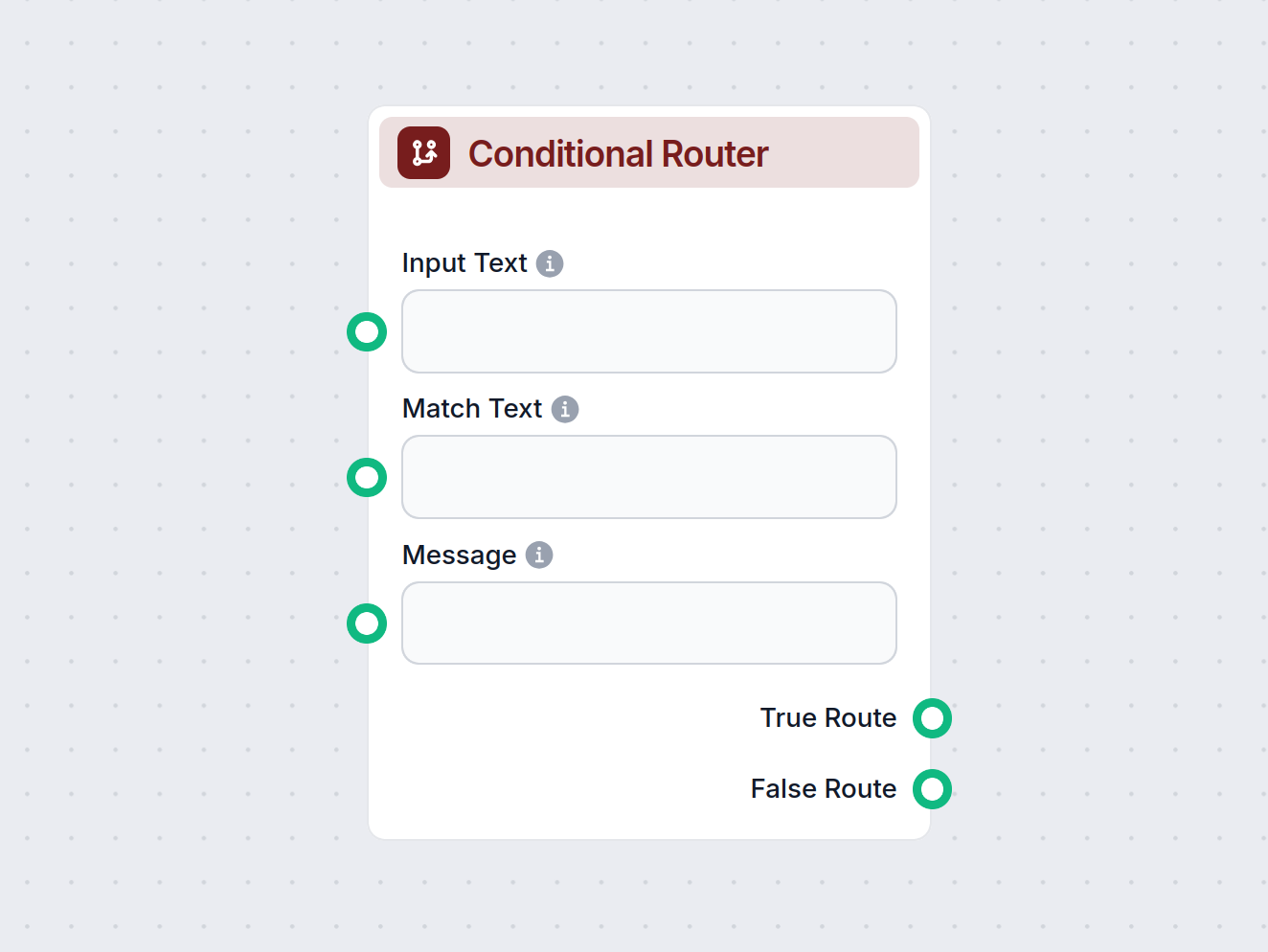
Betinget Router
Betinget Router-komponenten muliggør dynamiske beslutninger i dit workflow. Den sammenligner inputtekst med en angivet værdi ved hjælp af forskellige operatorer...
2 min læsning
Automation
Logic
+4
BERT er en banebrydende NLP-model fra Google, der bruger bidirektionelle Transformere til at gøre maskiner i stand til at forstå sprog kontekstuelt og dermed drive avancerede AI-applikationer.
BERT, som står for Bidirectional Encoder Representations from Transformers, er en open source maskinlæringsramme til naturlig sprogbehandling (NLP). Udviklet af forskere hos Google AI Language og introduceret i 2018, har BERT markant fremmet NLP ved at gøre maskiner i stand til at forstå sprog mere som mennesker.
I sin kerne hjælper BERT computere med at tolke betydningen af tvetydigt eller kontekstafhængigt sprog i tekst ved at tage hensyn til de omkringliggende ord i en sætning – både før og efter det målte ord. Denne bidirektionelle tilgang gør BERT i stand til at opfange sprogets fulde nuancer og gør den meget effektiv til en bred vifte af NLP-opgaver.
Før BERT behandlede de fleste sprogmodeller tekst envejs (enten fra venstre mod højre eller omvendt), hvilket begrænsede deres evne til at opfange kontekst.
Tidligere modeller som Word2Vec og GloVe genererede kontekstfrie word embeddings, hvor hvert ord fik tildelt en enkelt vektor uanset kontekst. Denne tilgang havde svært ved at håndtere ord med flere betydninger (f.eks. “bank” som pengeinstitut vs. flodbred).
I 2017 blev Transformer-arkitekturen introduceret i artiklen “Attention Is All You Need.” Transformere er deep learning-modeller, der bruger self-attention, så de dynamisk kan vægte betydningen af hver del af inputtet.
Transformere revolutionerede NLP ved at bearbejde alle ord i en sætning samtidigt, hvilket gjorde større træningsskala mulig.
Google-forskere byggede videre på Transformer-arkitekturen og udviklede BERT, som blev introduceret i 2018-artiklen “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.” BERT’s nyskabelse var at anvende bidirektionel træning, hvor både venstre og højre kontekst blev taget i betragtning.
BERT blev fortrænet på hele den engelske Wikipedia (2,5 milliarder ord) og BookCorpus (800 millioner ord), hvilket gav den en dyb forståelse af mønstre, syntaks og semantik.
BERT er et encoder-stack af Transformer-arkitekturen (bruger kun encoderen, ikke decoderen). Den består af flere lag (12 eller 24 Transformer-blokke), hver med self-attention og feed-forward neurale netværk.
BERT bruger WordPiece-tokenisering, hvor ord opdeles i delord for at håndtere sjældne eller ukendte ord.
Hvert input-token repræsenteres som summen af tre embeddings:
Disse hjælper BERT med at forstå både struktur og semantik.
Self-attention gør det muligt for BERT at vægte betydningen af hvert token i forhold til alle andre i sekvensen og opfange afhængigheder uanset afstand.
For eksempel, i “The bank raised its interest rates,” hjælper self-attention BERT med at forbinde “bank” til “interest rates” og forstå “bank” som et pengeinstitut.
BERT’s bidirektionelle træning gør det muligt at opfange konteksten fra begge retninger. Dette opnås gennem to træningsmål:
I MLM vælger BERT tilfældigt 15% af tokens til mulig udskiftning:
[MASK]Denne strategi fremmer en dybere sprogforståelse.
Eksempel:
[MASK] jumps over the lazy [MASK].”NSP hjælper BERT med at forstå forholdet mellem sætninger.
Eksempler:
Efter fortræning finjusteres BERT til specifikke NLP-opgaver ved at tilføje outputlag. Finjustering kræver mindre data og beregning end træning fra bunden.
BERT driver mange NLP-opgaver og opnår ofte state-of-the-art resultater.
BERT kan klassificere sentiment (f.eks. positive/negative anmeldelser) med stor nuancering.
BERT forstår spørgsmål og leverer svar ud fra kontekst.
NER identificerer og klassificerer nøgleenheder (navne, organisationer, datoer).
Selvom BERT ikke er designet til oversættelse, hjælper dens dybe sprogforståelse oversættelse, når den kombineres med andre modeller.
BERT kan generere korte sammenfatninger ved at identificere nøglekoncepter.
BERT forudsiger maskerede ord eller sekvenser og hjælper med tekstgenerering.
I 2019 begyndte Google at bruge BERT til at forbedre søgealgoritmerne og forstå kontekst og hensigt bag forespørgsler.
Eksempel:
BERT driver chatbots og forbedrer forståelsen af brugerinput.
Specialiserede BERT-modeller som BioBERT bearbejder biomedicinske tekster.
Juridiske fagfolk bruger BERT til at analysere og sammenfatte juridiske tekster.
Der findes flere BERT-tilpasninger for effektivitet eller specifikke domæner:
BERT’s kontekstuelle forståelse driver talrige AI-applikationer:
BERT har i høj grad forbedret kvaliteten af chatbots og AI-automatisering.
Eksempler:
BERT muliggør AI-automatisering til at bearbejde store tekstmængder uden menneskelig indgriben.
Anvendelser:
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Forfattere: Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova
Introducerer BERT’s arkitektur og effektivitet på flere benchmarks, så modellen kan tage hensyn til både venstre og højre kontekst.
Læs mere
Multi-Task Bidirectional Transformer Representations for Irony Detection
Forfattere: Chiyu Zhang, Muhammad Abdul-Mageed
Anvender BERT til ironidetektion, udnytter multitask learning og pretræning til domænetilpasning. Opnår 82,4 macro F1-score.
Læs mere
Sketch-BERT: Learning Sketch Bidirectional Encoder Representation from Transformers by Self-supervised Learning of Sketch Gestalt
Forfattere: Hangyu Lin, Yanwei Fu, Yu-Gang Jiang, Xiangyang Xue
Introducerer Sketch-BERT til skitsetegningsgenkendelse og -søgning, anvender selv-superviseret læring og nye embedding-netværk.
Læs mere
Transferring BERT Capabilities from High-Resource to Low-Resource Languages Using Vocabulary Matching
Forfatter: Piotr Rybak
Foreslår vokabulartilpasning for at gøre det muligt at anvende BERT på lavressourcesprog og demokratisere NLP-teknologi.
Læs mere
BERT (Bidirectional Encoder Representations from Transformers) er en open source maskinlæringsramme til naturlig sprogbehandling, udviklet af Google AI i 2018. Den gør det muligt for maskiner at forstå sprog kontekstuelt ved at tage hensyn til kontekst fra begge sider af et ord ved hjælp af Transformer-arkitekturen.
I modsætning til tidligere envejsmodeller behandler BERT tekst i begge retninger, hvilket gør det muligt at opfange den fulde kontekst af et ord ved at se både de foregående og efterfølgende ord. Dette giver en dybere forståelse af sprogets nuancer og forbedrer præstationen på tværs af NLP-opgaver.
BERT bruges bredt til sentimentanalyse, spørgsmål-besvarelse, navngiven entitetsgenkendelse, sprogoversættelse, tekstsammenfatning, tekstgenerering og til at forbedre AI-chatbots og automatiseringssystemer.
Populære BERT-varianter inkluderer DistilBERT (en lettere version), TinyBERT (optimeret til hastighed og størrelse), RoBERTa (med optimeret pretræning), BioBERT (til biomedicinsk tekst) og domænespecifikke modeller som PatentBERT og SciBERT.
BERT fortrænes ved hjælp af Masked Language Modeling (MLM), hvor tilfældige ord maskeres og forudsiges, og Next Sentence Prediction (NSP), hvor modellen lærer forholdet mellem sætningspar. Efter fortræning finjusteres den til specifikke NLP-opgaver med yderligere lag.
BERT har i høj grad forbedret den kontekstuelle forståelse i AI-chatbots og automatiseringsværktøjer, hvilket muliggør mere præcise svar, bedre kundesupport og forbedret dokumentbehandling med minimal menneskelig indgriben.
Smarte chatbots og AI-værktøjer samlet ét sted. Forbind intuitive blokke og forvandl dine ideer til automatiserede Flows.
Betinget Router-komponenten muliggør dynamiske beslutninger i dit workflow. Den sammenligner inputtekst med en angivet værdi ved hjælp af forskellige operatorer...
Natural Language Toolkit (NLTK) er en omfattende samling af Python-biblioteker og -programmer til symbolsk og statistisk behandling af naturligt sprog (NLP). Br...
Perplexity AI er en avanceret AI-drevet søgemaskine og samtaleværktøj, der udnytter NLP og maskinlæring til at levere præcise, kontekstuelle svar med kildehenvi...

