MLflow
MLflow er en open source-platform designet til at strømline og håndtere maskinlæringslivscyklussen. Den tilbyder værktøjer til eksperimentsporing, kodepakning, ...
5 min læsning
MLflow
Machine Learning
+3
Kubeflow er en open source ML-platform bygget på Kubernetes, der effektiviserer udrulning, administration og skalering af maskinlæringsarbejdsgange på tværs af forskellige infrastrukturer.
Kubeflows mission er at gøre skalering af ML-modeller og deres udrulning til produktion så enkel som muligt ved at udnytte Kubernetes’ muligheder. Dette omfatter nemme, gentagelige og bærbare udrulninger på tværs af forskellige infrastrukturer. Platformen startede som en metode til at køre TensorFlow-jobs på Kubernetes og har siden udviklet sig til en alsidig ramme, der understøtter en bred vifte af ML-frameworks og værktøjer.
Kubeflow Pipelines er en kernekomponent, der gør det muligt for brugere at definere og udføre ML-arbejdsgange som Directed Acyclic Graphs (DAGs). Den tilbyder en platform til at bygge bærbare og skalerbare maskinlæringsarbejdsgange med Kubernetes. Pipelines-komponenten består af:
Disse funktioner gør det muligt for datavidenskabsfolk at automatisere hele processen fra datapreprocessing, modeltræning, evaluering og udrulning, hvilket fremmer reproducerbarhed og samarbejde i ML-projekter. Platformen understøtter genbrug af komponenter og pipelines, hvilket effektiviserer oprettelsen af ML-løsninger.
Kubeflows centrale dashboard fungerer som hovedgrænseflade for adgang til Kubeflow og dets økosystem. Det samler brugergrænsefladerne fra forskellige værktøjer og tjenester i klyngen og giver et samlet adgangspunkt til administration af maskinlæringsaktiviteter. Dashboardet tilbyder funktioner som brugergodkendelse, multi-bruger isolation og ressourceadministration.
Kubeflow integrerer med Jupyter Notebooks og tilbyder et interaktivt miljø til dataudforskning, eksperimentering og modeludvikling. Notebooks understøtter forskellige programmeringssprog og giver brugere mulighed for at oprette og udføre ML-arbejdsgange i fællesskab.
Kubeflow Metadata er et centralt lager til sporing og administration af metadata tilknyttet ML-eksperimenter, kørsler og artefakter. Det sikrer reproducerbarhed, samarbejde og governance på tværs af ML-projekter ved at give et ensartet overblik over ML-metadata.
Katib er en komponent til automatiseret maskinlæring (AutoML) i Kubeflow. Den understøtter hyperparametertuning, early stopping og neural arkitektursøgning, hvilket optimerer ML-modellers ydeevne ved at automatisere søgningen efter optimale hyperparametre.
Kubeflow bruges af organisationer på tværs af brancher til at effektivisere deres ML-operationer. Nogle typiske anvendelsesområder inkluderer:
Spotify anvender Kubeflow til at give sine datavidenskabsfolk og ingeniører mulighed for at udvikle og udrulle maskinlæringsmodeller i stor skala. Ved at integrere Kubeflow med deres eksisterende infrastruktur har Spotify effektiviseret sine ML-arbejdsgange, reduceret time-to-market for nye funktioner og forbedret effektiviteten af deres anbefalingssystemer.
Kubeflow gør det muligt for organisationer at skalere deres ML-arbejdsgange op eller ned efter behov og udrulle dem på tværs af forskellige infrastrukturer, herunder lokale, cloud og hybride miljøer. Denne fleksibilitet hjælper med at undgå vendor lock-in og muliggør problemfrie overgange mellem forskellige computermiljøer.
Kubeflows komponentbaserede arkitektur gør det nemt at genskabe eksperimenter og modeller. Platformen tilbyder værktøjer til versionering og tracking af datasæt, kode og modelparametre, hvilket sikrer konsistens og samarbejde mellem datavidenskabsfolk.
Kubeflow er designet til at være udvidelig, så integration med andre værktøjer og tjenester – herunder cloudbaserede ML-platforme – er mulig. Organisationer kan tilpasse Kubeflow med yderligere komponenter og udnytte eksisterende værktøjer og arbejdsgange for at styrke deres ML-økosystem.
Ved at automatisere mange af de opgaver, der er forbundet med udrulning og administration af ML-arbejdsgange, frigiver Kubeflow tid for datavidenskabsfolk og ingeniører, så de kan fokusere på værdiskabende arbejde som modeludvikling og optimering, hvilket øger produktivitet og effektivitet.
Kubeflows integration med Kubernetes giver mulighed for mere effektiv ressourceudnyttelse, optimering af hardwareallokering og reducerede omkostninger forbundet med drift af ML-arbejdsgange.
For at komme i gang kan brugere udrulle Kubeflow på en Kubernetes-klynge, enten lokalt eller i skyen. Der findes forskellige installationsvejledninger, der dækker forskellige erfaringsniveauer og infrastrukturbehov. For dem, der er nye i Kubernetes, tilbyder managed services som Vertex AI Pipelines en mere tilgængelig start, hvor infrastrukturen håndteres, så brugerne kan fokusere på at bygge og køre ML-arbejdsgange.
Denne detaljerede gennemgang af Kubeflow giver indsigt i dets funktionalitet, fordele og anvendelsesområder og tilbyder en omfattende forståelse for organisationer, der ønsker at styrke deres maskinlæringskapaciteter.
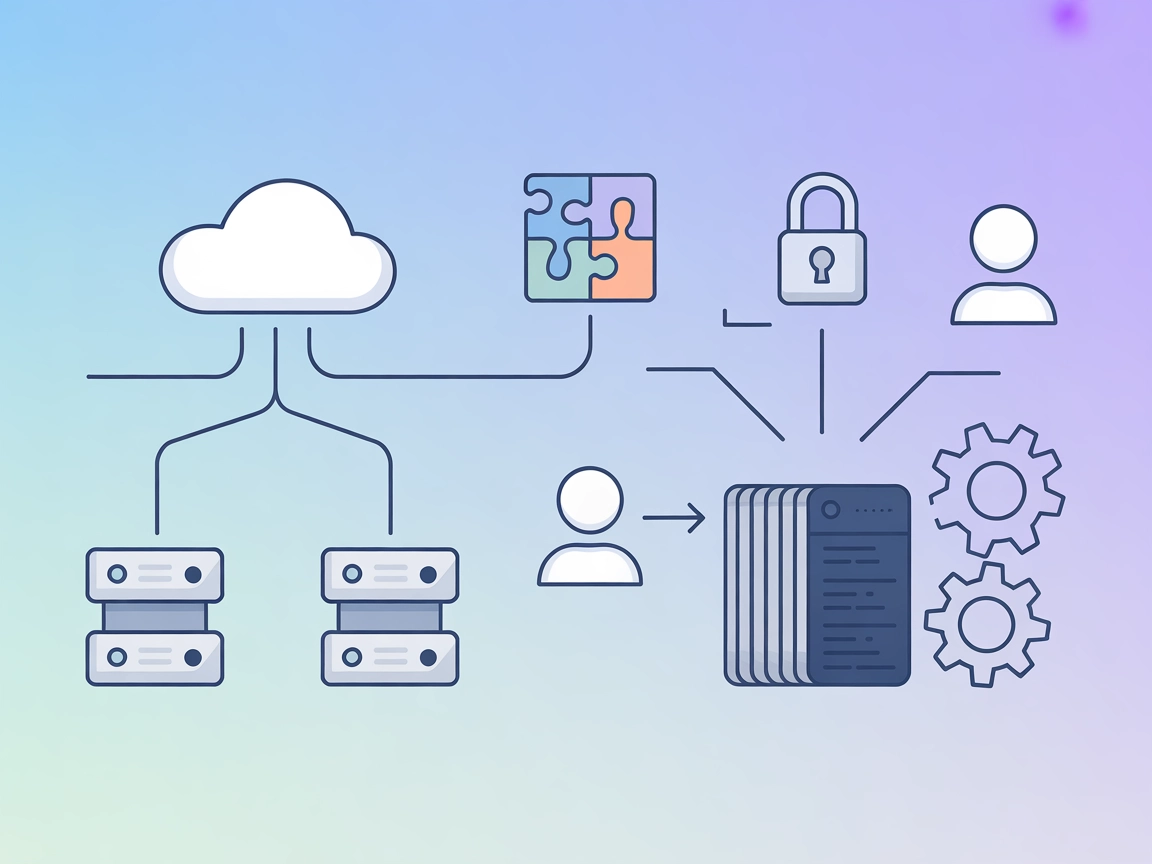
Kubeflow er et open source-projekt designet til at lette udrulning, orkestrering og administration af maskinlæringsmodeller på Kubernetes. Det tilbyder en omfattende end-to-end stack til maskinlæringsarbejdsgange, hvilket gør det lettere for datavidenskabsfolk og ingeniører at bygge, udrulle og administrere skalerbare maskinlæringsmodeller.
Deployment of ML Models using Kubeflow on Different Cloud Providers
Forfattere: Aditya Pandey m.fl. (2022)
Denne artikel undersøger udrulning af maskinlæringsmodeller med Kubeflow på forskellige cloud-platforme. Studiet giver indsigt i opsætningsprocessen, udrulningsmodeller og performancemålinger for Kubeflow og fungerer som en nyttig guide for begyndere. Forfatterne fremhæver værktøjets funktioner og begrænsninger og demonstrerer brugen til at skabe end-to-end maskinlæringspipelines. Artiklen har til formål at hjælpe brugere med minimal Kubernetes-erfaring til at udnytte Kubeflow til modeludrulning.
Læs mere
CLAIMED, a visual and scalable component library for Trusted AI
Forfattere: Romeo Kienzler og Ivan Nesic (2021)
Dette arbejde fokuserer på integration af Trusted AI-komponenter med Kubeflow. Det adresserer emner som forklarbarhed, robusthed og fairness i AI-modeller. Artiklen introducerer CLAIMED, et genanvendeligt komponentframework, der inkorporerer værktøjer som AI Explainability360 og AI Fairness360 i Kubeflow pipelines. Denne integration letter udviklingen af produktionsklare maskinlæringsapplikationer ved brug af visuelle editorer som ElyraAI.
Læs mere
Jet energy calibration with deep learning as a Kubeflow pipeline
Forfattere: Daniel Holmberg m.fl. (2023)
Kubeflow bruges til at oprette en maskinlæringspipeline til kalibrering af jetenergimålinger ved CMS-eksperimentet. Forfatterne anvender dybe neurale netværk til at forbedre jetenergi-kalibreringen og viser, hvordan Kubeflows muligheder kan udvides til højenergifysik. Artiklen diskuterer pipeline’ens effektivitet i skalering af hyperparametertuning og effektiv modeludrulning på cloud-ressourcer.
Læs mere
Kubeflow er en open source-platform bygget på Kubernetes, der er designet til at effektivisere udrulning, administration og skalering af maskinlæringsarbejdsgange. Den tilbyder et omfattende sæt værktøjer til hele ML-livscyklussen.
Nøglekomponenter inkluderer Kubeflow Pipelines til orkestrering af arbejdsgange, et centralt dashboard, integration med Jupyter Notebooks, distribueret modeltræning og -udrulning, metadatahåndtering og Katib til hyperparametertuning.
Ved at udnytte Kubernetes muliggør Kubeflow skalerbare ML-arbejdsgange på tværs af forskellige miljøer og tilbyder værktøjer til eksperiment-tracking og komponentgenbrug, hvilket sikrer reproducerbarhed og effektivt samarbejde.
Organisationer på tværs af brancher bruger Kubeflow til at administrere og skalere deres ML-operationer. Bemærkelsesværdige brugere som Spotify har integreret Kubeflow for at effektivisere modeludvikling og udrulning.
For at komme i gang skal du udrulle Kubeflow på et Kubernetes-klynge – enten lokalt eller i skyen. Installationsvejledninger og managed services er tilgængelige for at hjælpe brugere på alle erfaringsniveauer.
Opdag hvordan Kubeflow kan forenkle dine maskinlæringsarbejdsgange på Kubernetes – fra skalerbar træning til automatiseret udrulning.
MLflow er en open source-platform designet til at strømline og håndtere maskinlæringslivscyklussen. Den tilbyder værktøjer til eksperimentsporing, kodepakning, ...
Integrer FlowHunt med KubeSphere MCP Server for at automatisere Kubernetes-ressourcestyring, strømline klyngeoperationer og forbedre DevOps-arbejdsgange ved hjæ...
Integrer FlowHunt med Metoro MCP Server for at give AI-agenter realtids-Kubernetes-observabilitet. Udnyt eBPF-drevet telemetri, Model Context Protocol og sømløs...