
Maskinlæring
Maskinlæring (ML) er en underkategori af kunstig intelligens (AI), der gør det muligt for maskiner at lære af data, identificere mønstre, lave forudsigelser og ...
3 min læsning
Machine Learning
AI
+4
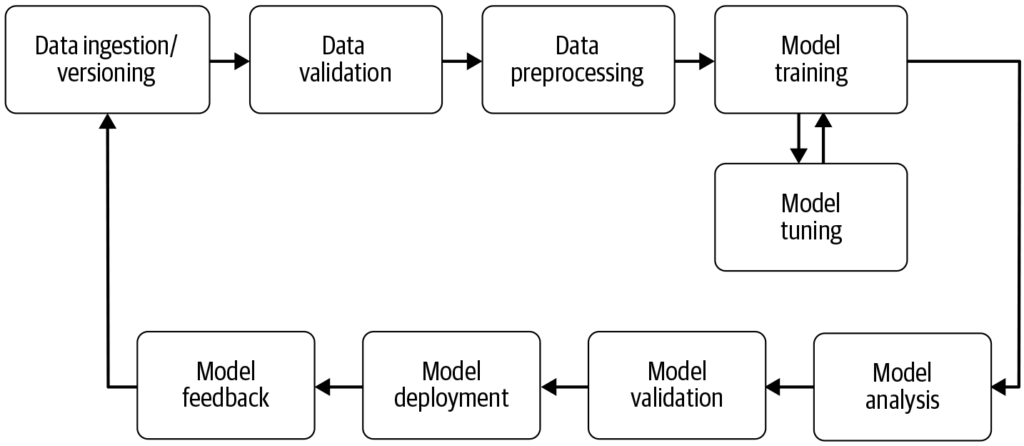
En maskinlæringspipeline automatiserer trinnene fra dataindsamling til modelimplementering og øger effektiviteten, reproducerbarheden og skalerbarheden i maskinlæringsprojekter.
En maskinlæringspipeline er et automatiseret workflow, der strømliner udvikling, træning, evaluering og implementering af modeller. Den øger effektiviteten, reproducerbarheden og skalerbarheden og letter opgaver fra dataindsamling til modelimplementering og vedligeholdelse.
En maskinlæringspipeline er et automatiseret workflow, der omfatter en række trin i udvikling, træning, evaluering og implementering af maskinlæringsmodeller. Den er designet til at strømliner og standardisere processerne, der kræves for at omdanne rå data til handlingsrettede indsigter via maskinlæringsalgoritmer. Pipeline-tilgangen muliggør effektiv håndtering af data, modeltræning og implementering, hvilket gør det lettere at administrere og skalere maskinlæringsoperationer.
Kilde: Building Machine Learning
Dataindsamling: Den indledende fase, hvor data indsamles fra forskellige kilder som databaser, API’er eller filer. Dataindsamling er en metodisk praksis med det formål at opnå meningsfuld information for at opbygge et konsistent og komplet datagrundlag til et specifikt forretningsformål. Disse rå data er essentielle for opbygning af maskinlæringsmodeller, men kræver ofte præprocessering for at være brugbare. Som fremhævet af AltexSoft indebærer dataindsamling systematisk akkumulering af information for at understøtte analyse og beslutningstagning. Denne proces er afgørende, da den lægger fundamentet for alle efterfølgende trin i pipelinen og ofte er kontinuerlig for at sikre, at modeller trænes på relevante og opdaterede data.
Datapræprocessering: Rå data renses og omdannes til et egnet format for modeltræning. Almindelige præprocesseringsskridt inkluderer håndtering af manglende værdier, kodning af kategoriske variabler, skalering af numeriske features og opdeling af data i trænings- og testdatasæt. Dette trin sikrer, at dataene har det korrekte format og er fri for inkonsistenser, der kan påvirke modelpræstationen.
Feature Engineering: Oprettelse af nye features eller udvælgelse af relevante features fra dataene for at forbedre modellens forudsigelsesevne. Dette trin kan kræve domænespecifik viden og kreativitet. Feature engineering er en kreativ proces, der omdanner rå data til meningsfulde features, som bedre repræsenterer det underliggende problem og øger præstationen af maskinlæringsmodeller.
Modelvalg: Den passende maskinlæringsalgoritme vælges baseret på problemtype (f.eks. klassifikation, regression), datakarakteristika og præstationskrav. Hyperparametertuning kan også overvejes i dette trin. Valget af den rette model er afgørende, da det påvirker nøjagtigheden og effektiviteten af forudsigelserne.
Modeltræning: Den valgte model trænes ved hjælp af træningsdatasættet. Dette indebærer, at modellen lærer de underliggende mønstre og sammenhænge i dataene. Prætrænede modeller kan også bruges i stedet for at træne en ny model fra bunden. Træning er et vigtigt trin, hvor modellen lærer af dataene for at kunne foretage informerede forudsigelser.
Modelevaluering: Efter træningen vurderes modellens præstation ved hjælp af et separat testdatasæt eller via krydsvalidering. Evalueringsmetrikker afhænger af det konkrete problem, men kan inkludere nøjagtighed, præcision, recall, F1-score, middelkvadreret fejl m.fl. Dette trin er afgørende for at sikre, at modellen præsterer godt på ukendte data.
Modelimplementering: Når en tilfredsstillende model er udviklet og evalueret, kan den implementeres i et produktionsmiljø til at foretage forudsigelser på nye, ukendte data. Implementering kan indebære oprettelse af API’er og integration med andre systemer. Implementering er det afsluttende trin i pipelinen, hvor modellen gøres tilgængelig til brug i virkeligheden.
Overvågning og vedligeholdelse: Efter implementering er det afgørende løbende at overvåge modellens præstation og genoptræne den efter behov for at tilpasse sig ændrede dataprofiler, og sikre at modellen forbliver nøjagtig og pålidelig i praksis. Denne løbende proces sikrer, at modellen forbliver relevant og præcis over tid.
Naturlig sprogbehandling (NLP): NLP-opgaver involverer ofte flere gentagelige trin som dataindsamling, tekstbehandling, tokenisering og sentimentanalyse. Pipelines hjælper med at modulopdele disse trin, så ændringer let kan foretages uden at påvirke andre komponenter.
Prædiktiv vedligeholdelse: I brancher som produktion kan pipelines bruges til at forudsige udstyrsfejl ved at analysere sensordata, hvilket muliggør proaktiv vedligeholdelse og reducerer nedetid.
Finans: Pipelines kan automatisere behandlingen af finansielle data for at opdage bedrageri, vurdere kreditrisici eller forudsige aktiekurser og dermed forbedre beslutningsprocesserne.
Sundhedsvæsen: I sundhedssektoren kan pipelines behandle medicinske billeder eller patientjournaler for at assistere i diagnostik eller forudsige patientudfald og derved forbedre behandlingsstrategier.
Maskinlæringspipelines er integreret i AI og automatisering ved at give en struktureret ramme for at automatisere maskinlæringsopgaver. Inden for AI-automatisering sikrer pipelines, at modeller trænes og implementeres effektivt, hvilket gør det muligt for AI-systemer som [chatbots] at lære og tilpasse sig nye data uden manuel indgriben. Denne automatisering er afgørende for at skalere AI-applikationer og sikre, at de leverer ensartet og pålidelig præstation på tværs af forskellige domæner. Ved at udnytte pipelines kan organisationer styrke deres AI-evner og sikre, at deres maskinlæringsmodeller forbliver relevante og effektive i foranderlige miljøer.
Forskning om maskinlæringspipeline
“Deep Pipeline Embeddings for AutoML” af Sebastian Pineda Arango og Josif Grabocka (2023) fokuserer på udfordringerne ved optimering af maskinlæringspipelines i Automated Machine Learning (AutoML). Denne artikel introducerer en ny neural arkitektur, der er designet til at fange dybe interaktioner mellem pipeline-komponenter. Forfatterne foreslår at indlejre pipelines i latente repræsentationer via en unik per-komponent-encoder-mekanisme. Disse indlejrede repræsentationer anvendes inden for en Bayesian Optimization-ramme til at finde optimale pipelines. Artiklen lægger vægt på brugen af meta-læring til at finjustere pipeline-embedding-netværkets parametre og demonstrerer resultater i verdensklasse i pipelineoptimering på tværs af flere datasæt. Læs mere.
“AVATAR — Machine Learning Pipeline Evaluation Using Surrogate Model” af Tien-Dung Nguyen m.fl. (2020) adresserer den tidskrævende evaluering af maskinlæringspipelines under AutoML-processer. Undersøgelsen kritiserer traditionelle metoder som Bayesian og genetiske optimeringer for deres ineffektivitet. For at imødegå dette præsenterer forfatterne AVATAR, en surrogatmodel, der effektivt evaluerer pipeline-gyldighed uden udførelse. Denne tilgang fremskynder sammensætning og optimering af komplekse pipelines betydeligt ved tidligt at filtrere ugyldige pipelines fra. Læs mere.
“Data Pricing in Machine Learning Pipelines” af Zicun Cong m.fl. (2021) undersøger den afgørende rolle, data spiller i maskinlæringspipelines, samt nødvendigheden af datapricing for at fremme samarbejde mellem flere interessenter. Artiklen gennemgår de seneste udviklinger inden for datapricing i maskinlæringskontekst, med fokus på dets betydning på tværs af forskellige pipelinefaser. Den giver indsigt i prisstrategier for indsamling af træningsdata, kollaborativ modeltræning og levering af maskinlæringstjenester og fremhæver dannelsen af et dynamisk økosystem. Læs mere.
En maskinlæringspipeline er en automatiseret sekvens af trin — fra dataindsamling og præprocessering til modeltræning, evaluering og implementering — der strømliner og standardiserer processen med at bygge og vedligeholde maskinlæringsmodeller.
Vigtige komponenter omfatter dataindsamling, datapræprocessering, feature engineering, modelvalg, modeltræning, modelevaluering, modelimplementering samt løbende overvågning og vedligeholdelse.
Maskinlæringspipelines giver modularisering, effektivitet, reproducerbarhed, skalerbarhed, forbedret samarbejde og lettere implementering af modeller i produktionsmiljøer.
Anvendelser inkluderer naturlig sprogbehandling (NLP), prædiktiv vedligeholdelse i produktion, vurdering af finansielle risici og bedrageridetektion samt sundhedsdiagnostik.
Udfordringer inkluderer at sikre datakvalitet, håndtering af pipeline-kompleksitet, integration med eksisterende systemer og styring af omkostninger relateret til computerressourcer og infrastruktur.
Book en demo og opdag, hvordan FlowHunt kan hjælpe dig med at automatisere og skalere dine maskinlæringsworkflows nemt.
Maskinlæring (ML) er en underkategori af kunstig intelligens (AI), der gør det muligt for maskiner at lære af data, identificere mønstre, lave forudsigelser og ...
MLflow er en open source-platform designet til at strømline og håndtere maskinlæringslivscyklussen. Den tilbyder værktøjer til eksperimentsporing, kodepakning, ...
BigML er en maskinlæringsplatform designet til at gøre oprettelse og implementering af prædiktive modeller enklere. Grundlagt i 2011 har platformen til formål a...
