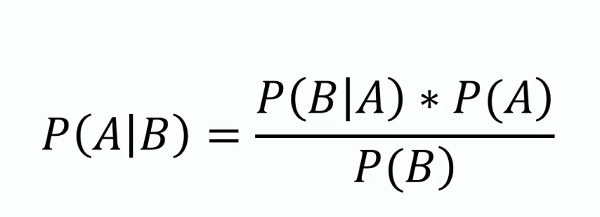

Bayesiske Netværk
Et Bayesisk Netværk (BN) er en probabilistisk grafisk model, der repræsenterer variable og deres betingede afhængigheder via en Rettet Acyklisk Graf (DAG). Baye...
3 min læsning
Bayesian Networks
AI
+3
Naiv Bayes er en simpel, men kraftfuld familie af klassifikationsalgoritmer, der udnytter Bayes’ sætning og ofte bruges til skalerbare opgaver som spamdetektion og tekstklassifikation.
Naiv Bayes er en familie af simple, effektive klassifikationsalgoritmer baseret på Bayes’ sætning og antager betinget uafhængighed mellem features. Den bruges bredt til spamdetektion, tekstklassifikation og meget mere på grund af sin enkelhed og skalerbarhed.
Naiv Bayes er en familie af klassifikationsalgoritmer baseret på Bayes’ sætning, som anvender princippet om betinget sandsynlighed. Udtrykket “naiv” henviser til den forsimplede antagelse, at alle features i et datasæt er betinget uafhængige af hinanden givet klasselabel. Selvom denne antagelse ofte brydes i praksis, er Naiv Bayes-klassifikatorer kendt for deres enkelhed og effektivitet i forskellige anvendelser, såsom tekstklassifikation og spamdetektion.
Bayes’ sætning
Denne sætning danner grundlaget for Naiv Bayes og giver en metode til at opdatere sandsynlighedsestimatet for en hypotese, efterhånden som der kommer mere evidens eller information til. Matematisk udtrykkes den som:
hvor ( P(A|B) ) er den posteriore sandsynlighed, ( P(B|A) ) er likelihood, ( P(A) ) er den forudgående sandsynlighed, og ( P(B) ) er evidens.
Betinget uafhængighed
Den naive antagelse om, at hver feature er uafhængig af alle andre features givet klasselabel. Denne antagelse forenkler beregninger og gør algoritmen i stand til at skalere godt til store datasæt.
Posterior sandsynlighed
Sandsynligheden for klasselabel givet featureværdierne, beregnet ved hjælp af Bayes’ sætning. Dette er det centrale element i forudsigelser med Naiv Bayes.
Typer af Naiv Bayes-klassifikatorer
Naiv Bayes-klassifikatorer arbejder ved at beregne den posteriore sandsynlighed for hver klasse givet et sæt features og vælger den klasse med højest posteriore sandsynlighed. Processen involverer følgende trin:
Naiv Bayes-klassifikatorer er særligt effektive i følgende anvendelser:
Overvej et spamfiltreringssystem, der bruger Naiv Bayes. Træningsdata består af e-mails mærket som “spam” eller “ikke spam”. Hver e-mail er repræsenteret ved en række features, fx tilstedeværelsen af specifikke ord. Under træning beregner algoritmen sandsynligheden for hvert ord givet klasselabel. For en ny e-mail beregner algoritmen den posteriore sandsynlighed for “spam” og “ikke spam” og tildeler den label med højest sandsynlighed.
Naiv Bayes-klassifikatorer kan integreres i AI-systemer og chatbots for at forbedre deres naturlige sprogbehandlingskapaciteter. For eksempel kan de bruges til at detektere brugerhensigt, klassificere tekst i foruddefinerede kategorier eller filtrere upassende indhold. Denne funktionalitet forbedrer relevans og kvalitet i AI-drevne løsninger. Derudover gør algoritmens effektivitet den velegnet til realtidsapplikationer, hvilket er vigtigt for AI-automatisering og chatbotsystemer.
Naiv Bayes er en familie af enkle, men kraftfulde probabilistiske algoritmer, der anvender Bayes’ sætning med stærke uafhængighedsantagelser mellem features. Den bruges bredt til klassifikationsopgaver på grund af sin enkelhed og effektivitet. Her er nogle videnskabelige artikler, som belyser forskellige anvendelser og forbedringer af Naiv Bayes-klassifikatoren:
Forbedring af spamfiltrering ved at kombinere Naiv Bayes med simple k-nærmeste nabosøgninger
Forfatter: Daniel Etzold
Udgivet: 30. november 2003
Denne artikel undersøger brugen af Naiv Bayes til e-mail-klassifikation og fremhæver dens nemme implementering og effektivitet. Undersøgelsen præsenterer empiriske resultater, der viser, hvordan kombinationen af Naiv Bayes og k-nærmeste nabo-søgninger kan forbedre nøjagtigheden af spamfiltre. Kombinationen gav små forbedringer i nøjagtighed ved mange features og markante forbedringer ved færre features. Læs artiklen.
Lokalt vægtet Naiv Bayes
Forfattere: Eibe Frank, Mark Hall, Bernhard Pfahringer
Udgivet: 19. oktober 2012
Denne artikel adresserer Naiv Bayes’ primære svaghed, nemlig antagelsen om attribut-uafhængighed. Den introducerer en lokalt vægtet version af Naiv Bayes, som lærer lokale modeller ved forudsigelse og dermed slækker på uafhængighedsantagelsen. De eksperimentelle resultater viser, at denne tilgang sjældent forringer nøjagtigheden og ofte forbedrer den markant. Metoden roses for sin konceptuelle og beregningsmæssige enkelhed sammenlignet med andre teknikker. Læs artiklen.
Naiv Bayes fangstdetektion for planetariske rovere
Forfatter: Dicong Qiu
Udgivet: 31. januar 2018
I dette studie diskuteres brugen af Naiv Bayes-klassifikatorer til fangstdetektion i planetariske rovere. Artiklen definerer kriterierne for fangst og demonstrerer anvendelsen af Naiv Bayes til at detektere sådanne scenarier. Der redegøres for eksperimenter udført med AutoKrawler-rovere, hvilket giver indsigt i Naiv Bayes’ effektivitet til autonome redningsprocedurer. Læs artiklen.
Naiv Bayes er en familie af klassifikationsalgoritmer baseret på Bayes’ sætning, som antager, at alle features er betinget uafhængige givet klasselabel. Det bruges bredt til tekstklassifikation, spamfiltrering og sentimentanalyse.
De vigtigste typer er Gaussian Naiv Bayes (til kontinuerlige features), Multinomial Naiv Bayes (til diskrete features som ordoptællinger) og Bernoulli Naiv Bayes (til binære/boolean-features).
Naiv Bayes er let at implementere, beregningsmæssigt effektiv, kan skaleres til store datasæt og håndterer data med høj dimensionalitet godt.
Den primære begrænsning er antagelsen om feature-uafhængighed, som ofte ikke holder for data fra den virkelige verden. Modellen kan også tildele nul-sandsynlighed til uobserverede features, hvilket kan afhjælpes med teknikker som Laplace-glatning.
Naiv Bayes bruges i AI-systemer og chatbots til intenderingsdetektion, tekstklassifikation, spamfiltrering og sentimentanalyse for at forbedre naturlig sprogbehandling og muliggøre beslutningstagning i realtid.
Smarte chatbots og AI-værktøjer samlet ét sted. Forbind intuitive blokke og gør dine idéer til automatiserede flows.
Et Bayesisk Netværk (BN) er en probabilistisk grafisk model, der repræsenterer variable og deres betingede afhængigheder via en Rettet Acyklisk Graf (DAG). Baye...
En AI-klassifikator er en maskinlæringsalgoritme, der tildeler klasselabels til inputdata og kategoriserer information i foruddefinerede klasser baseret på møns...
Integrer FlowHunt med Naver MCP-serveren for at automatisere adgang til Navers OpenAPI for problemfri blog-, nyheds-, bog-, billede- og shoppingsøgning. Udnyt a...