SciPy
SciPy er et robust open source Python-bibliotek til videnskabelig og teknisk beregning. Ovenpå NumPy tilbyder det avancerede matematiske algoritmer, optimering,...
5 min læsning
SciPy
Python
+5
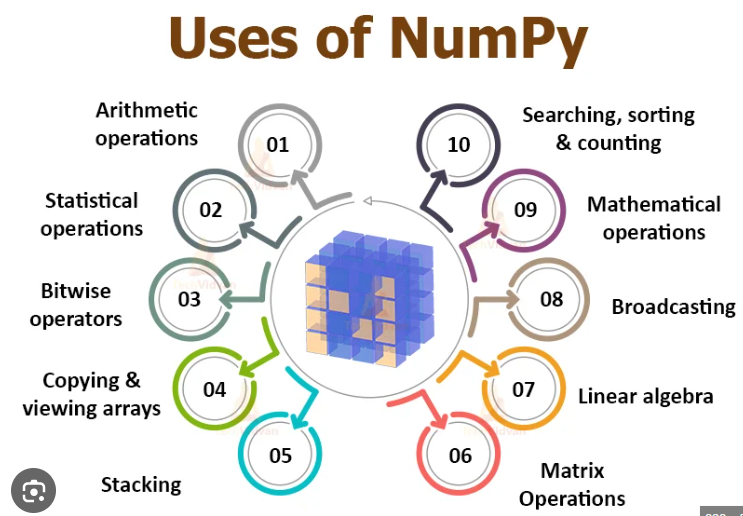
NumPy er et grundlæggende Python-bibliotek til numerisk databehandling, der tilbyder hurtige og effektive arrayoperationer, som er essentielle for videnskabelig databehandling, datavidenskab og machine learning.
NumPy er et open-source Python-bibliotek, der er afgørende for numerisk databehandling og tilbyder effektive arrayoperationer. Det er essentielt inden for videnskabelig databehandling, datavidenskab og machine learning, og giver værktøjer til lineær algebra, FFT’er og integration med andre biblioteker.
NumPy, forkortelse for Numerical Python, er et open-source Python-bibliotek, der specialiserer sig i numerisk databehandling. Det er en grundlæggende pakke til videnskabelig databehandling i Python og tilbyder understøttelse af arrays, matricer og en række matematiske funktioner til at arbejde med disse datastrukturer. NumPy udgør rygraden i mange workflows inden for datavidenskab og machine learning og tilbyder den beregningskraft, man kender fra sprog som C og Fortran, samtidig med at man bevarer Pythons enkelhed og brugervenlighed. Biblioteket er især værdsat for dets evne til at give forskere og udviklere mulighed for at udføre komplekse matematiske operationer på store datasæt effektivt, hvilket gør det til en hjørnesten inden for områder, der kræver omfattende dataanalyse og -manipulation.
Kernen i NumPy er objektet ndarray (N-dimensionelt array), som er en kraftfuld datastruktur til effektiv lagring og håndtering af homogene datatyper. I modsætning til Python-lister er NumPy-arrays optimeret til operationer på store datasæt, hvilket gør dem betydeligt hurtigere og mere effektive. ndarray understøtter en række operationer såsom elementvis aritmetik, statistiske beregninger og omformning af data – alt sammen med ensartet ydeevne på tværs af operationer.
NumPy udmærker sig i håndteringen af multidimensionelle arrays, som er essentielle for mange videnskabelige beregninger. Disse arrays kan repræsentere vektorer (1-D), matricer (2-D) eller tensorer (N-D), hvilket gør det muligt at manipulere komplekse datastrukturer med lethed. Evnen til effektivt at håndtere multidimensionelle arrays gør NumPy til det foretrukne valg til applikationer inden for machine learning og videnskabelig databehandling, hvor data ofte forekommer i flerdimensionelle strukturer.
En af NumPys nøglestyrker er evnen til at udføre vektoriserede operationer, dvs. operationer, der anvendes på hele arrays i stedet for individuelle elementer. Denne tilgang er ikke blot mere kortfattet, men også hurtigere på grund af de underliggende C-implementeringer. Vektorisering reducerer markant omkostningerne ved at udføre løkker i Python, hvilket fører til mere effektiv kode. Broadcasting udvider denne mulighed ved at gøre det muligt at udføre operationer på arrays med forskellige former, så de automatisk tilpasses en fælles form på en effektiv måde. Denne funktionalitet forenkler koden og reducerer behovet for komplekse løkkekonstruktioner.
NumPy indeholder adskillige funktioner til at udføre operationer såsom:
NumPy er fundamentet i det videnskabelige Python-økosystem og fungerer som base for biblioteker som Pandas, SciPy og Scikit-learn. Disse biblioteker er afhængige af NumPys array-strukturer til effektiv datamanipulation og analyse. For eksempel bruger Pandas NumPys arrays til sine DataFrame-objekter, mens SciPy bygger videre på NumPy for mere avancerede matematiske funktioner, og Scikit-learn anvender dem til effektive machine learning-algoritmer.
Selvom NumPy er optimeret til CPU-operationer, udvider biblioteker som CuPy og frameworks som PyTorch NumPys funktionalitet til GPU’er, så man kan udnytte parallel databehandling til hurtigere beregninger i machine learning og datavidenskab. Det gør det muligt for brugere at udnytte GPU’ers kraft til at accelerere beregningstunge opgaver uden at skulle lære et helt nyt bibliotek.
NumPy er uundværlig inden for områder som fysik, kemi og biologi, hvor det muliggør simuleringer, dataanalyse og modeludvikling. Forskere bruger NumPy til at håndtere store datasæt og udføre komplekse matematiske beregninger effektivt. Dets evne til at integrere med andre videnskabelige biblioteker gør det til et alsidigt værktøj til udvikling af omfattende beregningsmodeller.
Inden for datavidenskab bruges NumPy til datapreprocessering, feature extraction og modelevaluering. Dets arrayoperationer er afgørende for at håndtere store datasæt, hvilket gør det til et fast værktøj i machine learning-workflows. NumPys hurtige og effektive operationer gør det muligt for data scientists hurtigt at prototype og skalere deres løsninger.
NumPys rolle i AI og automatisering er betydelig, da det udgør den beregningsmæssige rygrad for deep learning-frameworks som TensorFlow og PyTorch. Disse frameworks bruger NumPy til tensor-manipulation og numeriske beregninger, hvilket er essentielt for træning og implementering af AI-modeller. Evnen til effektivt at håndtere store mængder data gør NumPy til en nøglekomponent i udviklingen af AI-drevne løsninger.
import numpy as np
# Oprettelse af et 1-D array
array_1d = np.array([1, 2, 3, 4, 5])
# Oprettelse af et 2-D array (matrix)
array_2d = np.array([[1, 2, 3], [4, 5, 6]])
# Adgang til elementer
element = array_1d[0] # Giver 1
# Omformning af arrays
reshaped_array = array_2d.reshape(3, 2)
# Aritmetiske operationer
result = array_1d * 2 # Giver array([2, 4, 6, 8, 10])
# Broadcasting af en skalarværdi over et 1-D array
array = np.array([1, 2, 3])
broadcasted_result = array + 5 # Giver array([6, 7, 8])
# Broadcasting med forskellige former
array_a = np.array([[1], [2], [3]])
array_b = np.array([4, 5, 6])
broadcasted_sum = array_a + array_b
# Giver array([[5, 6, 7],
# [6, 7, 8],
# [7, 8, 9]])
Forstå NumPy: Et centralt bibliotek til videnskabelig databehandling
NumPy er et grundlæggende bibliotek i programmeringssproget Python, der er meget anvendt til numeriske beregninger. Det tilbyder et kraftfuldt array-objekt og er en nøglekomponent for effektiv videnskabelig databehandling.
I artiklen “The NumPy array: a structure for efficient numerical computation” af Stefan Van Der Walt, S. Chris Colbert og Gaël Varoquaux forklarer forfatterne, hvordan NumPy-arrays er blevet standarden for numerisk datarepræsentation i Python. De gennemgår teknikker som vektorisering af beregninger, minimering af datakopiering og reduktion af antallet af operationer for at forbedre ydelsen. Artiklen går i dybden med strukturen af NumPy-arrays og illustrerer deres anvendelse i effektiv databehandling. Læs mere
Claas Abert og kolleger demonstrerer i deres arbejde “A full-fledged micromagnetic code in less than 70 lines of NumPy”, hvordan NumPy kan bruges til at udvikle en komplet mikromagnetisk finite-difference-kode. Denne kode beregner effektivt exchange- og demagnetiseringsfelter ved hjælp af NumPys array-strukturer og understreger dets nytte i algoritmeudvikling. Læs mere
Artiklen “A Toolbox for Fast Interval Arithmetic in numpy with an Application to Formal Verification of Neural Network Controlled Systems” af Akash Harapanahalli, Saber Jafarpour og Samuel Coogan introducerer et toolbox til intervalanalyse baseret på NumPy. Denne toolbox muliggør formel verifikation af systemer styret af neurale netværk ved effektivt at beregne naturlige inklusionsfunktioner inden for NumPys rammer. Læs mere
NumPy bruges til effektiv numerisk databehandling i Python og tilbyder understøttelse af arrays, matricer og en bred vifte af matematiske funktioner. Det er essentielt inden for videnskabelig databehandling, datavidenskab og machine learning.
NumPy-arrays (ndarray) er N-dimensionelle arrays optimeret til effektiv lagring og håndtering af homogene datatyper. De understøtter hurtige elementvise operationer og er langt mere effektive end Python-lister til numeriske opgaver.
NumPy fungerer som fundament for mange videnskabelige Python-biblioteker, såsom Pandas, SciPy og Scikit-learn, der bruger NumPy-arrays til effektiv datamanipulation og beregning.
NumPy er i sig selv optimeret til CPU-operationer, men dets funktionalitet kan udvides til GPU'er ved hjælp af biblioteker som CuPy eller frameworks som PyTorch for hurtigere paralleldatabehandling i datavidenskab og machine learning.
Ja! For eksempel kan du oprette et NumPy-array med np.array([1, 2, 3]) og gange det med 2 for at få array([2, 4, 6]), hvilket viser effektive elementvise operationer.
Udnyt NumPy til effektiv dataanalyse og videnskabelig databehandling. Prøv FlowHunt for at accelerere dine AI- og data-workflows.
SciPy er et robust open source Python-bibliotek til videnskabelig og teknisk beregning. Ovenpå NumPy tilbyder det avancerede matematiske algoritmer, optimering,...
Jupyter Notebook er en open source-webapplikation, der gør det muligt for brugere at oprette og dele dokumenter med levende kode, ligninger, visualiseringer og ...
spaCy er et robust open source Python-bibliotek til avanceret Natural Language Processing (NLP), kendt for sin hastighed, effektivitet og produktionsklare funkt...