Tekstklassificering
Tekstklassificering, også kendt som tekstkategorisering eller tekstmærkning, er en central NLP-opgave, der tildeler foruddefinerede kategorier til tekstdokument...
6 min læsning
NLP
Text Classification
+4
Ordklassemærkning tildeler grammatiske kategorier som navneord og udsagnsord til ord i tekst, hvilket gør det muligt for maskiner bedre at fortolke og behandle menneskesprog til NLP-opgaver.
Ordklassemærkning (POS tagging) er en central opgave inden for beregningslingvistik og naturlig sprogbehandling, der bygger bro mellem menneske-maskin-interaktion. Udforsk dens nøgleaspekter, funktioner og anvendelser i dag! Det indebærer at tildele hvert ord i en tekst dets tilsvarende ordklasse baseret på dets betydning og kontekst i en sætning. Hovedformålet er at kategorisere ord i grammatiske kategorier såsom navneord, udsagnsord, tillægsord, biord osv., hvilket gør det muligt for maskiner at behandle og forstå menneskesprog mere effektivt. Denne opgave kaldes også grammatisk mærkning eller ordklasse-afklaring og danner rygraden i forskellige avancerede sproganalyser.
Før man dykker dybere ned i POS-mærkning, er det vigtigt at forstå nogle grundlæggende ordklasser på engelsk:
POS-mærkning er afgørende for at gøre det muligt for maskiner at fortolke og interagere med menneskesprog præcist. Det danner fundamentet for forskellige NLP-applikationer, herunder:
Overvej sætningen:
“The quick brown fox jumps over the lazy dog.”
Efter POS-mærkning bliver hvert ord mærket således:
Denne mærkning giver indsigt i sætningens grammatiske struktur og understøtter yderligere NLP-opgaver ved at afsløre relationerne mellem ordene.
Der findes flere tilgange til ordklassemærkning, hver med sine fordele og udfordringer:
Regelbaseret mærkning:
Statistisk mærkning:
Transformationsbaseret mærkning:
Maskinlæringsbaseret mærkning:
Hybride tilgange:
POS-mærkning spiller en vigtig rolle i udviklingen af AI-systemer, der interagerer med menneskesprog, såsom chatbots og virtuelle assistenter. Ved at forstå den grammatiske struktur i brugerinput kan AI-systemer give mere præcise svar og dermed forbedre brugerinteraktionen. I AI-automatisering hjælper POS-mærkning med opgaver som dokumentklassifikation, sentimentanalyse og indholdsmoderering ved at give syntaktisk og semantisk indsigt i teksten.
Ordklassemærkning (POS tagging) er en grundlæggende proces i naturlig sprogbehandling (NLP), hvor hvert ord i en tekst mærkes med sin tilsvarende ordklasse, såsom navneord, udsagnsord, tillægsord osv. Denne proces hjælper med at forstå sætnings syntaktiske struktur, hvilket er afgørende for forskellige NLP-applikationer som tekstanalyse, sentimentanalyse og maskinoversættelse.
Vigtige forskningsartikler:
Metode til tilpasselig automatisk mærkning
Denne artikel af Maharshi R. Pandya og kolleger adresserer udfordringerne med overmærkning og undermærkning i tekstdokumenter. Forfatterne foreslår en mærkningsmetode ved brug af IBM Watson’s NLU-service til at generere et universelt sæt tags, der kan anvendes på store dokumentkorpora. De demonstrerer metodens effektivitet ved at anvende den på 87.397 dokumenter og opnår høj mærkningsnøjagtighed. Denne forskning understreger vigtigheden af effektive mærkningssystemer til håndtering af store tekstmængder.
Læs mere
En fælles navngiven entitetsgenkender for heterogene tag-sæt ved brug af en tag-hierarki
Genady Beryozkin og hans team undersøger domænetilpasning i navngiven entitetsgenkendelse med flere heterogent taggede træningssæt. De foreslår at udnytte en tag-hierarki til at lære et neuralt netværk, der kan rumme forskellige tag-sæt. Deres eksperimenter viser forbedret ydeevne ved konsolidering af tag-sæt og fremhæver fordelene ved en hierarkisk mærkningstilgang.
Læs mere
Who Ordered This?: Udnyttelse af implicitte brugerpræferencer for tag-rækkefølge til personlig billedmærkning
Amandianeze O. Nwana og Tsuhan Chen undersøger betydningen af tag-rækkefølgepræferencer i billedmærkning. De foreslår en ny objektiv funktion, der tager højde for brugernes foretrukne tag-rækkefølger for at forbedre automatiserede billedmærkningssystemer. Deres metode viser forbedret ydeevne på personlige mærkningsopgaver og understreger brugeradfærdens betydning for mærkningssystemer.
Læs mere
Ordklassemærkning (POS tagging) er processen, hvor hvert ord i en tekst tildeles dets grammatiske kategori, såsom navneord, udsagnsord, tillægsord eller biord, baseret på dets betydning og kontekst. Det er grundlæggende for NLP-opgaver som maskinoversættelse og navngiven entitetsgenkendelse.
POS-mærkning gør det muligt for maskiner præcist at fortolke og behandle menneskesprog. Det danner grundlaget for applikationer som maskinoversættelse, informationsudtrækning, tekst-til-tale-konvertering og chatbot-interaktioner ved at tydeliggøre sætningers grammatiske struktur.
De primære tilgange omfatter regelbaseret mærkning, statistisk mærkning ved hjælp af sandsynlighedsmodeller, transformationsbaseret mærkning, maskinlæringsbaserede metoder og hybride systemer, der kombinerer disse teknikker for højere nøjagtighed.
Udfordringer omfatter håndtering af tvetydige ord, der kan tilhøre flere kategorier, idiomatiske udtryk, ord uden for ordforrådet samt tilpasning af modeller til forskellige domæner eller teksttyper.
Begynd at bygge smartere AI-løsninger ved hjælp af avancerede NLP-teknikker som ordklassemærkning. Automatiser sprogforståelse med FlowHunt.
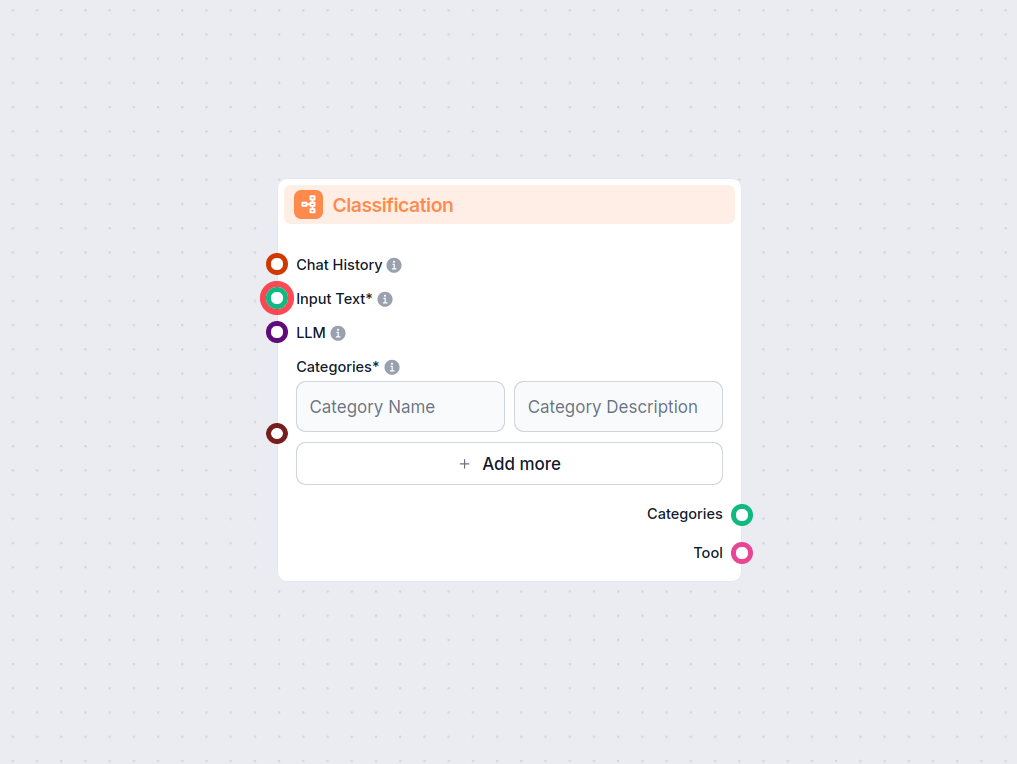
Tekstklassificering, også kendt som tekstkategorisering eller tekstmærkning, er en central NLP-opgave, der tildeler foruddefinerede kategorier til tekstdokument...
Lås op for automatiseret tekstkategorisering i dine workflows med Text Classification-komponenten til FlowHunt. Klassificér nemt indgående tekst i brugerdefiner...
Et token i forbindelse med store sprogmodeller (LLM'er) er en sekvens af tegn, som modellen omdanner til numeriske repræsentationer for effektiv behandling. Tok...