
Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation (RAG) er en avanceret AI-ramme, der kombinerer traditionelle informationshentningssystemer med generative store sprogmodeller (LL...
4 min læsning
RAG
AI
+4

Spørgsmål og Svar med RAG forbedrer LLM’er ved at integrere realtime datahentning og generering af naturligt sprog for præcise, kontekstuelt relevante svar.
Spørgsmål og Svar med Retrieval-Augmented Generation (RAG) forbedrer sprogmodeller ved at integrere realtime eksterne data for præcise og relevante svar. Det optimerer ydeevnen i dynamiske felter og tilbyder forbedret nøjagtighed, dynamisk indhold og øget relevans.
Spørgsmål og Svar med Retrieval-Augmented Generation (RAG) er en innovativ metode, der kombinerer styrkerne fra informationssøgning og generering af naturligt sprog, hvilket skaber menneskelignende tekst ud fra data og forbedrer AI, chatbots, rapporter samt personaliserer oplevelser. Denne hybride tilgang udvider kapaciteten for store sprogmodeller (LLM’er) ved at supplere deres svar med relevante, opdaterede informationer hentet fra eksterne datakilder. I modsætning til traditionelle metoder, der udelukkende er baseret på fortrænede modeller, integrerer RAG dynamisk eksterne data, så systemer kan levere mere præcise og kontekstuelt relevante svar – især i områder, hvor den nyeste information eller specialviden er påkrævet.
RAG optimerer ydeevnen for LLM’er ved at sikre, at svar ikke kun genereres ud fra et internt datasæt, men også informeres af realtime, autoritative kilder. Denne tilgang er afgørende for spørgsmål-og-svar-opgaver i dynamiske områder, hvor information konstant udvikler sig.
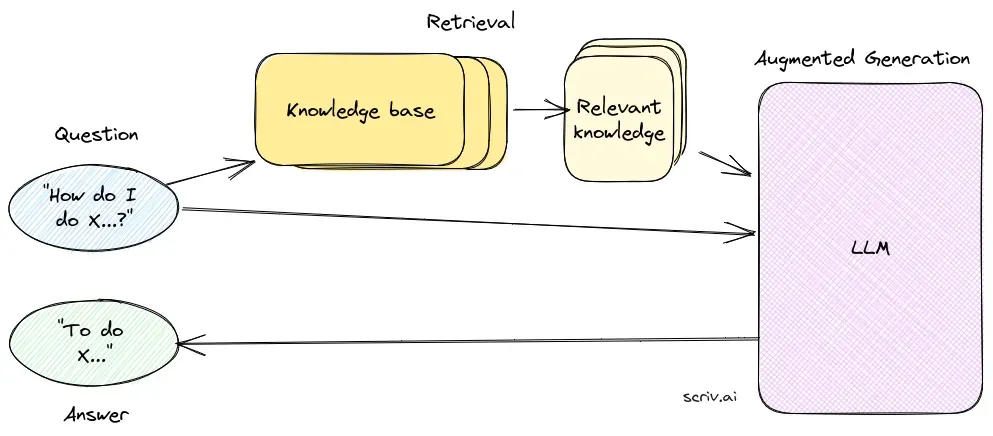
Retrieval-komponenten er ansvarlig for at hente relevant information fra store datasæt, typisk gemt i en vektordatabase. Denne komponent benytter semantiske søgeteknikker til at identificere og udtrække tekstsegmenter eller dokumenter, der er højest relevante for brugerens forespørgsel.
Genereringskomponenten, som oftest er en LLM såsom GPT-3 eller BERT, syntetiserer et svar ved at kombinere brugerens oprindelige forespørgsel med den hentede kontekst. Denne komponent er afgørende for at generere sammenhængende og kontekstuelt passende svar.
Implementering af et RAG-system involverer flere tekniske trin:
Forskning i Spørgsmål og Svar med Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) er en metode, der udvider spørgsmål-og-svar-systemer ved at kombinere retrieval-mekanismer med generative modeller. Nyere forskning har undersøgt effektiviteten og optimeringen af RAG i forskellige sammenhænge.
RAG er en metode, der kombinerer informationssøgning og generering af naturligt sprog for at levere præcise, opdaterede svar ved at integrere eksterne datakilder i store sprogmodeller.
Et RAG-system består af en retrieval-komponent, som henter relevant information fra vektordatabaser ved hjælp af semantisk søgning, og en genereringskomponent, typisk en LLM, der syntetiserer svar ved at bruge både brugerens forespørgsel og den hentede kontekst.
RAG forbedrer nøjagtigheden ved at hente kontekstuelt relevant information, understøtter dynamisk opdatering af indhold fra eksterne vidensbaser og øger relevansen og kvaliteten af genererede svar.
Almindelige anvendelser omfatter AI-chatbots, kundesupport, automatiseret indholdsskabelse og uddannelsesværktøjer, der kræver præcise, kontekstbevidste og opdaterede svar.
RAG-systemer kan være ressourcekrævende, kræver omhyggelig integration for optimal ydeevne og skal sikre faktuel nøjagtighed i den hentede information for at undgå vildledende eller forældede svar.
Opdag hvordan Retrieval-Augmented Generation kan styrke din chatbot og supportløsninger med realtime, præcise svar.
Retrieval Augmented Generation (RAG) er en avanceret AI-ramme, der kombinerer traditionelle informationshentningssystemer med generative store sprogmodeller (LL...
Opdag de vigtigste forskelle mellem Retrieval-Augmented Generation (RAG) og Cache-Augmented Generation (CAG) i AI. Lær, hvordan RAG dynamisk henter realtidsinfo...
Cache Augmented Generation (CAG) er en ny tilgang til at forbedre store sprogmodeller (LLM'er) ved at forudindlæse viden som forudberegnede key-value-cacher, hv...

