Real-tids domænespecifik RAG Chatbot
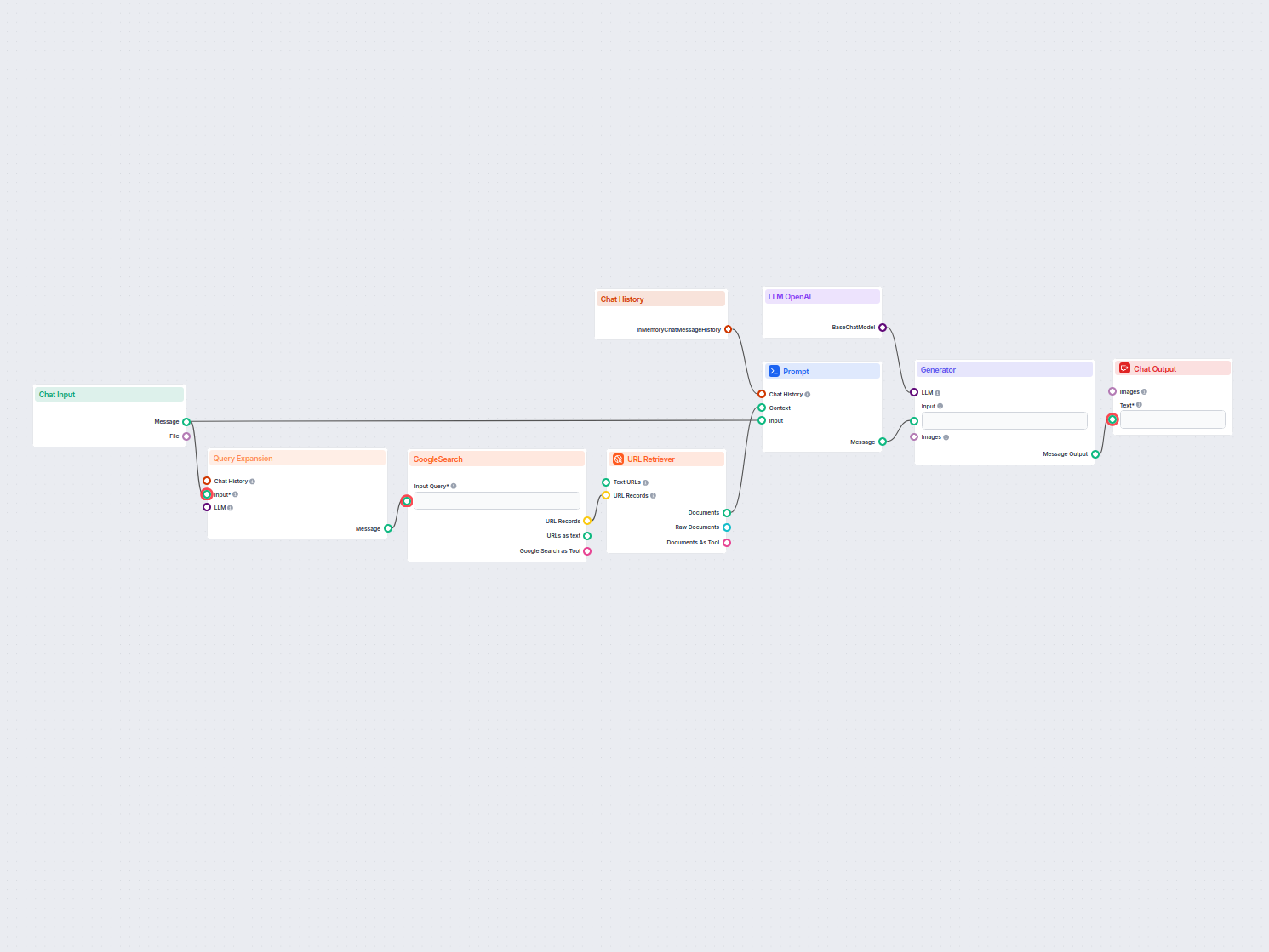
En realtidschatbot, der bruger Google Søgning begrænset til dit eget domæne, henter relevant webindhold og udnytter OpenAI LLM til at besvare brugerforespørgsle...
4 min læsning
En retrieval pipeline gør det muligt for chatbots at hente og behandle relevant ekstern viden for præcise, realtidsbaserede og kontekstbevidste svar ved hjælp af RAG, embeddings og vektordatabaser.
En retrieval pipeline for chatbots refererer til den tekniske arkitektur og proces, der gør det muligt for chatbots at hente, behandle og finde relevant information som svar på brugerforespørgsler. I modsætning til simple spørgsmål-svar-systemer, der kun er baseret på fortrænede sprogmodeller, inkorporerer retrieval pipelines eksterne vidensbaser eller datakilder. Dette gør det muligt for chatbotten at give præcise, kontekstuelt relevante og opdaterede svar, selv når dataene ikke er en del af sprogmodellen selv.
Retrieval pipeline består typisk af flere komponenter, herunder dataindsamling, embedding-oprettelse, vektorlager, kontekst-hentning og svargenerering. Implementeringen involverer ofte Retrieval-Augmented Generation (RAG), som kombinerer styrkerne fra datahentningssystemer og store sprogmodeller (LLMs) til svargenerering.
En retrieval pipeline bruges til at forbedre en chatbots evner ved at gøre det muligt at:
Dokumentindsamling
Indsamling og forbehandling af rådata, som kan inkludere PDF’er, tekstfiler, databaser eller API’er. Værktøjer som LangChain eller LlamaIndex benyttes ofte til problemfri dataindsamling.
Eksempel: Indlæsning af kundeservice-FAQ eller produktspecifikationer i systemet.
Dokumentforbehandling
Lange dokumenter opdeles i mindre, semantisk meningsfulde dele. Dette er nødvendigt for at passe teksten ind i embedding-modeller, der typisk har token-begrænsninger (fx 512 tokens).
Eksempel på kode:
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = text_splitter.split_documents(document_list)
Embedding-generering
Tekstdata konverteres til højdimensionelle vektor-repræsentationer ved hjælp af embedding-modeller. Disse embeddings koder semantikken i dataene numerisk.
Eksempel på embedding-model: OpenAI’s text-embedding-ada-002 eller Hugging Face’s e5-large-v2.
Vektorlager
Embeddings gemmes i vektordatabaser optimeret til lighedssøgninger. Værktøjer som Milvus, Chroma eller PGVector bruges ofte.
Eksempel: Opbevaring af produktbeskrivelser og deres embeddings for effektiv hentning.
Forespørgselsbehandling
Når en brugerforespørgsel modtages, omdannes den til en forespørgselsvektor ved hjælp af samme embedding-model. Dette muliggør semantisk lighedsmatching med gemte embeddings.
Eksempel på kode:
query_vector = embedding_model.encode("What are the specifications of Product X?")
retrieved_docs = vector_db.similarity_search(query_vector, k=5)
Datahentning
Systemet henter de mest relevante datastykker baseret på lighedsscorer (fx cosinus-lighed). Multimodale hentningssystemer kan kombinere SQL-databaser, vidensgrafer og vektorsøgning for mere robuste resultater.
Svargenerering
De hentede data kombineres med brugerens forespørgsel og gives videre til en stor sprogmodel (LLM) for at generere et endeligt, naturligt sprog-svar. Dette trin kaldes ofte augmented generation.
Eksempel på prompt-skabelon:
prompt_template = """
Context: {context}
Question: {question}
Please provide a detailed response using the context above.
"""
Efterbehandling og validering
Avancerede retrieval pipelines inkluderer hallucinationsdetektion, relevanstjek eller svarvurdering for at sikre, at output er faktuelt og relevant.
Kundesupport
Chatbots kan hente produktmanualer, fejlfinding-guides eller FAQ’er for at give hurtige svar på kundespørgsmål.
Eksempel: En chatbot, der hjælper en kunde med at nulstille en router ved at hente det relevante afsnit i brugervejledningen.
Virksomhedens vidensstyring
Interne virksomhedschatbots kan få adgang til virksomhedsdata som HR-politikker, IT-supportdokumentation eller compliance-retningslinjer.
Eksempel: Medarbejdere spørger en intern chatbot om sygefraværspolitik.
E-handel
Chatbots hjælper brugere ved at hente produktoplysninger, anmeldelser eller lagerstatus.
Eksempel: “Hvilke topfunktioner har Produkt Y?”
Sundhedssektoren
Chatbots henter medicinsk litteratur, retningslinjer eller patientdata for at hjælpe sundhedsprofessionelle eller patienter.
Eksempel: En chatbot, der henter advarsler om lægemiddelinteraktioner fra en lægemiddeldatabase.
Uddannelse og forskning
Akademiske chatbots bruger RAG-pipelines til at hente videnskabelige artikler, besvare spørgsmål eller opsummere forskningsresultater.
Eksempel: “Kan du opsummere resultaterne af dette 2023-studie om klimaforandringer?”
Jura og compliance
Chatbots henter juridiske dokumenter, domme eller compliance-krav for at hjælpe jurister.
Eksempel: “Hvad er den seneste opdatering om GDPR-regler?”
En chatbot bygget til at besvare spørgsmål fra en virksomheds årsregnskab i PDF-format.
En chatbot, der kombinerer SQL, vektorsøgning og vidensgrafer for at besvare en medarbejders spørgsmål.
Ved at udnytte retrieval pipelines er chatbots ikke længere begrænset af statiske træningsdata, hvilket gør dem i stand til at levere dynamiske, præcise og kontekstrige interaktioner.
Retrieval pipelines spiller en central rolle i moderne chatbotsystemer og muliggør intelligente og kontekstbevidste interaktioner.
“Lingke: A Fine-grained Multi-turn Chatbot for Customer Service” af Pengfei Zhu m.fl. (2018)
Introducerer Lingke, en chatbot der integrerer informationshentning til håndtering af samtaler over flere omgange. Den benytter finmasket pipeline-behandling for at udlede svar fra ustrukturerede dokumenter og anvender opmærksom kontekst-svar-matchning for sekventielle interaktioner, hvilket betydeligt forbedrer chatbot’ens evne til at håndtere komplekse brugerforespørgsler.
Læs artiklen her.
“FACTS About Building Retrieval Augmented Generation-based Chatbots” af Rama Akkiraju m.fl. (2024)
Udforsker udfordringerne og metoderne ved udvikling af enterprise-grade chatbots ved brug af Retrieval Augmented Generation (RAG) pipelines og store sprogmodeller (LLMs). Forfatterne foreslår FACTS-rammeværket med fokus på Freshness, Architectures, Cost, Testing og Security i RAG pipeline engineering. Deres empiriske fund peger på afvejninger mellem nøjagtighed og latenstid ved opskalering af LLMs og giver værdifuld indsigt i opbygning af sikre og højtydende chatbots. Læs artiklen her.
“From Questions to Insightful Answers: Building an Informed Chatbot for University Resources” af Subash Neupane m.fl. (2024)
Præsenterer BARKPLUG V.2, et chatbotsystem designet til universitetsmiljøer. Ved anvendelse af RAG-pipelines leverer systemet præcise og domænespecifikke svar om campus-ressourcer og forbedrer informationsadgangen. Undersøgelsen evaluerer chatbot’ens effektivitet med rammer som RAG Assessment (RAGAS) og viser dens anvendelighed i akademiske miljøer. Læs artiklen her.
En retrieval pipeline er en teknisk arkitektur, der gør det muligt for chatbots at hente, behandle og finde relevant information fra eksterne kilder som svar på brugerforespørgsler. Den kombinerer dataindsamling, embedding, vektorlager og LLM-svargenerering for dynamiske, kontekstbevidste svar.
RAG kombinerer styrkerne fra datahentningssystemer og store sprogmodeller (LLMs), hvilket gør det muligt for chatbots at forankre svar i faktuelle, opdaterede eksterne data og dermed reducere hallucinationer og øge nøjagtigheden.
Nøglekomponenter omfatter dokumentindsamling, forbehandling, embedding-generering, vektorlager, forespørgselsbehandling, datahentning, svargenerering og efterbehandlingsvalidering.
Anvendelsestilfælde omfatter kundesupport, virksomhedens vidensstyring, e-handelsproduktoplysninger, sundhedsvejledning, uddannelse og forskning samt assistance til juridisk overholdelse.
Udfordringer omfatter latenstid fra realtids-hentning, driftsomkostninger, bekymringer om dataprivatliv og skalerbarhedskrav til håndtering af store datamængder.
Lås op for styrken ved Retrieval-Augmented Generation (RAG) og integration af eksterne data for at levere intelligente, præcise chatbot-svar. Prøv FlowHunt’s no-code platform i dag.
En realtidschatbot, der bruger Google Søgning begrænset til dit eget domæne, henter relevant webindhold og udnytter OpenAI LLM til at besvare brugerforespørgsle...
Spørgsmål og Svar med Retrieval-Augmented Generation (RAG) kombinerer informationssøgning og generering af naturligt sprog for at forbedre store sprogmodeller (...
Videnskabskilder gør det nemt at tilpasse AI’en efter dine behov. Oplev alle måderne at forbinde viden med FlowHunt. Forbind nemt hjemmesider, dokumenter og vid...