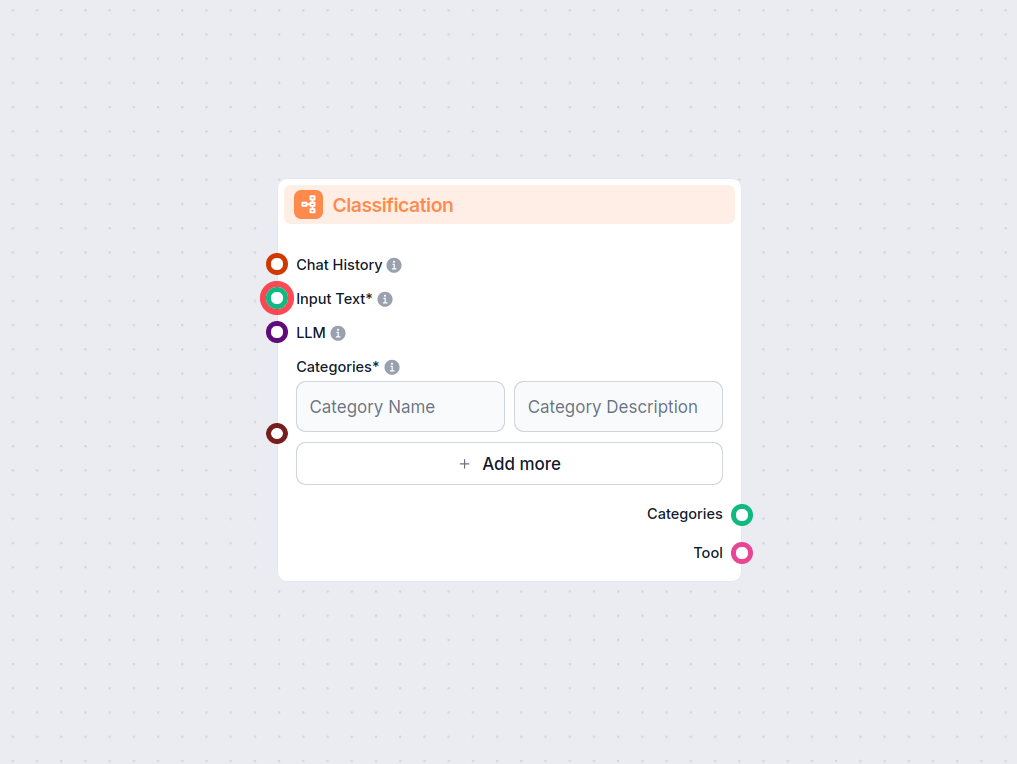
Automatisk klassificering
Automatisk klassificering automatiserer kategorisering af indhold ved at analysere egenskaber og tildele tags ved hjælp af teknologier som maskinlæring, NLP og ...
7 min læsning
AI
Auto-classification
+5
Tekstklassificering bruger NLP og maskinlæring til automatisk at tildele kategorier til tekst og driver applikationer som sentimentanalyse, spamdetektion og dataorganisering.
Tekstklassificering, også kendt som tekstkategorisering eller tekstmærkning, er en essentiel Natural Language Processing (NLP)-opgave, der indebærer tildeling af foruddefinerede kategorier til tekstdokumenter. Denne metode organiserer, strukturerer og kategoriserer ustrukturerede tekstdata, hvilket letter analyse og fortolkning. Tekstklassificering anvendes i forskellige applikationer, herunder sentimentanalyse, spamdetektion og emnekategorisering.
Ifølge AWS fungerer tekstklassificering som det første skridt i at organisere, strukturere og kategorisere data til videre analyse. Det muliggør automatisk mærkning og tagging af dokumenter, hvilket gør virksomheder i stand til effektivt at håndtere og analysere store mængder tekstdata. Denne evne til at automatisere mærkning af dokumenter reducerer manuel indsats og forbedrer datadrevne beslutningsprocesser.
Tekstklassificering drives af maskinlæring, hvor AI-modeller trænes på mærkede datasæt for at lære mønstre og sammenhænge mellem tekstlige features og deres respektive kategorier. Når modellerne er trænet, kan de klassificere nye og usete tekstdokumenter med høj nøjagtighed og effektivitet. Som bemærket af Towards Data Science, forenkler denne proces organiseringen af indhold, hvilket gør det lettere for brugere at søge og navigere på websites eller i applikationer.
Tekstklassificeringsmodeller er algoritmer, der automatiserer kategoriseringen af tekstdata. Disse modeller lærer fra eksempler i et træningsdatasæt og anvender deres viden til at klassificere nye tekstinputs. Populære modeller omfatter:
Support Vector Machines (SVM): En supervised learning-algoritme, der er effektiv til både binære og multiclass-klassificeringsopgaver. SVM identificerer det hyperplan, der bedst adskiller datapunkter fra forskellige kategorier. Denne metode egner sig godt til applikationer, hvor beslutningsgrænsen skal være klart defineret.
Naive Bayes: En probabilistisk klassifikator, der anvender Bayes’ sætning under antagelse af uafhængighed mellem features. Den er særligt effektiv til store datasæt på grund af sin enkelhed og effektivitet. Naive Bayes bruges ofte til spamdetektion og tekstanalyse, hvor hurtig beregning er påkrævet.
Dybe læringsmodeller: Disse inkluderer Convolutional Neural Networks (CNN’er) og Recurrent Neural Networks (RNN’er), som kan opfange komplekse mønstre i tekstdata ved at udnytte flere lag af behandling. Dybe læringsmodeller er fordelagtige til håndtering af store tekstklassificeringsopgaver og kan opnå høj nøjagtighed i sentimentanalyse og sprogmodellering.
Beslutningstræer og Random Forests: Træbaserede metoder, der klassificerer tekst ved at lære beslutningsregler udledt af datafeatures. Disse modeller er fordelagtige på grund af deres fortolkningsevne og kan bruges i forskellige applikationer som kategorisering af kundefeedback og dokumentklassificering.
Processen for tekstklassificering involverer flere trin:
Dataindsamling og forberedelse: Tekstdata indsamles og forbehandles. Dette trin kan omfatte tokenisering, stemming og fjernelse af stopord for at rense dataene. Ifølge Levity AI er tekstdata en værdifuld ressource til at forstå forbrugeradfærd, og korrekt forbehandling er afgørende for at udtrække handlingsorienteret indsigt.
Featureudtrækning: Transformationen af tekst til numeriske repræsentationer, som maskinlæringsalgoritmer kan behandle. Teknikker omfatter:
Modeltræning: Maskinlæringsmodellen trænes med det mærkede datasæt. Modellen lærer at forbinde features med deres tilsvarende kategorier.
Modelevaluering: Modellens præstation vurderes ved hjælp af metrikker som nøjagtighed, præcision, recall og F1-score. Krydsvalidering anvendes ofte for at sikre generalisering på usete data. AWS understreger vigtigheden af at evaluere præstationen af tekstklassificering for at sikre, at modellen lever op til ønsket nøjagtighed og pålidelighed.
Forudsigelse og implementering: Når modellen er valideret, kan den implementeres til at klassificere nye tekstdata.
Tekstklassificering anvendes bredt på tværs af forskellige domæner:
Sentimentanalyse: Detektering af det sentiment, der udtrykkes i tekst, ofte brugt til kunde-feedback og analyse af sociale medier for at måle offentlig mening. Levity AI fremhæver tekstklassificeringens rolle i social listening, der hjælper virksomheder med at forstå kundesentiment bag kommentarer og feedback.
Spamdetektion: Filtrering af uønskede og potentielt skadelige e-mails ved at klassificere dem som spam eller legitime. Automatiseret filtrering og mærkning, som det kendes fra Gmail, er klassiske eksempler på spamdetektion ved hjælp af tekstklassificering.
Emnekategorisering: Organisering af indhold i foruddefinerede emner, nyttigt for nyhedsartikler, blogs og forskningsartikler. Denne applikation forenkler indholdsstyring og -hentning og forbedrer brugeroplevelsen.
Kundesupport-ticketkategorisering: Automatisk routing af supporttickets til den relevante afdeling baseret på deres indhold. Denne automatisering øger effektiviteten i håndteringen af kundehenvendelser og reducerer arbejdsbyrden for supportteams.
Sprogdetektion: Identifikation af sproget i et tekstdokument til flersprogede applikationer. Denne funktionalitet er essentiel for globale virksomheder, der opererer på tværs af forskellige sprog og regioner.
Tekstklassificering indebærer flere udfordringer:
Datakvalitet og -mængde: Præstationen af tekstklassificeringsmodeller afhænger i høj grad af kvaliteten og mængden af træningsdata. Utilstrækkelige eller støjende data kan føre til dårlig modelpræstation. AWS bemærker, at organisationer skal sikre høj kvalitet i dataindsamling og mærkning for at opnå nøjagtige klassificeringsresultater.
Featureudvælgelse: Valg af de rette features er afgørende for modellens nøjagtighed. Overfitting kan forekomme, hvis modellen trænes på irrelevante features.
Model-fortolkningsevne: Dybe læringsmodeller er kraftfulde, men optræder ofte som black boxes, hvilket gør det svært at forstå, hvordan beslutninger træffes. Denne manglende gennemsigtighed kan være en barriere for anvendelse i brancher, hvor fortolkningsevne er kritisk.
Skalerbarhed: Efterhånden som datamængden vokser, skal modellerne kunne skaleres effektivt for at håndtere store datasæt. Effektive behandlingsteknikker og skalerbar infrastruktur er nødvendige for at håndtere den stigende datamængde.
Tekstklassificering er integreret i AI-drevet automatisering og chatbots. Ved automatisk at kategorisere og fortolke tekstinput kan chatbots give relevante svar, forbedre kundeinteraktioner og strømline forretningsprocesser. I AI-automatisering muliggør tekstklassificering, at systemer kan behandle og analysere store datamængder med minimal menneskelig indgriben, hvilket forbedrer effektivitet og beslutningsgrundlag.
Desuden har fremskridt inden for NLP og dyb læring udstyret chatbots med sofistikerede tekstklassificeringsmuligheder, så de kan forstå kontekst, sentiment og intention og dermed levere mere personlige og præcise interaktioner med brugerne. AWS foreslår, at integration af tekstklassificering i AI-applikationer markant kan forbedre brugeroplevelsen ved at give rettidig og relevant information.
Forskning i tekstklassificering
Tekstklassificering er en kritisk opgave inden for naturlig sprogbehandling, der indebærer automatisk kategorisering af tekst i foruddefinerede labels. Nedenfor er resuméer af nyere videnskabelige artikler, der giver indsigt i forskellige metoder og udfordringer forbundet med tekstklassificering:
Model and Evaluation: Towards Fairness in Multilingual Text Classification
Forfattere: Nankai Lin, Junheng He, Zhenghang Tang, Dong Zhou, Aimin Yang
Udgivet: 2023-03-28
Denne artikel adresserer udfordringen med bias i flersprogede tekstklassificeringsmodeller. Den foreslår en debiasing-ramme ved hjælp af contrastive learning, der ikke er afhængig af eksterne sprogressourcer. Rammen inkluderer moduler for flersproget tekstrepræsentation, sprogfusion, tekstdebiasing og klassificering. Der introduceres også en ny fler-dimensionel fairness-evalueringsramme, der har til formål at øge fairness på tværs af sprog. Dette arbejde er vigtigt for at forbedre fairness og nøjagtighed i flersprogede tekstklassificeringsmodeller. Læs mere
Text Classification using Association Rule with a Hybrid Concept of Naive Bayes Classifier and Genetic Algorithm
Forfattere: S. M. Kamruzzaman, Farhana Haider, Ahmed Ryadh Hasan
Udgivet: 2010-09-25
Denne forskning præsenterer en innovativ tilgang til tekstklassificering ved at anvende associationsregler kombineret med Naive Bayes og genetiske algoritmer. Metoden udleder features fra præ-klassificerede dokumenter ved hjælp af ordrelationer frem for individuelle ord. Integrationen af genetiske algoritmer forbedrer den endelige klassificeringspræstation. Resultaterne demonstrerer effektiviteten af denne hybride tilgang til vellykket tekstklassificering. Læs mere
Text Classification: A Perspective of Deep Learning Methods
Forfatter: Zhongwei Wan
Udgivet: 2023-09-24
Med den eksponentielle vækst i internetdata fremhæver denne artikel vigtigheden af dybe læringsmetoder i tekstklassificering. Den diskuterer forskellige dybe læringsteknikker, der forbedrer nøjagtighed og effektivitet i kategorisering af komplekse tekster. Studiet understreger den udviklende rolle for dyb læring i håndtering af store datasæt og levering af præcise klassificeringsresultater. Læs mere
Tekstklassificering er en Natural Language Processing (NLP)-opgave, hvor foruddefinerede kategorier tildeles tekstdokumenter, hvilket muliggør automatiseret organisering, analyse og fortolkning af ustrukturerede data.
Almindelige modeller omfatter Support Vector Machines (SVM), Naive Bayes, dybe læringsmodeller som CNN'er og RNN'er samt træbaserede metoder såsom beslutningstræer og Random Forests.
Tekstklassificering bruges bredt til sentimentanalyse, spamdetektion, emnekategorisering, routing af kundesupporttickets og sprogdetektion.
Udfordringer omfatter sikring af datakvalitet og -mængde, korrekt featureudvælgelse, model-fortolkningsevne og skalerbarhed til at håndtere store datamængder.
Tekstklassificering muliggør, at AI-drevet automatisering og chatbots effektivt kan fortolke, kategorisere og reagere på brugerinput, hvilket forbedrer kundeinteraktioner og forretningsprocesser.
Begynd at bygge smarte chatbots og AI-værktøjer, der udnytter automatiseret tekstklassificering til at øge effektivitet og indsigt.
Automatisk klassificering automatiserer kategorisering af indhold ved at analysere egenskaber og tildele tags ved hjælp af teknologier som maskinlæring, NLP og ...
Lås op for automatiseret tekstkategorisering i dine workflows med Text Classification-komponenten til FlowHunt. Klassificér nemt indgående tekst i brugerdefiner...
Opdag den afgørende rolle, AI Intentklassificering spiller i at forbedre brugerinteraktioner med teknologi, optimere kundesupport og strømline forretningsproces...