Transformer
En transformer-model er en type neuralt netværk, der er specifikt designet til at håndtere sekventielle data, såsom tekst, tale eller tidsseriedata. I modsætnin...
3 min læsning
Transformer
Neural Networks
+3
Transformere er banebrydende neurale netværk, der udnytter self-attention til parallel databehandling og driver modeller som BERT og GPT inden for NLP, vision og meget mere.
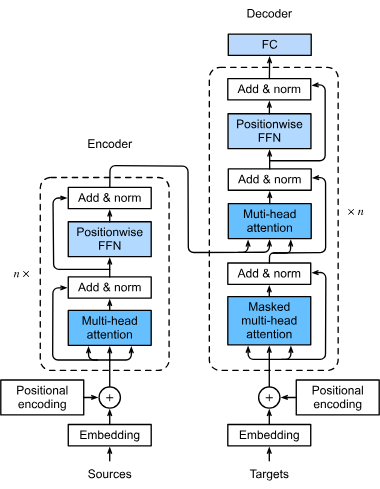
Det første trin i en transformer models behandlingspipeline involverer konvertering af ord eller tokens i en inputsekvens til numeriske vektorer, kaldet embeddings. Disse embeddings indeholder semantiske betydninger og er afgørende for, at modellen kan forstå relationerne mellem tokens. Denne transformation er essentiel, da den gør det muligt for modellen at behandle tekstdata i matematisk form.
Transformere behandler ikke data sekventielt af natur; derfor bruges positionel kodning til at tilføje information om placeringen af hver token i sekvensen. Dette er vigtigt for at opretholde rækkefølgen i sekvensen, hvilket er afgørende for opgaver som sprogoversættelse, hvor konteksten kan afhænge af ordenes rækkefølge.
Multi-head attention-mekanismen er en sofistikeret komponent i transformere, der gør det muligt for modellen at fokusere på forskellige dele af inputsekvensen samtidig. Ved at beregne flere attention-scorer kan modellen indfange forskellige relationer og afhængigheder i dataene, hvilket forbedrer dens evne til at forstå og generere komplekse dataprofiler.
Transformere følger typisk en encoder-decoder arkitektur:
Efter attention-mekanismen passerer dataene gennem feedforward neurale netværk, som anvender ikke-lineære transformationer på dataene og hjælper modellen med at lære komplekse mønstre. Disse netværk forfiner yderligere de output, modellen genererer.
Disse teknikker integreres for at stabilisere og fremskynde træningsprocessen. Lag-normalisering sikrer, at output forbliver inden for et bestemt interval, hvilket letter effektiv træning af modellen. Residualforbindelser tillader, at gradientsignaler kan flyde gennem netværket uden at forsvinde, hvilket forbedrer træningen af dybe neurale netværk.
Transformere arbejder på sekvenser af data, som kan være ord i en sætning eller anden sekventiel information. De anvender self-attention for at bestemme relevansen af hver del af sekvensen i forhold til de andre og gør det muligt for modellen at fokusere på de vigtigste elementer, der påvirker outputtet.
Ved self-attention sammenlignes hvert token i sekvensen med alle andre tokens for at beregne attention-scorer. Disse scorer angiver betydningen af hvert token i forhold til de andre, hvilket gør det muligt for modellen at fokusere på de mest relevante dele af sekvensen. Dette er afgørende for at forstå kontekst og betydning i sprogopgaver.
Disse er byggestenene i en transformermodel og består af self-attention- og feedforward-lag. Flere blokke stables for at danne dybe læringsmodeller, der kan indfange indviklede mønstre i data. Denne modulære opbygning gør det muligt for transformere at skalere effektivt med opgavens kompleksitet.
Transformere er mere effektive end RNN’er og CNN’er på grund af deres evne til at behandle hele sekvenser på én gang. Denne effektivitet gør det muligt at skalere op til meget store modeller, såsom GPT-3, der har 175 milliarder parametre. Transformerens skalerbarhed gør det muligt for dem at håndtere enorme mængder data effektivt.
Traditionelle modeller har svært ved at håndtere langtrækkende afhængigheder på grund af deres sekventielle natur. Transformere overvinder denne begrænsning gennem self-attention, som kan tage alle dele af sekvensen i betragtning samtidigt. Det gør dem særligt effektive til opgaver, der kræver forståelse af kontekst over lange tekstsekvenser.
Selvom de oprindeligt blev designet til NLP, er transformere blevet tilpasset til en lang række anvendelser, herunder computer vision, proteinfoldning og endda tidsseriefremskrivning. Denne alsidighed viser transformerens brede anvendelighed på tværs af forskellige domæner.
Transformere har markant forbedret ydeevnen i NLP-opgaver såsom oversættelse, opsummering og sentimentanalyse. Modeller som BERT og GPT er fremtrædende eksempler, der udnytter transformerarkitekturen til at forstå og generere menneskelignende tekst og sætter nye standarder inden for NLP.
Inden for maskinoversættelse udmærker transformere sig ved at forstå konteksten af ord i en sætning, hvilket giver mere præcise oversættelser sammenlignet med tidligere metoder. Deres evne til at behandle hele sætninger på én gang muliggør mere sammenhængende og kontekstuelt korrekte oversættelser.
Transformere kan modellere sekvenser af aminosyrer i proteiner og hjælpe med at forudsige proteinstrukturer, hvilket er afgørende for lægemiddeludvikling og forståelse af biologiske processer. Denne anvendelse fremhæver transformerens potentiale inden for videnskabelig forskning.
Ved at tilpasse transformerarkitekturen er det muligt at forudsige fremtidige værdier i tidsseriedata, såsom prognoser for elforbrug, ved at analysere tidligere sekvenser. Dette åbner nye muligheder for transformere inden for områder som finans og ressourceforvaltning.
BERT-modeller er designet til at forstå konteksten af et ord ved at se på de omkringliggende ord, hvilket gør dem meget effektive til opgaver, der kræver forståelse af ordenes relationer i en sætning. Denne bidirektionelle tilgang tillader BERT at indfange kontekst mere effektivt end ensrettede modeller.
GPT-modeller er autoregressive og genererer tekst ved at forudsige det næste ord i en sekvens baseret på de foregående ord. De bruges bredt i applikationer som tekstfuldførelse og dialoggenerering og demonstrerer deres evne til at producere menneskelignende tekst.
Oprindeligt udviklet til NLP er transformere blevet tilpasset til computer vision-opgaver. Vision transformers behandler billeddata som sekvenser, hvilket gør dem i stand til at anvende transformer-teknikker på visuelle input. Denne tilpasning har ført til fremskridt inden for billedgenkendelse og -behandling.
Træning af store transformermodeller kræver betydelige beregningsressourcer, ofte med store datasæt og kraftfuld hardware som GPU’er. Dette udgør en udfordring med hensyn til omkostninger og tilgængelighed for mange organisationer.
Efterhånden som transformere bliver mere udbredte, bliver spørgsmål som bias i AI-modeller og etisk brug af AI-genereret indhold stadig vigtigere. Forskere arbejder på metoder til at afbøde disse problemer og sikre ansvarlig AI-udvikling, hvilket understreger behovet for etiske rammer i AI-forskning.
Transformerens alsidighed åbner fortsat nye muligheder for forskning og anvendelse, fra forbedring af AI-drevne chatbots til bedre dataanalyse inden for områder som sundhedsvæsen og finans. Fremtiden for transformere rummer spændende muligheder for innovation på tværs af brancher.
Afslutningsvis repræsenterer transformere et markant fremskridt inden for AI-teknologi og tilbyder enestående muligheder for behandling af sekventielle data. Deres innovative arkitektur og effektivitet har sat en ny standard i feltet og drevet AI-applikationer til nye højder. Uanset om det er sprogforståelse, videnskabelig forskning eller visuel databehandling, fortsætter transformere med at omdefinere, hvad der er muligt inden for kunstig intelligens.
Transformere har revolutioneret feltet inden for kunstig intelligens, især inden for naturlig sprogbehandling og forståelse. Artiklen “AI Thinking: A framework for rethinking artificial intelligence in practice” af Denis Newman-Griffis (udgivet i 2024) udforsker en ny begrebsramme kaldet AI Thinking. Denne ramme modellerer centrale beslutninger og overvejelser involveret i AI-brug på tværs af faglige perspektiver og adresserer kompetencer i at motivere AI-brug, formulere AI-metoder og placere AI i sociotekniske sammenhænge. Formålet er at bygge bro mellem akademiske discipliner og omforme fremtiden for AI i praksis. Læs mere.
En anden væsentlig indsats ses i “Artificial intelligence and the transformation of higher education institutions” af Evangelos Katsamakas m.fl. (udgivet i 2024), som bruger en kompleks systemtilgang til at kortlægge de kausale feedback-mekanismer i AI-transformationen af videregående uddannelsesinstitutioner (HEIs). Undersøgelsen diskuterer de kræfter, der driver AI-transformationen og dens indvirkning på værdiskabelse, og understreger behovet for, at institutionerne tilpasser sig AI-teknologiske fremskridt, mens de håndterer akademisk integritet og ændringer i beskæftigelsen. Læs mere.
Inden for softwareudvikling undersøger artiklen “Can Artificial Intelligence Transform DevOps?” af Mamdouh Alenezi og kolleger (udgivet i 2022) krydsfeltet mellem AI og DevOps. Undersøgelsen fremhæver, hvordan AI kan forbedre funktionaliteten af DevOps-processer og facilitere effektiv softwarelevering. Den understreger de praktiske implikationer for softwareudviklere og virksomheder ved at udnytte AI til at transformere DevOps-praksis. Læs mere
Transformere er en neuralt netværksarkitektur introduceret i 2017, der bruger self-attention mekanismer til parallel behandling af sekventielle data. De har revolutioneret kunstig intelligens, især inden for naturlig sprogbehandling og computer vision.
I modsætning til RNN'er og CNN'er behandler transformere alle elementer i en sekvens samtidigt ved hjælp af self-attention, hvilket muliggør større effektivitet, skalerbarhed og evnen til at fange langtrækkende afhængigheder.
Transformere bruges bredt i NLP-opgaver som oversættelse, opsummering og sentimentanalyse, samt i computer vision, forudsigelse af proteinstrukturer og tidsseriefremskrivning.
Bemærkelsesværdige transformermodeller inkluderer BERT (Bidirectional Encoder Representations from Transformers), GPT (Generative Pre-trained Transformers) og Vision Transformers til billedbehandling.
Transformere kræver betydelige beregningsressourcer til træning og implementering. De rejser også etiske overvejelser som potentiel bias i AI-modeller og ansvarlig brug af genereret AI-indhold.
Smarte chatbots og AI-værktøjer samlet ét sted. Forbind intuitive blokke for at gøre dine ideer til automatiserede Flows.
En transformer-model er en type neuralt netværk, der er specifikt designet til at håndtere sekventielle data, såsom tekst, tale eller tidsseriedata. I modsætnin...
En Generativ Foruddannet Transformer (GPT) er en AI-model, der udnytter dyb læring til at producere tekst, der tæt efterligner menneskelig skrivning. Baseret på...
Tekstgenerering med store sprogmodeller (LLM'er) refererer til den avancerede brug af maskinlæringsmodeller til at producere menneskelignende tekst ud fra promp...