Dokumenter
Din chatbot kan øjeblikkeligt få adgang til og bruge dokumenter, HTML-sider og endda YouTube-videoer for at tilpasse din unikke kontekst. Perfekt til at tilføje...
2 min læsning
AI Chatbot
Knowledge Management
+3
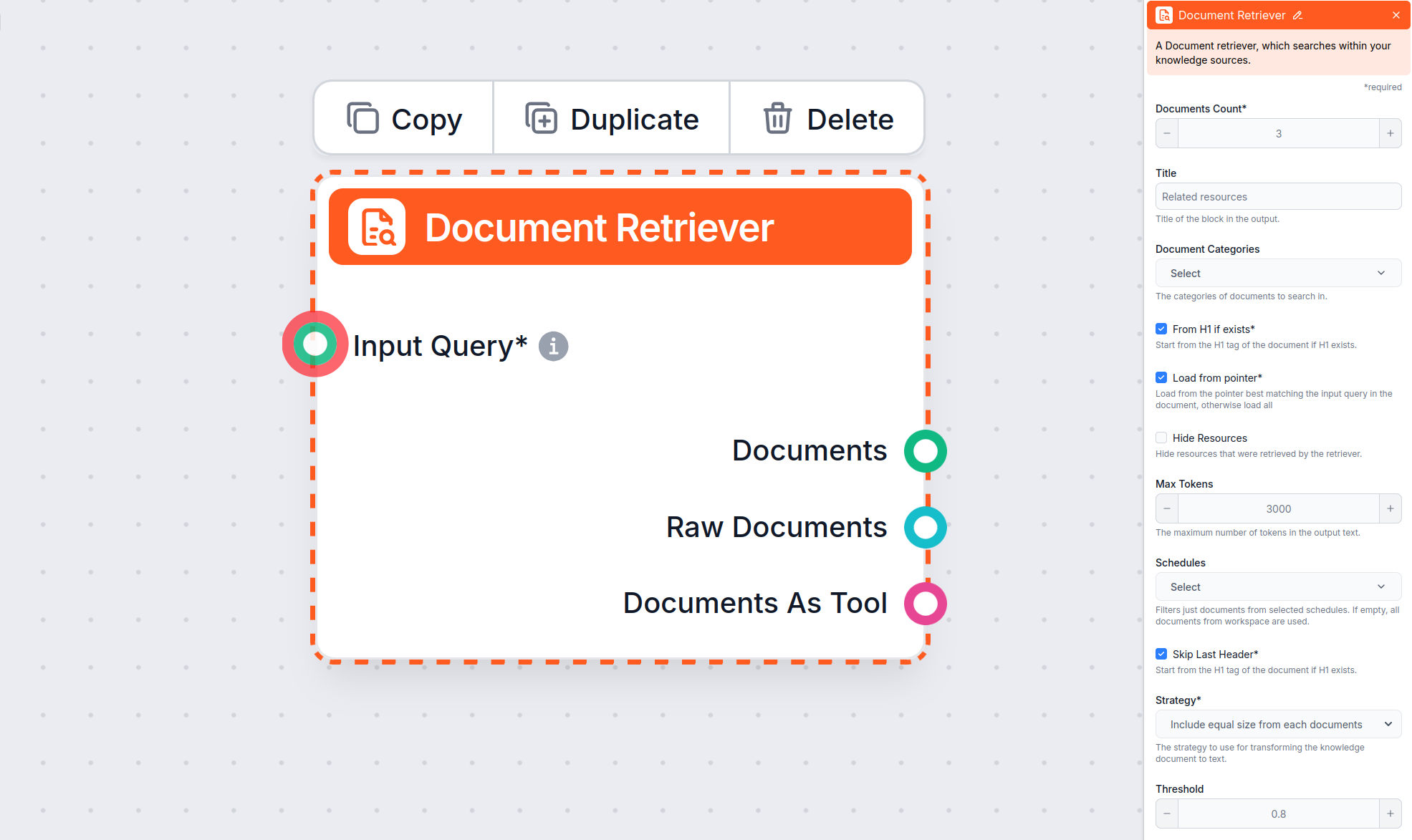
Lær, hvordan du indstiller parametrene ‘Fra H1 hvis eksisterer’, ‘Indlæs fra markør’ og ‘Spring sidste header over’.
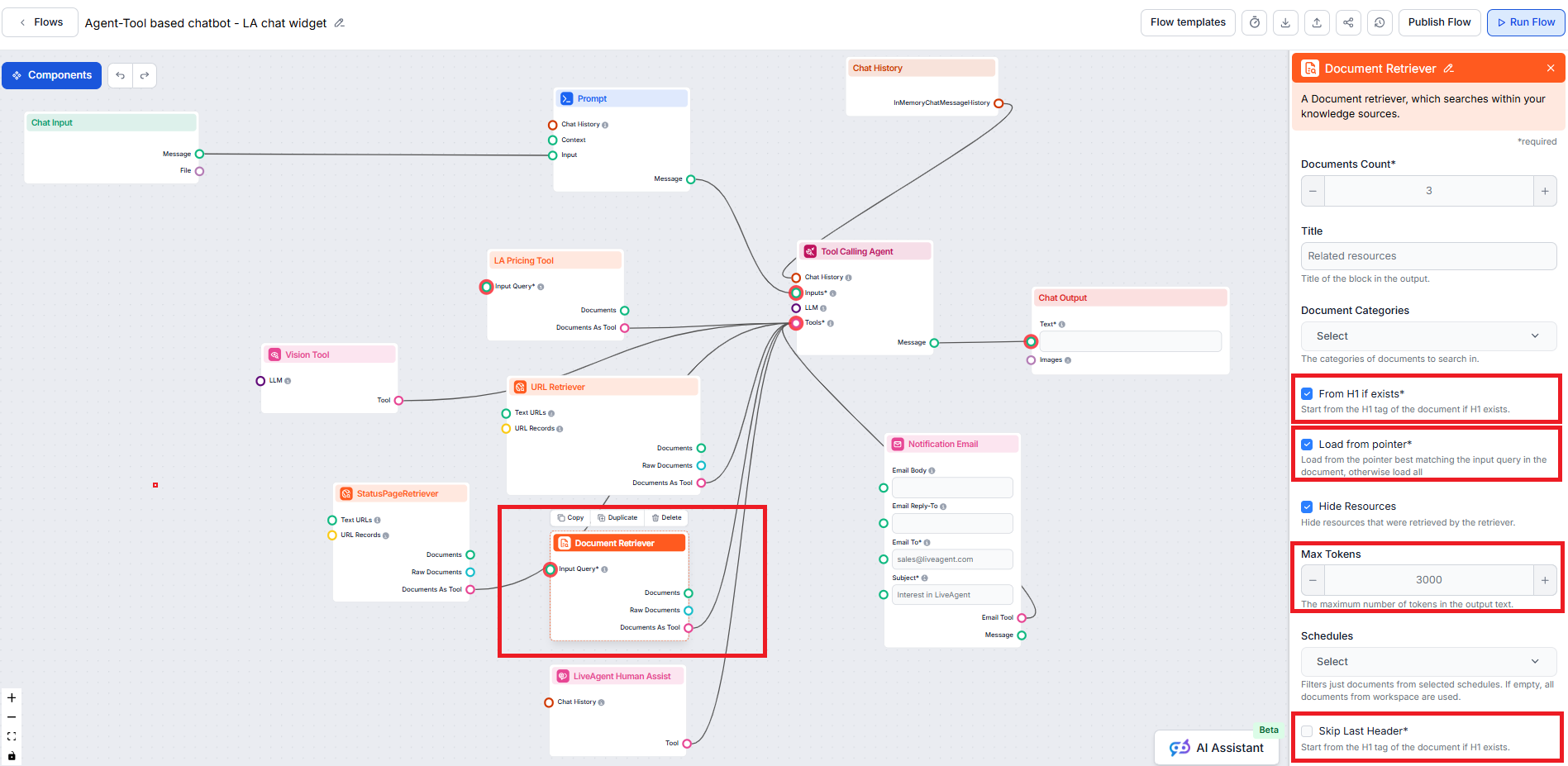
Document Retriever-komponenten gør det muligt for chatbotten at hente viden fra de kilder, du har angivet under Dokumenter og Skemaer. Komponentens rolle er at styre hentningen, og flere parametre påvirker, hvordan komponenten henter information fra disse dokumenter.
Muligheden Fra H1 hvis eksisterer fortæller retrieveren, at den skal begynde at udtrække indhold fra det H1-header, den finder (normalt artiklens hovedtitel).
Hvad sker der?
Eksempel på brug:
Du ønsker kun at hente selve guiden uden navigation eller sidehoved-rod, der findes på dit website.
Bemærk:
Fra H1 hvis eksisterer er aktiveret som standard i Document Retriever-komponenten.
Muligheden Indlæs fra markør giver dig mere præcision ved at lade Document Retriever indlæse data fra en markør i den måske længere artikel.
Hvad sker der?
Hvad er en “markør”?
En markør er typisk en unik streng eller overskrift, der findes i dokumentet (for eksempel et H2 eller en specifik sætning eller sektionstitel).
Eksempel på brug:
Du vil springe introduktionsafsnit over og hente information fra en bestemt relevant sektion i en måske lang artikel eller et dokument (fx fra “Trin 4: Tilføj en live chat-knap” i en opsætningsguide).
Muligheden Spring sidste header over er nyttig for at ignorere den sidste header i dokumentet, som ofte gentages eller bruges til navigation eller sidefod.
Hvad sker der?
Eksempel på brug:
Du vil undgå, at Document Retriever indlæser en sidefodsnavigationsheader (såsom “Andre artikler” nederst på en hjælpeside), så kun hovedindholdet behandles.
Bemærk:
Spring sidste header over kan hjælpe ved dokumenter, der automatisk genererer sidefødder eller gentagne navigationselementer. Hvis du dog ikke har sådanne sektioner, kan brug af denne parameter betyde, at en del af artiklen med gyldig information ikke bliver hentet. Det anbefales derfor at lade denne mulighed være umarkeret, indtil der er en gyldig grund til at aktivere den.
Parameteren Maks. tokens gør det muligt at styre det maksimale antal tokens (ord og tegnsætning, som optalt af den underliggende AI-model), som Document Retriever vil returnere fra den udtrukne tekst.
Hvad sker der?
Standardværdi:
Standardværdien er typisk 3000 tokens, men du kan justere dette efter behov.
Eksempel på brug:
Hvis du behandler lange dokumenter, hjælper det at sætte en lavere Maks. tokens-værdi med at holde svarene korte. For det bedste resultat bør du dog overveje at aktivere parameteren “Indlæs fra markør”. Det sikrer, at den udtrukne tekst starter ved den mest relevante sektion i dokumentet i stedet for fra begyndelsen, så du får et fokuseret og håndterbart informationsudsnit inden for din valgte token-grænse. Denne kombination er særlig nyttig, når du ønsker korte, kontekstrelevante outputs fra store kilder.
Bemærk:
Hvis du oplever, at information afskæres, så prøv at øge værdien for Maks. tokens. Ønsker du derimod kortere og mere fokuserede outputs, så sæt Maks. tokens lavere.
Når Document Retriever finder flere relevante dokumenter, bestemmer parameteren Strategi, hvordan de samles til én samlet tekst-output til din chatbot, under hensyntagen til “Maks. tokens”-grænsen.
To strategimuligheder:
Inkluder lige meget fra hvert dokument:
Token-grænsen deles ligeligt. For eksempel, med tre dokumenter og en grænse på 3.000 tokens, får hvert op til 1.000 tokens. Det sikrer, at alle kilder bidrager lige meget, hvilket er nyttigt, hvis du ønsker et balanceret svar, der trækker på flere dokumenter.
Kæd dokumenter sammen, fyld fra det første op til tokens-grænsen:
Dokumenterne tilføjes i rækkefølge efter relevans, indtil token-grænsen er nået. Det mest relevante dokument fylder først pladsen; hvis der er plads tilbage, tilføjes mindre relevante dokumenter i rækkefølge. Hvis det første dokument er langt, kan det bruge hele grænsen selv.
Hvordan vælger du?
Bemærk:
Disse strategier påvirker kun, hvordan teksten sammensættes fra de hentede dokumenter, før den sendes videre (fx til AI-generering). De ændrer ikke, hvilke dokumenter der hentes – kun hvordan deres indhold samles og beskæres, så det passer inden for Maks. tokens-indstillingen.
Selvom denne artikel fokuserer på opsætning af ‘Fra H1 hvis eksisterer’, ‘Indlæs fra markør’, ‘Spring sidste header over’ og ‘Maks. tokens’, tilbyder Document Retriever også yderligere parametre, som hjælper med at styre, hvordan dokumenter vælges og hentes:
Denne indstilling begrænser, hvor mange dokumenter flowet skal hente, så resultaterne forbliver relevante og svar genereres hurtigt.
Denne valgfrie indstilling giver dig mulighed for at begrænse hentningen til én eller flere kategorier, du har oprettet under Dokumenter i Knowledge Sources.
Dette lader dig inkludere eller skjule en separat sektion før selve chatbot-svaret med en liste over de ressourcer, retrieveren har hentet. Til integration med LiveAgent skal denne være markeret, da denne sektion ikke understøttes og ikke vil blive vist korrekt i LiveAgent-chatbot-widgetten.
Lader dig begrænse hentningen til ét eller flere Skemaer, som du har angivet til at crawle eller opdatere indhold i Knowledge Sources.
Styrer, hvor tæt de hentede dokumenter skal matche inputforespørgslen, ud fra en relevans-score (fra 0 til 1). For eksempel anbefales en tærskel på 0,7–0,8 for meget relevante svar. Højere tærskel giver mere præcise matches, mens lavere tærskler kan inkludere mindre relevante dokumenter.
Eksempel:
Hvis du sætter tærsklen til 0,6 og har fire artikler med relevans-score på 0,8, 0,65, 0,5 og 0,9, vil kun de over 0,6 (altså 0,8, 0,65 og 0,9) blive brugt til udtrækning.
Hvis svaret fra chatbotten ikke indeholder information, som du er sikker på, at chatbotten har tilgængelig i dine dokumenter eller skemaer, så prøv at tjekke samtalehistorikken med “Verbose”-muligheden for at se detaljerede logs over, om Document Retriever blev brugt og hvilke dokumenter, der blev hentet. Justér om nødvendigt dine indstillinger og prompt baseret på disse logs.
Din chatbot kan øjeblikkeligt få adgang til og bruge dokumenter, HTML-sider og endda YouTube-videoer for at tilpasse din unikke kontekst. Perfekt til at tilføje...

En detaljeret guide til kun at importere specifikke sektioner fra docs.cpanel.net til din FlowHunt-chatbot, så den bliver ekspert i målrettede cPanel-emner uden...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.