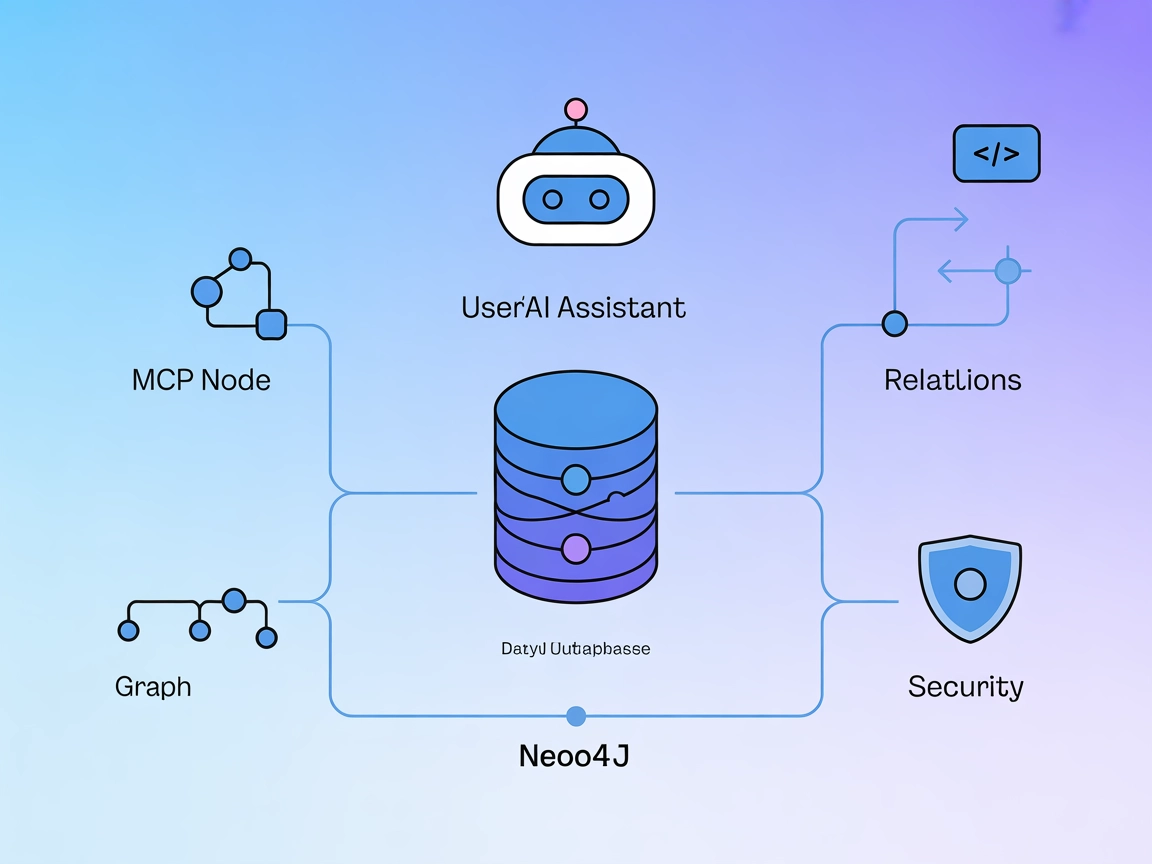
Neo4j MCP Server Integration
Neo4j MCP Server forbinder AI-assistenter med Neo4j grafdatabasen og muliggør sikre, naturligt sprogstyrede grafoperationer, Cypher-forespørgsler og automatiser...
4 min læsning
AI
Graph Database
+5
Neo4j MCP Server forbinder AI-assistenter med Neo4j grafdatabasen og muliggør sikre, naturligt sprogstyrede grafoperationer, Cypher-forespørgsler og automatiser...
NASA MCP Server giver en samlet grænseflade for AI-modeller og udviklere til at få adgang til over 20 NASA-datakilder. Den standardiserer hentning, behandling o...
Data Exploration MCP Server forbinder AI-assistenter med eksterne datasæt til interaktiv analyse. Det giver brugerne mulighed for at udforske CSV- og Kaggle-dat...
MCP Code Executor MCP Server gør det muligt for FlowHunt og andre LLM-drevne værktøjer at udføre Python-kode sikkert i isolerede miljøer, håndtere afhængigheder...
Reexpress MCP Server bringer statistisk verifikation til LLM-arbejdsgange. Ved hjælp af Similarity-Distance-Magnitude (SDM) estimatoren leverer den robuste till...
Databricks Genie MCP Server gør det muligt for store sprogmodeller at interagere med Databricks-miljøer via Genie API'et og understøtter samtalebaseret dataudfo...
JupyterMCP muliggør problemfri integration af Jupyter Notebook (6.x) med AI-assistenter via Model Context Protocol. Automatisér kodeudførelse, håndter celler og...
En AI Data Analyst sammensmelter traditionelle dataanalysefærdigheder med kunstig intelligens (AI) og maskinlæring (ML) for at udtrække indsigter, forudsige tre...
Anaconda er en omfattende, open source-distribution af Python og R, designet til at forenkle pakkehåndtering og udrulning til videnskabelig computing, dataviden...
Areal under kurven (AUC) er en grundlæggende måling inden for maskinlæring, der anvendes til at evaluere ydeevnen af binære klassifikationsmodeller. Den kvantif...
Et beslutningstræ er et kraftfuldt og intuitivt værktøj til beslutningstagning og forudsigende analyse, anvendt både i klassificerings- og regressionopgaver. De...
Udforsk bias i AI: forstå dets kilder, indvirkning på maskinlæring, eksempler fra den virkelige verden og strategier til at afbøde det med henblik på at opbygge...
BigML er en maskinlæringsplatform designet til at gøre oprettelse og implementering af prædiktive modeller enklere. Grundlagt i 2011 har platformen til formål a...
Data mining er en sofistikeret proces, hvor store mængder rå data analyseres for at afdække mønstre, relationer og indsigter, som kan informere forretningsstrat...
Datavask er den afgørende proces med at opdage og rette fejl eller uoverensstemmelser i data for at forbedre kvaliteten, hvilket sikrer nøjagtighed, konsistens ...
Dimensionel reduktion er en afgørende teknik inden for databehandling og maskinlæring, der reducerer antallet af inputvariabler i et datasæt, mens essentiel inf...
Udforsk hvordan Feature Engineering og Ekstraktion forbedrer AI-modellens ydeevne ved at omdanne rå data til værdifuld indsigt. Opdag nøgleteknikker som feature...
Google Colaboratory (Google Colab) er en cloud-baseret Jupyter-notebook-platform fra Google, der gør det muligt for brugere at skrive og køre Python-kode i brow...
Gradient Boosting er en kraftfuld maskinlæringsensemble-teknik til regression og klassifikation. Den bygger modeller sekventielt, typisk med beslutningstræer, f...
Jupyter Notebook er en open source-webapplikation, der gør det muligt for brugere at oprette og dele dokumenter med levende kode, ligninger, visualiseringer og ...
Justeret R-kvadrat er et statistisk mål, der bruges til at evaluere, hvor godt en regressionsmodel passer, idet der tages højde for antallet af prædiktorer for ...
K-Means Klyngedannelse er en populær ikke-superviseret maskinlæringsalgoritme, der opdeler datasæt i et foruddefineret antal forskellige, ikke-overlappende klyn...
K-nærmeste naboer (KNN)-algoritmen er en ikke-parametrisk, overvåget læringsalgoritme, der bruges til klassifikations- og regressionsopgaver inden for maskinlær...
Kaggle er et online fællesskab og en platform for dataforskere og maskinlæringsingeniører til at samarbejde, lære, konkurrere og dele indsigter. Efter at være b...
Kausal inferens er en metodologisk tilgang, der bruges til at fastslå årsags- og virkningssammenhænge mellem variable, hvilket er afgørende i videnskaberne for ...
En AI-klassifikator er en maskinlæringsalgoritme, der tildeler klasselabels til inputdata og kategoriserer information i foruddefinerede klasser baseret på møns...
Lineær regression er en grundlæggende analytisk teknik inden for statistik og maskinlæring, der modellerer forholdet mellem afhængige og uafhængige variabler. K...
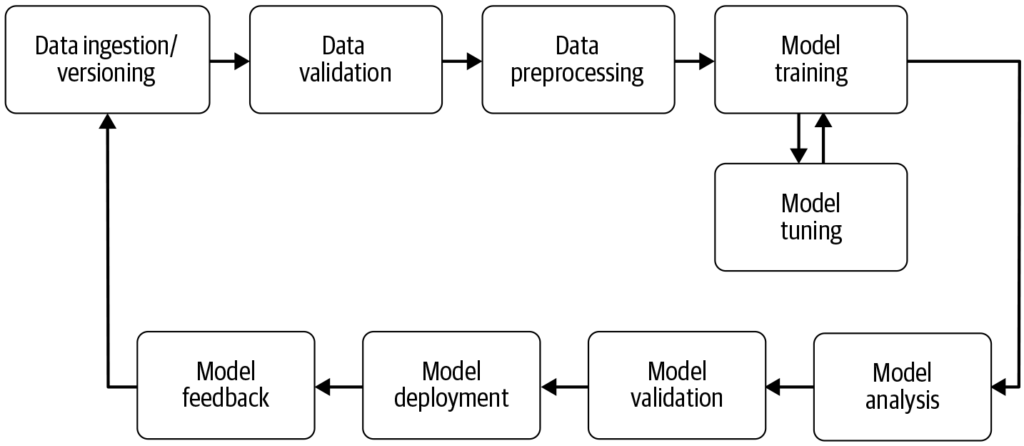
En maskinlæringspipeline er et automatiseret workflow, der strømliner og standardiserer udvikling, træning, evaluering og implementering af maskinlæringsmodelle...
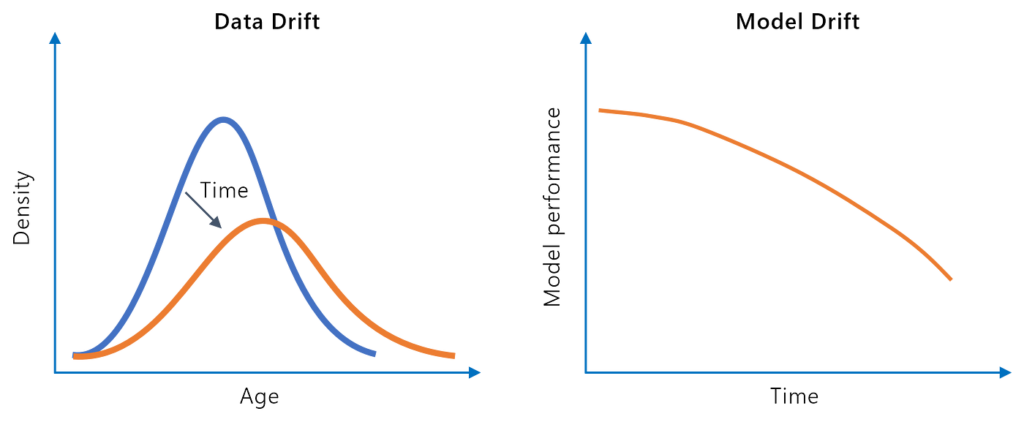
Modeldrift, eller modelnedbrydning, refererer til faldet i en maskinlæringsmodels forudsigende præstation over tid på grund af ændringer i det virkelige miljø. ...
Modelkædning er en maskinlæringsteknik, hvor flere modeller forbindes sekventielt, således at hver modells output fungerer som input til den næste. Denne tilgan...
NumPy er et open-source Python-bibliotek, der er afgørende for numerisk databehandling og tilbyder effektive arrayoperationer og matematiske funktioner. Det dan...
Pandas er et open-source bibliotek til datamanipulation og -analyse for Python, kendt for sin alsidighed, robuste datastrukturer og brugervenlighed ved håndteri...
Prædiktiv modellering er en sofistikeret proces inden for datavidenskab og statistik, der forudsiger fremtidige udfald ved at analysere historiske datamønstre. ...
Scikit-learn er et kraftfuldt open source maskinlæringsbibliotek til Python, der leverer simple og effektive værktøjer til prædiktiv dataanalyse. Det er meget u...
Semi-superviseret læring (SSL) er en maskinlæringsteknik, der udnytter både mærkede og umærkede data til at træne modeller, hvilket gør den ideel, når det er up...