
Generatives Gegnerisches Netzwerk (GAN)
Ein Generatives Gegnerisches Netzwerk (GAN) ist ein maschinelles Lern-Framework mit zwei neuronalen Netzwerken – einem Generator und einem Diskriminator –, die ...
8 Min. Lesezeit
GAN
Generative AI
+5
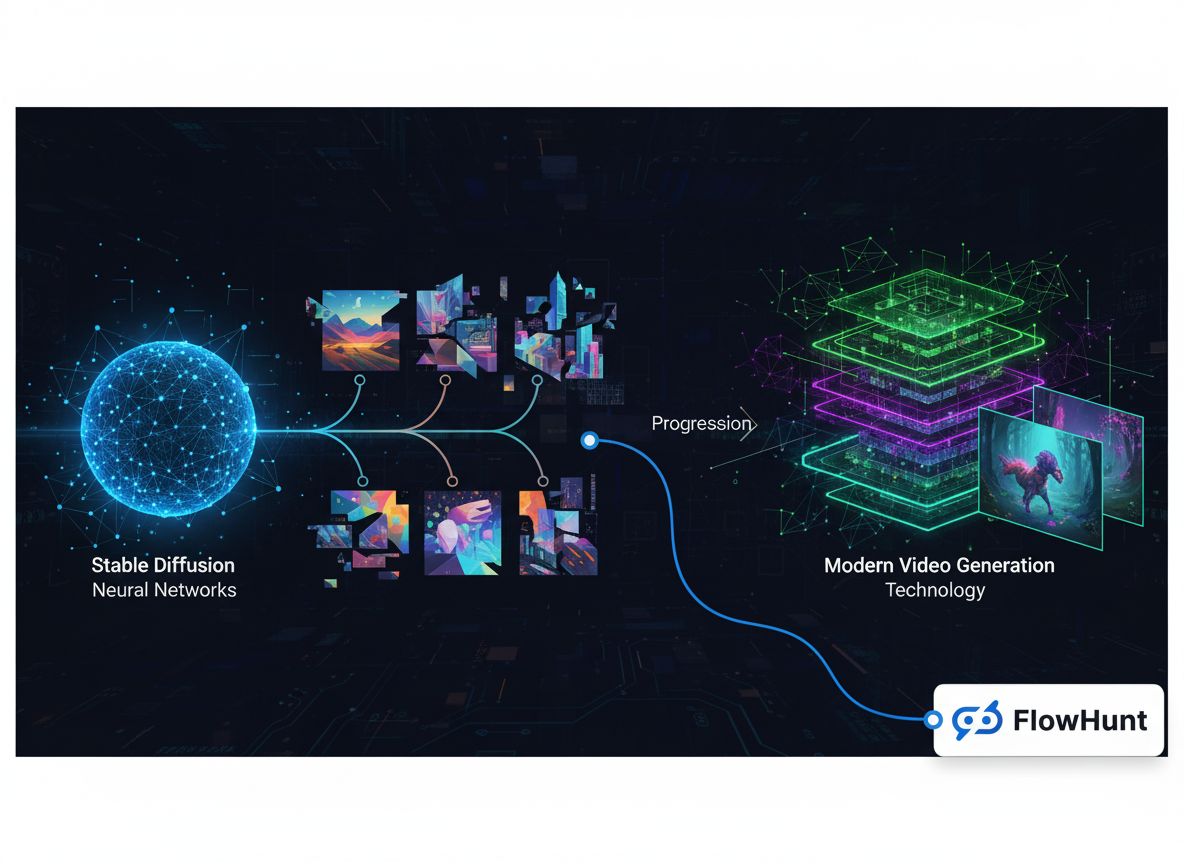
Erkunden Sie die technische Entwicklung von generativen Medienplattformen, von frühen Bildmodellen bis hin zur modernen Videogenerierung, und wie spezialisierte Inferenzoptimierung zu einem Geschäft mit über 100 Millionen Dollar wurde.
Die Landschaft der generativen Medien hat in den letzten Jahren einen bemerkenswerten Wandel durchlaufen – von experimentellen Forschungsprojekten hin zu einem milliardenschweren Infrastruktursektor. Was als spezialisierte Bildgenerierungsmodelle begann, hat sich zu einem umfassenden Ökosystem für Bildsynthese, Videokreation, Audiogenerierung und fortschrittliche Bearbeitung entwickelt. Diese technische Geschichte beleuchtet, wie Unternehmen wie FAL ein Geschäft mit über 100 Millionen Dollar Umsatz aufbauten, indem sie eine entscheidende Marktlücke erkannten: Entwickler benötigten optimierte, skalierbare Inferenz-Infrastrukturen, die speziell für generative Medienmodelle konzipiert sind – nicht für generisches GPU-Management oder Sprachmodell-Hosting. Der Weg von Stable Diffusion 1.5 bis zu modernen Videomodellen wie Veo3 zeigt wichtige Lehren über Marktpositionierung, technische Spezialisierung und die Infrastruktur-Anforderungen, die es KI-Anwendungen ermöglichen, von Forschungsprototypen zu Produktionssystemen für Millionen von Entwicklern zu skalieren.

Generative Medien stellen eine grundsätzlich andere Kategorie künstlicher Intelligenz dar als die großen Sprachmodelle, die zuletzt im Rampenlicht standen. Während Sprachmodelle Texte verarbeiten und anhand erlernter Muster Antworten generieren, erschaffen generative Mediensysteme visuelle und auditive Inhalte – Bilder, Videos, Musik und Soundeffekte – aus Textbeschreibungen, vorhandenen Bildern oder anderen Eingabeformen. Diese Unterscheidung ist mehr als semantisch; sie spiegelt tiefgreifende Unterschiede in den technischen Anforderungen, Marktdynamiken und Geschäftschancen wider. Generative Medienmodelle arbeiten unter anderen Rechenrestriktionen, benötigen spezialisierte Optimierungstechniken und bedienen Anwendungsfälle, die traditionelle Sprachmodell-Infrastrukturen nicht effizient abdecken können. Der Aufstieg generativer Medien hat eine völlig neue Klasse von Infrastrukturunternehmen hervorgebracht, die sich gezielt auf die Optimierung der Inferenz für diese Modelle konzentrieren. So können Entwickler anspruchsvolle Bild- und Videogenerierung in ihre Anwendungen integrieren, ohne komplexe GPU-Deployments zu verwalten oder mit ineffizienter Ressourcennutzung zu kämpfen.
Die technischen Anforderungen für generative Medieninferenz unterscheiden sich deutlich vom Betrieb von Sprachmodellen. Bildgenerierungsmodelle wie Stable Diffusion und Flux arbeiten mit iterativen Diffusionsprozessen, die sorgfältiges Speichermanagement, präzise Zeitoptimierung und effiziente Stapelverarbeitung erfordern. Die Videogenerierung bringt eine weitere Komplexitätsebene hinzu: Sie verlangt zeitliche Konsistenz, Audiosynchronisation und deutlich höhere Rechenressourcen. Diese Anforderungen lassen sich mit generischen GPU-Orchestrierungsplattformen oder Sprachmodell-Inferenzdiensten nicht effizient erfüllen. Stattdessen ist spezialisierte Infrastruktur nötig, die von Grund auf auf die Besonderheiten von Diffusionsmodellen, autoregressiver Bildgenerierung und Videosynthese ausgelegt ist. Unternehmen, die diese Lücke früh erkannten und gezielt Infrastruktur dafür entwickelten, konnten sich signifikante Marktanteile sichern, als sich generative Medien branchenübergreifend durchsetzten.
Starten Sie heute Ihre kostenlose Testversion und sehen Sie innerhalb weniger Tage Ergebnisse.
Die Entscheidung, sich auf generative Medien zu spezialisieren, anstatt den vermeintlich naheliegenderen Weg des Sprachmodell-Hostings zu gehen, zählt zu den folgenreichsten strategischen Weichenstellungen in der jüngeren Geschichte der KI-Infrastruktur. Als die FAL-Gründer 2022/23 ihre Optionen bewerteten, standen sie am Scheideweg: Sollten sie ihre Python-Laufzeitumgebung zu einer allgemeinen Sprachmodell-Inferenzplattform ausbauen oder auf den aufkommenden Bereich der generativen Medien setzen? Die Antwort offenbart wichtige Erkenntnisse über Marktdynamik, Wettbewerbspositionierung und die Bedeutung, Kämpfe zu wählen, die man gewinnen kann. Das Hosting von Sprachmodellen schien zwar attraktiv, da enorme Aufmerksamkeit und Finanzierung in diesen Bereich flossen, aber die Wettbewerbssituation war aussichtslos. OpenAI hatte GPT als dominantes Modell mit riesiger Nutzerbasis und Einnahmeströmen etabliert. Anthropic baute mit starkem Rückhalt und technischem Know-how an Claude. Google, Microsoft und andere Tech-Giganten investierten Milliarden in eigene Sprachmodell-Infrastruktur. Für ein Startup hätte dies bedeutet, in direkten Wettbewerb mit Unternehmen zu treten, die über weit überlegene Ressourcen, Marktpositionen und die Möglichkeit verfügen, Sprachmodelle sogar zum Selbstkostenpreis oder Verlust anzubieten, wenn dies strategisch sinnvoll ist.
Der Markt für generative Medien hingegen bot eine grundsätzlich andere Wettbewerbssituation. Mit der Veröffentlichung von Stable Diffusion 1.5 im Jahr 2022 entstand ein unmittelbarer Bedarf an optimierter Inferenz-Infrastruktur, aber es hatte sich noch kein Platzhirsch etabliert. Das Modell war Open Source, konnte also von jedem heruntergeladen werden, doch es fehlte den meisten Entwicklern an Expertise oder Ressourcen, es effizient zu optimieren. Genau hier lag die ideale Gelegenheit für ein spezialisiertes Infrastrukturunternehmen. FAL erkannte, dass Entwickler diese Modelle nutzen wollten, aber nicht die Komplexität von GPU-Deployment, Modelloptimierung und Skalierung stemmen wollten. Durch die ausschließliche Fokussierung auf generative Medien konnte FAL Experte in diesem speziellen Bereich werden, enge Beziehungen zu Modellentwicklern und Entwicklern aufbauen und sich als Anlaufstelle für generative Medieninferenz etablieren. Diese Spezialisierungsstrategie erwies sich als äußerst erfolgreich und ermöglichte FAL, sich von einem Wendepunkt zu einem Unternehmen mit 2 Millionen Entwicklern und über 350 Modellen sowie mehr als 100 Millionen Dollar Jahresumsatz zu entwickeln.
Das technische Fundament moderner generativer Medienplattformen basiert auf ausgefeilter Inferenzoptimierung, die weit über das bloße Ausführen von Modellen auf GPUs hinausgeht. Als Entwickler erstmals Stable Diffusion 1.5 nutzten, versuchten viele, es selbst auf generischer Cloud-Infrastruktur oder lokalen GPUs zu betreiben. Das offenbarte gravierende Ineffizienzen: Modelle waren nicht auf die jeweilige Hardware optimiert, Speicher wurde durch ineffizientes Batching verschwendet und die Auslastung war schlecht, weil jede Nutzerlast isoliert lief. Ein Entwickler nutzte vielleicht nur 20–30 % seiner GPU-Kapazität, zahlte aber für 100 %. Diese Verschwendung eröffnete die Chance für eine Plattform, die Nachfrage vieler Nutzer bündelt, Inferenz für spezifische Hardwarekonfigurationen optimiert und durch intelligentes Batching und Scheduling eine viel höhere Auslastung erzielt. FAL setzte dabei auf eigene CUDA-Kernels – Low-Level-GPU-Code, der bestimmte Operationen innerhalb generativer Modelle gezielt beschleunigt und so die Leistung gegenüber generischen Implementierungen deutlich steigert.
Die Infrastrukturherausforderung geht über reine Performance-Optimierung hinaus. Generative Medienmodelle weisen Besonderheiten auf, die spezielle Behandlung erfordern. Diffusionsmodelle, auf denen die meisten Bildgenerierungssysteme basieren, arbeiten iterativ: Das Modell wandelt zufälliges Rauschen Schritt für Schritt in Bilder um. Jeder Schritt erfordert sorgfältiges Speichermanagement, um den GPU-Speicher nicht zu überlaufen, und der Prozess muss schnell genug ablaufen, um für interaktive Anwendungen akzeptable Latenzzeiten zu bieten. Die Videogenerierung bringt zeitliche Dimensionen ins Spiel: Modelle müssen Konsistenz über Frames hinweg bewahren und hochwertige Inhalte mit 24 oder 30 Bildern pro Sekunde erzeugen. Audiomodelle haben wiederum eigene Anforderungen – etwa Echtzeitfähigkeit oder hohe Ausgabequalität. Eine Plattform, die all diese Modalitäten bedient, muss in jedem Bereich tiefes Spezialwissen und Optimierungskompetenz aufbauen. Genau diese Spezialisierung macht generative Medieninfrastruktur-Unternehmen wertvoll – sie sammeln Know-how und Optimierungstechniken, die einzelne Entwickler nicht ohne Weiteres replizieren können.
Erhalten Sie die neuesten Tipps, Trends und Angebote kostenlos.
Die Geschichte der generativen Medien lässt sich anhand der Entwicklung der Bildgenerierungsmodelle nachzeichnen, von denen jedes einen bedeutsamen Wendepunkt im Markt markiert. Stable Diffusion 1.5, veröffentlicht 2022, war der Auslöser, der generative Medien aus der akademischen Nische zu einem praxisnahen Werkzeug für Entwickler machte. Das Modell war Open Source, im Vergleich zu früheren Diffusionsmodellen relativ effizient und lieferte für viele Anwendungsfälle brauchbare Bilder. Für FAL bedeutete Stable Diffusion 1.5 den Moment, in dem sie ihre Chance zur kompletten Neuausrichtung erkannten. Sie boten eine optimierte, API-bereite Version des Modells an, die Entwickler ohne eigene GPU-Infrastruktur nutzen konnten. Die Resonanz war überwältigend – Entwickler sahen sofort den Wert, die Deployment-Komplexität nicht selbst lösen zu müssen, und Stable Diffusion 1.5 wurde FALs erster großer Umsatztreiber. Über das Basismodell hinaus explodierte das Ökosystem rund um Stable Diffusion 1.5 durch Feinabstimmungen. Entwickler schufen LoRAs (Low-Rank Adaptations) – leichtgewichtige Modellanpassungen, mit denen das Basismodell für konkrete Anwendungsfälle wie bestimmte Kunststile, Gesichter oder Objekte angepasst werden konnte. Dieses Ökosystem sorgte für einen positiven Kreislauf: Mehr Feinabstimmungsoptionen machten die Plattform wertvoller, zogen mehr Entwickler an und führten zu weiteren Feinabstimmungen.
Stable Diffusion 2.1, Nachfolger des Originalmodells, zeigte als warnendes Beispiel, wie entscheidend Modellqualität im Markt für generative Medien ist. Trotz einiger technischer Fortschritte wurde SD 2.1 oft als Rückschritt in der Bildqualität wahrgenommen, insbesondere bei Gesichtern und komplexen Szenen. Das Modell setzte sich nicht durch; viele Entwickler nutzten weiterhin Version 1.5. Diese Erfahrung lehrte: Im Bereich generativer Medien zählt die Qualität der Ergebnisse mehr als technische Raffinesse. Nutzer interessiert das erzielbare Resultat, nicht die Architektur oder Trainingsmethode. Stable Diffusion XL (SDXL), 2023 veröffentlicht, bedeutete einen echten Qualitätssprung. SDXL konnte hochauflösende Bilder mit mehr Details und besserer Texterkennung erzeugen. Für FAL war SDXL transformativ – es war das erste Modell, das für die Plattform über eine Million Dollar Umsatz generierte. Auch das LoRA-Ökosystem wuchs mit SDXL weiter, da Entwickler tausende Anpassungen für spezielle Anwendungen erstellten. Der Erfolg von SDXL bewies den erheblichen kommerziellen Bedarf an hochwertiger Bildgenerierung und bestätigte FALs Entscheidung zur Spezialisierung.
Die Veröffentlichung der Flux-Modelle von Black Forest Labs 2024 markierte einen weiteren Meilenstein. Flux war die erste Modellgeneration, die tatsächlich als „kommerziell nutzbar“ und „unternehmensreif“ bezeichnet werden konnte. Die Qualität war deutlich höher als bei früheren Modellen, die Generierungsgeschwindigkeit für Produktionsanwendungen akzeptabel und die Ergebnisse konsistent genug, um Geschäftsprodukte darauf aufzubauen. Für FAL war Flux ein Wendepunkt: Der Umsatz sprang im ersten Monat nach Veröffentlichung von 2 auf 10 Millionen Dollar, im Folgemonat auf 20 Millionen Dollar. Dieses explosive Wachstum spiegelte die aufgestaute Nachfrage nach hochwertiger, zuverlässig einsetzbarer Bildgenerierung wider. Flux erschien in mehreren Varianten – Schnell (schnelle, destillierte Version), Dev (höhere Qualität, nicht-kommerzielle Lizenzierung), Pro (Hosting in Partnerschaft) – für unterschiedliche Anwendungsfälle und Preispunkte. Der Erfolg von Flux zeigte auch, dass der Markt für generative Medien gereift war: Unternehmen waren bereit, substanziell in Bildgenerierung zu investieren, nicht nur mit der Technologie zu experimentieren.
Während die Bildgenerierung viel Aufmerksamkeit und Umsatz auf sich zog, eröffnete das Aufkommen praxisnaher Videogenerierungsmodelle ein völlig neues Marktpotenzial. Frühe Text-zu-Video-Modelle wie OpenAIs Sora zeigten, was theoretisch möglich war, waren aber kaum verfügbar oder lieferten aus Forschungssicht interessante, aber praktisch wenig nutzbare Ergebnisse. Die Videos waren oft ohne Ton, zeitlich inkonsistent und nicht professionell genug. Das änderte sich mit der Einführung von Modellen wie Veo3 von Google DeepMind, die einen echten Durchbruch in der Videogenerierungsqualität markierten. Veo3 konnte Videos mit synchronisiertem Audio, korrektem Timing und Rhythmus, genauer Lippen-Synchronisation und annähernd professioneller visueller Qualität erzeugen. Das Modell war rechenintensiv und teuer im Betrieb – deutlich aufwändiger als Bildgenerierung –, aber die Qualität rechtfertigte die Kosten für viele Anwendungen.
Der Einfluss hochwertiger Videogenerierung auf FALs Geschäft war erheblich. Video schuf eine völlig neue Umsatzquelle und zog eine andere Kundengruppe an. Während Bildgenerierung vor allem von einzelnen Entwicklern, Designern und kleinen Kreativteams genutzt wurde, interessierte sich bei Video vor allem das Enterprise-Segment, etwa für Werbeinhalte und professionelle Marketingvideos. FAL kooperierte mit verschiedenen Anbietern von Videomodellen, darunter Alibaba One, Kuaishou Kling und andere, um ein umfassendes Angebot zu schaffen. Das Umsatzwachstum der Plattform beschleunigte sich weiter, da Video einen immer größeren Anteil der Nutzung ausmachte. Die technischen Herausforderungen der Videogenerierung führten auch zu Innovationen in FALs Infrastruktur – Videomodelle benötigten andere Optimierungsstrategien als Bildmodelle und neue Custom-Kernels sowie Architekturansätze. Der Erfolg in der Videogenerierung bestätigte FALs Strategie, eine Plattform für mehrere Modalitäten zu bauen: Nicht nur Bildgenerierung, sondern eine Infrastruktur, die flexibel Bild-, Video- und Audiomodelle bedienen kann – und sich so als umfassende Plattform für generative Medien positioniert.
Da generative Medien immer zentraler für Content Creation und Anwendungsentwicklung werden, helfen Plattformen wie FlowHunt Entwicklern und Teams dabei, die Komplexität der Integration in ihre Workflows zu meistern. FlowHunt erkennt, dass Plattformen wie FAL zwar die Infrastruktur-Herausforderung der effizienten Modellbereitstellung gelöst haben, Entwickler aber weiterhin mit der Orchestrierung dieser Modelle im größeren Anwendungsworkflow kämpfen. Eine typische Anwendung umfasst mehrere Schritte: Nutzeranfragen entgegennehmen, Eingaben prüfen und verarbeiten, eines oder mehrere generative Modelle ansprechen, Ergebnisse nachbearbeiten, Ausgaben speichern und Analysen verwalten. FlowHunt stellt Werkzeuge bereit, um diese Workflows zu automatisieren und zu optimieren, sodass sich Entwickler auf die eigentliche Anwendungslogik konzentrieren können. Durch die Integration mit Plattformen wie FAL ermöglicht FlowHunt den Bau anspruchsvoller generativer Medienanwendungen, ohne dass Entwickler sich um die darunterliegende Infrastruktur für Model Serving, Optimierung und Skalierung kümmern müssen.
FlowHunts Ansatz für generative Medienworkflows setzt auf Automatisierung, Zuverlässigkeit und Transparenz. Die Plattform erlaubt Entwicklern, Workflows zu definieren, die mehrere generative Medienoperationen verketten, Fehler elegant abfangen und Einblick in jeden Schritt bieten. Ein Content-Workflow könnte beispielsweise mehrere Bildvarianten generieren, anhand von Qualitätsmetriken die beste auswählen, Nachbearbeitungseffekte anwenden und das Resultat veröffentlichen. FlowHunt macht es möglich, den gesamten Prozess deklarativ zu beschreiben, mit automatischer Wiederholung bei Fehlern, Fehlerbehandlung und Monitoring. Diese Abstraktionsebene ist besonders für Teams mit Produktionsanwendungen wertvoll, die zuverlässig Inhalte in großem Maßstab erzeugen wollen. Mit Orchestrierung und Workflow-Management im Hintergrund können sich Entwickler auf Kreativität und Business-Logik konzentrieren, während die Plattform die technische Komplexität der Koordination mehrerer generativer Medienoperationen übernimmt.
Das enorme Wachstum von FAL und die Servicequalität beruhen auf einer Basis hochentwickelter technischer Optimierung, die die meisten Nutzer nie zu Gesicht bekommen. Die Plattform entwickelte über 100 eigene CUDA-Kernels – spezialisierter GPU-Code in NVIDIAs CUDA-Sprache –, der gezielt bestimmte Operationen innerhalb generativer Medienmodelle beschleunigt. Diese Kernels spiegeln tausende Stunden Ingenieursarbeit wider, die darauf abzielt, die maximale Leistung aus GPU-Hardware herauszuholen. Die Motivation ist klar: Jede Millisekunde Latenzreduzierung verbessert die Nutzererfahrung und senkt die Infrastrukturkosten. Ein Modell, das ein Bild 20 % schneller generiert, ermöglicht es derselben GPU, 20 % mehr Nutzer zu bedienen – das verbessert die Ökonomie direkt. Die Entwicklung eigener Kernels ist anspruchsvoll: CUDA-Programmierung erfordert tiefes Verständnis von GPU-Architektur, Speicherhierarchien und Parallelisierung. Sie lässt sich nicht einfach erlernen oder generisch anwenden – jeder Kernel muss für bestimmte Operationen und Hardwarekonfigurationen fein abgestimmt werden.
Die Optimierung beginnt mit Profiling – dem präzisen Erfassen, wo im Modelleinsatz wirklich Zeit verloren geht. Viele Entwickler vermuten, dass die rechenintensivsten Operationen die Engpässe sind, doch Profiling zeigt oft Überraschendes: Manchmal ist es der Datentransfer zwischen GPU-Speicher und Recheneinheiten, nicht die Berechnung selbst. Oder der Overhead durch viele kleine GPU-Operationen statt gebündeltem Batching. FALs Ingenieure analysieren Modelle tiefgehend, identifizieren die tatsächlichen Bottlenecks und entwickeln dann eigene Kernels, um diese gezielt zu beseitigen. Beispielsweise kann ein Kernel mehrere Operationen verschmelzen, um Speicherzugriffe und Overhead zu minimieren, oder speziell für bestimmte Dimensionsgrößen und Datentypen eines Modells optimiert sein. Dieser Aufwand lohnt sich wirtschaftlich nur bei Millionen Nutzern – die Investition in Kernel-Entwicklung rechnet sich durch gesteigerte Effizienz und niedrigere Infrastrukturkosten.
Über die Einzeloptimierung hinaus investierte FAL auch in Architekturverbesserungen beim Model Serving. Die Plattform nutzt Techniken wie Quantisierung (Reduzierung der Modellpräzision und damit Speicher- und Rechenbedarf), dynamisches Batching (Gruppierung von Anfragen zur besseren GPU-Auslastung) und Priorisierung (Latenz-sensitive Anfragen werden bevorzugt behandelt). Diese Methoden müssen sorgfältig implementiert werden, um die Qualität zu erhalten und trotzdem Effizienzgewinne zu erzielen. Quantisierung kann beispielsweise Modellgröße und Geschwindigkeit verbessern, mindert bei falscher Anwendung aber die Ausgabequalität. FALs Ingenieure entwickelten daher ausgefeilte Quantisierungsstrategien, die Qualität und Effizienz vereinen. Dynamisches Batching erfordert die Prognose der Laufzeit einzelner Anfragen und deren Gruppierung zur optimalen GPU-Auslastung, ohne zu hohe Latenz zu riskieren. Zusammengenommen ermöglichen diese Architekturverbesserungen und Custom-Kernel-Optimierungen FAL eine Auslastung und Performance, wie sie mit generischer Infrastruktur unerreichbar wären.
Der Markt für generative Medien entwickelt sich rasant, ständig entstehen neue Modelle und Fähigkeiten. Die Wettbewerbsdynamik und Marktstruktur zu verstehen, ist entscheidend, um die Bedeutung spezialisierter Plattformen wie FAL zu erkennen. Der Markt lässt sich grob in Segmente teilen: Bildgenerierung, Videogenerierung, Audiogenerierung und Bearbeitungs-/Manipulationswerkzeuge. Innerhalb jedes Segments konkurrieren verschiedene Modelle hinsichtlich Qualität, Geschwindigkeit, Kosten und spezifischer Fähigkeiten. Im Bereich Bildgenerierung umfasst der Markt Stable-Diffusion-Varianten, Flux-Modelle, Googles Gemini Image-Modelle und spezialisierte Modelle etwa für Logos oder Gesichtssynthese. Bei Video konkurrieren Veo3, Alibaba One, Kuaishou Kling und andere. Diese Modellvielfalt bietet Chancen und Herausforderungen für Infrastrukturanbieter. Die Chance: Kein Modell dominiert alle Anwendungsfälle – eine Plattform, die mehrere Modelle bedienen kann, wird umso wertvoller. Die Herausforderung: Für viele Modelle sind erhebliche Optimierungsaufwände nötig.
FAL verfolgt eine kuratierte Auswahl an Modellen, die zusammen die wichtigsten Anwendungsfälle abdecken und hohe Qualitätsstandards sichern. Statt jedes neue Modell sofort hinzuzufügen, prüft FAL sorgfältig, ob es einzigartige Fähigkeiten bietet oder bestehende Optionen deutlich übertrifft. Das hat mehrere Vorteile: Die Modellpalette bleibt qualitativ hochwertig und übersichtlich, Ressourcen können gezielt für tatsächlich genutzte Modelle eingesetzt werden und die Plattform gewinnt einen Ruf als Qualitätsanbieter, was wiederum Entwickler und Modellanbieter anzieht. Modellautoren möchten ihre Modelle auf FAL bringen, weil sie wissen, dass die Nutzer Wert auf Qualität legen. Nutzer kommen zu FAL, weil sie wissen, dass die Modelle sorgfältig ausgewählt und optimiert sind. Dieser positive Kreislauf war entscheidend für FALs Erfolg.
Zur Wettbewerbslandschaft gehören auch andere Infrastrukturplattformen für generative Medien sowie Konkurrenz von Modellanbietern, die eigenes Hosting betreiben. Einige Anbieter wie Stability AI betreiben eigene Inferenz-APIs. Andere, wie Black Forest Labs mit Flux, arbeiten mit Plattformen wie FAL zusammen statt selbst Infrastruktur zu bauen. Die Entscheidung zwischen Partnerschaft und Eigenbetrieb ist strategisch: Der Aufbau eigener Infrastruktur bindet erhebliche Ressourcen, Partnerschaften ermöglichen die Konzentration auf Modellentwicklung. Für die meisten Modellanbieter ist die Zusammenarbeit mit spezialisierten Plattformen wie FAL sinnvoller. So entsteht ein gesundes Ökosystem, in dem sich Modellanbieter auf Forschung und Entwicklung, Infrastrukturanbieter auf Optimierung und Skalierung konzentrieren.
Das Verständnis des Geschäftsmodells und der Metriken von FAL zeigt, wie generative Medieninfrastruktur Wert schafft und skaliert. FAL setzt auf nutzungsbasierte Abrechnung – Kunden zahlen nach Anzahl der API-Aufrufe und genutzter Rechenleistung. Das schafft passende Anreize: Kunden zahlen mehr bei häufiger Nutzung, und FALs Umsatz wächst mit dem Nutzen der Plattform. Die Wachstumszahlen sind beeindruckend: 2 Millionen Entwickler, über 350 verfügbare Modelle, über 100 Millionen Dollar Jahresumsatz. Das zeigt beachtliche Skalierung, verdeutlicht aber auch, dass der Markt noch früh ist. Die Durchdringung ist noch gering, viele Anwendungsfälle werden gerade erst erschlossen. Das Umsatzwachstum beschleunigte sich weiter mit der Einführung von Videogenerierung: Der Umsatz sprang nach Veröffentlichung von Flux in einem Monat von 2 auf 10 Millionen Dollar, was die enorme Wirkung hochwertiger Modelle auf den Plattformumsatz zeigt.
Auch die Geschäftsmetriken offenbaren wichtige Markteinblicke. Dass FAL mit 2 Millionen Entwicklern und über 100 Millionen Dollar Umsatz einen durchschnittlichen Umsatz von grob 50–100 Dollar pro Nutzer/Jahr erzielt, liegt daran, dass viele Nutzer die Technologie testen oder in kleinem Maßstab einsetzen. Die Verteilung dürfte jedoch stark asymmetrisch sein – einige Power-User, meist Unternehmen, generieren einen Großteil des Umsatzes. Mit der weiteren Marktetablierung und Integration generativer Medien in zentrale Geschäftsprozesse wird der durchschnittliche Umsatz pro Nutzer voraussichtlich deutlich steigen. Das Wachstum deutet darauf hin, dass sich generative Medieninfrastruktur noch am Anfang einer langanhaltenden Wachstumskurve befindet, mit großem Potenzial für die Zukunft.
Eine der wichtigsten Entwicklungen im Markt für generative Medien ist die Entstehung von Feinabstimmung und Anpassungsmöglichkeiten, mit denen Nutzer Modelle auf spezielle Anwendungsfälle zuschneiden. Feinabstimmung bedeutet, ein vortrainiertes Modell mit domänenspezifischen Daten weiter zu trainieren, um für bestimmte Aufgaben bessere Ergebnisse zu erzielen. Im Bereich Bildgenerierung sind das vor allem LoRAs (Low-Rank Adaptations) – leichtgewichtige Modellvarianten, die das Basismodell für spezielle Zwecke individualisieren, ohne ein vollständiges Re-Training zu benötigen. Ein Designer kann etwa eine LoRA erstellen, die einen bestimmten Kunststil abbildet, ein Fotograf seinen persönlichen Stil, ein Unternehmen LoRAs für die Darstellung eigener Produkte in spezifischen Kontexten. Das LoRA-Ökosystem ist zu einem entscheidenden Bestandteil des Marktes geworden, mit tausenden verfügbaren LoRAs für Modelle wie Stable Diffusion und SDXL.
Die Entwicklung der Feinabstimmung hat große Auswirkungen auf Infrastrukturanbieter wie FAL. Die Unterstützung von Feinabstimmungen erfordert zusätzliche Fähigkeiten – nicht nur das Bereitstellen von Basismodellen. Die Plattform muss Werkzeuge bieten, mit denen Nutzer LoRAs erstellen und verwalten, sie effizient speichern und gemeinsam mit den Basismodellen bereitstellen können. Sie muss die technische Herausforderung meistern, LoRAs zur Laufzeit mit Basismodellen zu kombinieren, sodass hochwertige Ergebnisse ohne übermäßige Latenz entstehen. FAL hat hier gezielt investiert und erkannt, dass Feinabstimmung für viele Nutzer ein zentraler Mehrwert ist. Die Unterstützung für Feinabstimmung war ein entscheidender Erfolgsfaktor und erlaubt es Nutzern, Modelle individuell anzupassen und trotzdem von Optimierung und Skalierung der Plattform zu profitieren. Mit zunehmender Marktreife werden Feinabstimmung und Individualisierung noch wichtiger, da Unternehmen maßgeschneiderte Modelle für spezielle Anwendungsfälle entwickeln.
Mit Blick in die Zukunft wird sich der Markt für generative Medieninfrastruktur weiterhin rasant entwickeln. Mehrere Trends werden das Marktgeschehen prägen: Erstens werden die Modelle immer besser, erschließen neue Anwendungsfälle und ziehen zusätzliche Nutzer an. Die Videogenerierung steckt noch in den Anfängen – mit steigender Modellqualität wird Video so allgegenwärtig wie Bildgenerierung. Audiogenerierung und Musikproduktion werden neue Felder, Modelle wie PlayHD und andere zeigen hier Potenzial. Zweitens wird sich der Markt wahrscheinlich um wenige dominante Modelle und Plattformen konsolidieren, ähnlich wie sich im Bereich Bildgenerierung Stable-Diffusion-Varianten und Flux durchgesetzt haben. Diese Konsolidierung eröffnet spezialisierten Plattformen Chancen, da sie für die führenden Modelle optimieren. Drittens werden generative Medien zunehmend in Mainstream-Anwendungen und Workflows integriert. Künftig wird generative Medienerzeugung kein isoliertes Feature sein, sondern fester Bestandteil von Design-Tools, Content-Management-Systemen und anderen Anwendungen im Alltag von Kreativen.
Auch die Infrastruktur-Anforderungen entwickeln sich weiter. Mit wachsender Modellgröße und -fähigkeit steigt der Rechenbedarf, was die Nachfrage nach effizienter Inferenzoptimierung antreibt. Neue Hardware-Beschleuniger abseits von GPUs – etwa spezialisierte KI-Chips verschiedener Hersteller – eröffnen neue Optimierungschancen und Herausforderungen. Plattformen, die Modelle effizient auf diverser Hardware betreiben können, werden einen großen Vorteil haben. Zudem werden Zuverlässigkeit, Latenz und Kosteneffizienz immer wichtiger, je zentraler generative Medien für Geschäftsprozesse werden. Während Early Adopters noch gelegentliche Fehler oder hohe Latenz akzeptierten, werden künftig höhere Zuverlässigkeit und niedrigere Latenz gefordert. Das wird zu weiteren Investitionen in Infrastruktur- und Zuverlässigkeitsoptimierung führen.
Die technische Geschichte der generativen Medien zeigt, wie sich der Markt in nur wenigen Jahren von experimenteller Forschung zu einer Milliarden-Infrastruktur entwickelt hat. Der Weg von Stable Diffusion 1.5 bis zu modernen Videogenerierungsmodellen verdeutlicht, wie rasante Innovation bei KI-Modellen Chancen für spezialisierte Infrastrukturplattformen schafft. Der Erfolg von FAL, ein Geschäft mit über 100 Millionen Dollar Umsatz allein durch generative Medieninfrastruktur aufzubauen – statt im überfüllten Sprachmodellmarkt zu konkurrieren –, unterstreicht die Bedeutung strategischer Marktpositionierung und technischer Spezialisierung. Die Investition in eigene CUDA-Kernel, Multi-Modalität und die sorgfältige Auswahl hochwertiger Modelle hat eine wertvolle Dienstleistung geschaffen, auf die Millionen Entwickler setzen. Mit der weiteren Entwicklung generativer Medien und ihrer zunehmenden Bedeutung für Content Creation und Anwendungsentwicklung werden die Infrastrukturplattformen für diesen Markt immer wichtiger. Die Kombination aus besseren Modellen, wachsenden Anwendungsfällen und zunehmender Geschäftsnutzung zeigt, dass generative Medieninfrastruktur noch am Anfang einer langanhaltenden Wachstumsphase steht – mit großem Potenzial für Plattformen, die zuverlässige, effiziente und innovative Dienste bieten.
{{ cta-dark-panel heading=“Beschleunigen Sie Ihre Workflows mit FlowHunt” description=“Erleben Sie, wie FlowHunt Ihre KI-Content- und SEO-Workflows automatisiert – von Recherche und Inhaltserstellung bis hin zu Veröffentlichung und Analyse – alles an einem Ort.” ctaPrimaryText=“Demo buchen” ctaPrimaryURL=“https://calendly.com/liveagentsession/flowhunt-chatbot-demo" ctaSecondaryText=“FlowHunt kostenlos testen” ctaSecondaryURL=“https://app.flowhunt.io/sign-in" gradientStartColor="#123456” gradientEndColor="#654321” gradientId=“827591b1-ce8c-4110-b064-7cb85a0b1217” }}
Generative Medien bezeichnen KI-Systeme, die Bilder, Videos und Audioinhalte erzeugen. Im Gegensatz zu Sprachmodellen, die mit Suchmaschinen und großen Tech-Unternehmen konkurrieren, stellen generative Medien ein neues Marktsegment mit eigenen technischen Anforderungen an Inferenzoptimierung und Multi-Tenant-Skalierung dar.
FAL erkannte, dass das Hosting von Sprachmodellen einen Wettbewerb mit OpenAI, Anthropic und Google bedeuten würde – Unternehmen mit enormen Ressourcen. Generative Medien waren ein schnell wachsendes Nischenmarktsegment ohne etablierte Konkurrenz, wodurch FAL den Markt definieren und eine Führungsrolle in der Inferenzoptimierung für Bild-, Video- und Audiomodelle übernehmen konnte.
Stable Diffusion 1.5 war für FAL ein bedeutender Wendepunkt. Es zeigte, dass Entwickler optimierte, API-bereite Inferenz benötigten, anstatt eigene Deployments zu verwalten. Diese Erkenntnis führte dazu, dass FAL sich von einer allgemeinen Python-Laufzeitumgebung zu einer spezialisierten generativen Medienplattform wandelte.
Flux-Modelle, veröffentlicht von Black Forest Labs, waren die ersten, die eine 'kommerziell nutzbare, unternehmensreife' Qualität erreichten. Sie steigerten FALs Umsatz im ersten Monat von 2 auf 10 Millionen Dollar und im folgenden Monat auf 20 Millionen Dollar und etablierten generative Medien als einen wirtschaftlich tragfähigen Markt.
FAL hat über 100 eigene CUDA-Kernels entwickelt, um die Inferenzleistung für verschiedene Modelle zu optimieren. Diese Kernels ermöglichen schnellere Generierungszeiten, bessere GPU-Auslastung und Multi-Tenant-Skalierung – entscheidende Faktoren für die effiziente Bereitstellung für 2 Millionen Entwickler und über 350 Modelle.
Die Videogenerierung, insbesondere mit Modellen wie Veo3, hat ein völlig neues Marktsegment geschaffen. Frühe Text-zu-Video-Modelle produzierten qualitativ minderwertige, tonlose Inhalte. Moderne Modelle mit Ton, korrektem Timing und Lippen-Synchronisation haben die Videogenerierung wirtschaftlich nutzbar gemacht und neue Anwendungsfälle in Werbung und Content Creation eröffnet.
Arshia ist eine AI Workflow Engineerin bei FlowHunt. Mit einem Hintergrund in Informatik und einer Leidenschaft für KI spezialisiert sie sich darauf, effiziente Arbeitsabläufe zu entwickeln, die KI-Tools in alltägliche Aufgaben integrieren und so Produktivität und Kreativität steigern.

Entdecken Sie, wie FlowHunt die KI-Inhaltserstellung von der Modellauswahl bis zur Bereitstellung und Optimierung vereinfacht.
Ein Generatives Gegnerisches Netzwerk (GAN) ist ein maschinelles Lern-Framework mit zwei neuronalen Netzwerken – einem Generator und einem Diskriminator –, die ...
Erfahren Sie alles, was Sie über die Sora-2 App wissen müssen – ihre Funktionen, Anwendungsfälle und wie sie im Vergleich zu führenden KI-Videogeneratoren absch...

Erfahren Sie, wie Sie Ihre Inhalte für KI-Anbieter wie ChatGPT und Perplexity optimieren. Meistern Sie Generative Engine Optimization (GEO), um sicherzustellen,...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.