Großes Sprachmodell (LLM)
Ein Großes Sprachmodell (LLM) ist eine KI, die auf riesigen Textmengen trainiert wurde, um menschliche Sprache zu verstehen, zu generieren und zu verarbeiten. L...
8 Min. Lesezeit
AI
Large Language Model
+4

FlowHunt testet und bewertet führende LLMs – darunter GPT-4, Claude 3, Llama 3 und Grok – für die Content-Erstellung, indem Lesbarkeit, Ton, Originalität und Keyword-Nutzung bewertet werden, um Ihnen die Wahl des besten Modells für Ihre Bedürfnisse zu erleichtern.
Large Language Models (LLMs) sind modernste KI-Tools, die die Art und Weise, wie wir Inhalte erstellen und konsumieren, grundlegend verändern. Bevor wir uns näher mit den Unterschieden der einzelnen LLMs beschäftigen, sollten Sie verstehen, was diese Modelle befähigt, so mühelos menschenähnlichen Text zu generieren.
LLMs werden mit riesigen Datensätzen trainiert, was ihnen hilft, Kontext, Semantik und Syntax zu erfassen. Durch die Menge an Daten können sie das nächste Wort in einem Satz korrekt vorhersagen und die Wörter zu verständlichen Texten zusammensetzen. Ein Grund für ihre Effektivität ist die Transformer-Architektur. Dieser Self-Attention-Mechanismus nutzt neuronale Netze zur Verarbeitung von Syntax und Semantik. Dadurch können LLMs mühelos eine Vielzahl komplexer Aufgaben bewältigen.
Large Language Models (LLMs) haben die Herangehensweise von Unternehmen an die Content-Erstellung grundlegend verändert. Dank ihrer Fähigkeit, personalisierte und optimierte Texte zu erzeugen, generieren LLMs Inhalte wie E-Mails, Landingpages und Social-Media-Posts anhand von menschlichen Spracheingaben.
Damit helfen LLMs Content-Erstellern bei:
Auch die Zukunft von LLMs ist vielversprechend: Technologische Fortschritte werden ihre Genauigkeit und multimodalen Fähigkeiten weiter verbessern. Die Ausweitung der Einsatzmöglichkeiten wird viele Branchen beeinflussen.
Starten Sie heute Ihre kostenlose Testversion und sehen Sie innerhalb weniger Tage Ergebnisse.
Hier ein kurzer Überblick über die populären LLMs, die wir testen werden:
| Modell | Einzigartige Stärken |
|---|---|
| GPT-4 | Vielseitig in verschiedenen Schreibstilen |
| Claude 3 | Hervorragend bei kreativen und kontextuellen Aufgaben |
| Llama 3.2 | Bekannt für effiziente Textzusammenfassungen |
| Grok | Fokussiert auf einen entspannten und humorvollen Ton |
Bei der Auswahl eines LLMs ist es entscheidend, Ihre Anforderungen an die Content-Erstellung zu berücksichtigen. Jedes Modell bietet etwas Eigenes – von der Bewältigung komplexer Aufgaben bis zur Generierung KI-basierter kreativer Inhalte. Bevor wir sie testen, fassen wir sie kurz zusammen, um zu zeigen, wie sie Ihren Content-Prozess bereichern können.
Hauptfunktionen:
Leistungsdaten:
Stärken:
Herausforderungen:
Insgesamt ist GPT-4 ein leistungsstarkes Tool für Unternehmen, die ihre Content- und Datenanalyse-Strategie verbessern wollen.
Hauptfunktionen:
Stärken:
Herausforderungen:
Hauptfunktionen:
Stärken:
Herausforderungen:
Llama 3 überzeugt als robustes und vielseitiges Open-Source-LLM, verspricht Fortschritte in der KI, stellt Nutzer aber auch vor gewisse Herausforderungen.
Hauptfunktionen:
Stärken:
Herausforderungen:
Zusammengefasst bietet xAI Grok interessante Features und profitiert von Medienpräsenz, steht in Popularität und Leistung jedoch vor großen Herausforderungen im Vergleich zu anderen Sprachmodellen.
Kommen wir direkt zum Test: Wir bewerten die Modelle anhand einer einfachen Blogartikel-Ausgabe. Alle Tests wurden in FlowHunt durchgeführt, lediglich das LLM-Modell wurde gewechselt.
Wichtige Bewertungskriterien:
Test-Prompt:
Schreiben Sie einen Blogpost mit dem Titel “10 einfache Wege, nachhaltig zu leben, ohne das Budget zu sprengen.” Der Ton soll praktisch und zugänglich sein, mit Fokus auf umsetzbare Tipps, die für viel beschäftigte Menschen realistisch sind. Heben Sie “Nachhaltigkeit mit kleinem Budget” als Haupt-Keyword hervor. Fügen Sie Beispiele aus Alltagssituationen wie Lebensmitteleinkauf, Energieverbrauch und persönliche Gewohnheiten ein. Schließen Sie mit einem motivierenden Aufruf, heute mit einem Tipp zu starten.
Hinweis: Der Flow ist so eingestellt, dass die Ausgaben etwa 500 Wörter umfassen. Falls die Ergebnisse gehetzt wirken oder nicht in die Tiefe gehen, ist das beabsichtigt.
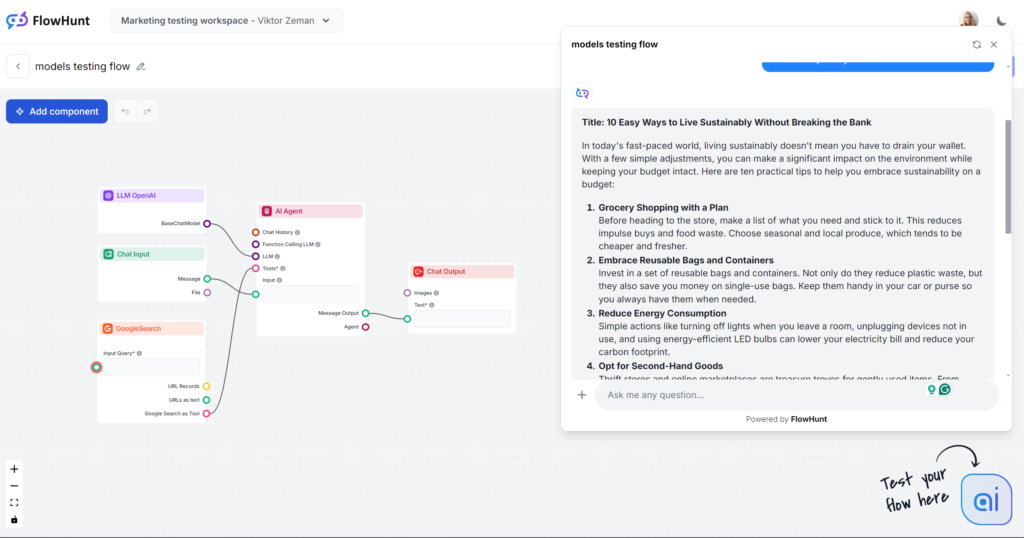
Wäre dies ein Blindtest, würde der Einstieg „In der heutigen schnelllebigen Welt …“ sofort verraten, welches Modell es ist. Sie sind mit diesem Schreibstil wahrscheinlich vertraut, denn GPT-4o ist nicht nur die beliebteste Wahl, sondern auch das Herzstück der meisten Drittanbieter-KI-Schreibtools. GPT-4o ist immer eine sichere Wahl für allgemeine Inhalte, aber rechnen Sie mit Unschärfe und Weitschweifigkeit.
Ton und Sprache
Abgesehen vom abgenutzten Einstiegssatz erfüllte GPT-4o exakt die Erwartungen. Es wäre schwer, dies als menschlichen Text auszugeben, aber dennoch ist der Artikel gut strukturiert und folgt eindeutig dem Prompt. Der Ton ist tatsächlich praktisch und zugänglich und konzentriert sich direkt auf umsetzbare Tipps statt auf vage Umschreibungen.
Keyword-Nutzung
Beim Keyword-Test schnitt GPT-4o gut ab. Es wurde nicht nur das Haupt-Keyword korrekt verwendet, sondern auch ähnliche Formulierungen und andere passende Schlüsselwörter.
Lesbarkeit
Auf der Flesch-Kincaid-Skala liegt das Ergebnis bei der 10.-12. Klasse (ziemlich schwierig) mit einem Wert von 51,2. Ein Punkt weniger, und es wäre auf College-Niveau. Bei so kurzem Output hat das Keyword „Nachhaltigkeit“ vermutlich einen spürbaren Einfluss auf die Lesbarkeit. Trotzdem bleibt deutlich Verbesserungspotenzial.
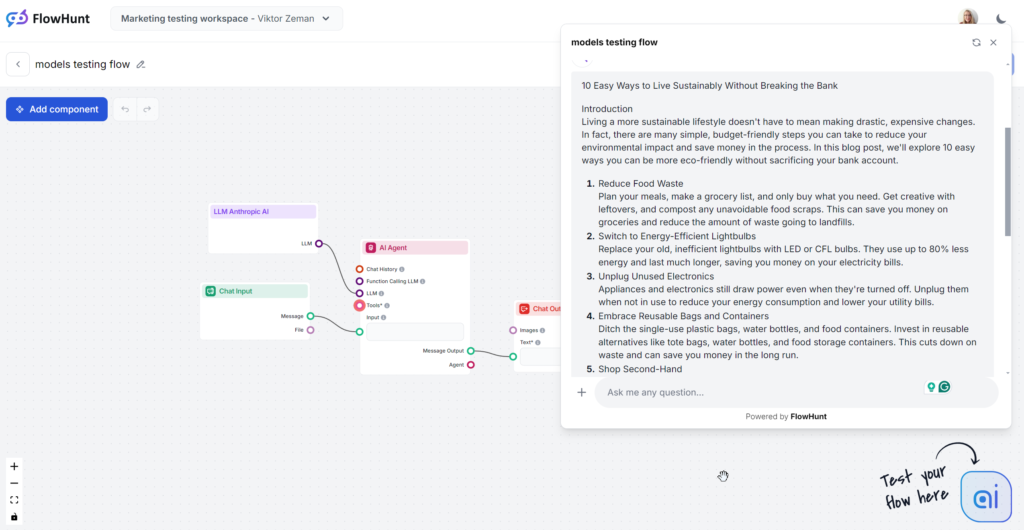
Das getestete Claude-Modell ist die mittlere Sonnet-Variante, die als beste Option für Content gilt. Der Text liest sich gut und wirkt spürbar menschlicher als GPT-4o oder Llama. Claude ist die perfekte Lösung für saubere, einfache Inhalte, die Informationen effizient vermitteln – ohne zu weitschweifig wie GPT oder zu extravagant wie Grok zu sein.
Ton und Sprache
Claude überzeugt durch einfache, nachvollziehbare und menschlich wirkende Antworten. Der Ton ist praktisch und zugänglich und konzentriert sich direkt auf umsetzbare Tipps statt auf vage Umschreibungen.
Keyword-Nutzung
Claude war das einzige Modell, das den Keyword-Teil des Prompts ignorierte – es tauchte nur in 1 von 3 Ausgaben auf. Wenn das Keyword verwendet wurde, dann nur im Fazit – und wirkte dort etwas erzwungen.
Lesbarkeit
Claude Sonnet erreichte auf der Flesch-Kincaid-Skala die 8. bis 9. Klasse (Plain English) – nur wenige Punkte hinter Grok. Während Grok den gesamten Ton und Wortschatz entsprechend anpasste, nutzte Claude eine dem GPT-4o ähnliche Sprache. Was die Lesbarkeit so hoch machte? Kürzere Sätze, Alltagswörter und keine vagen Inhalte.
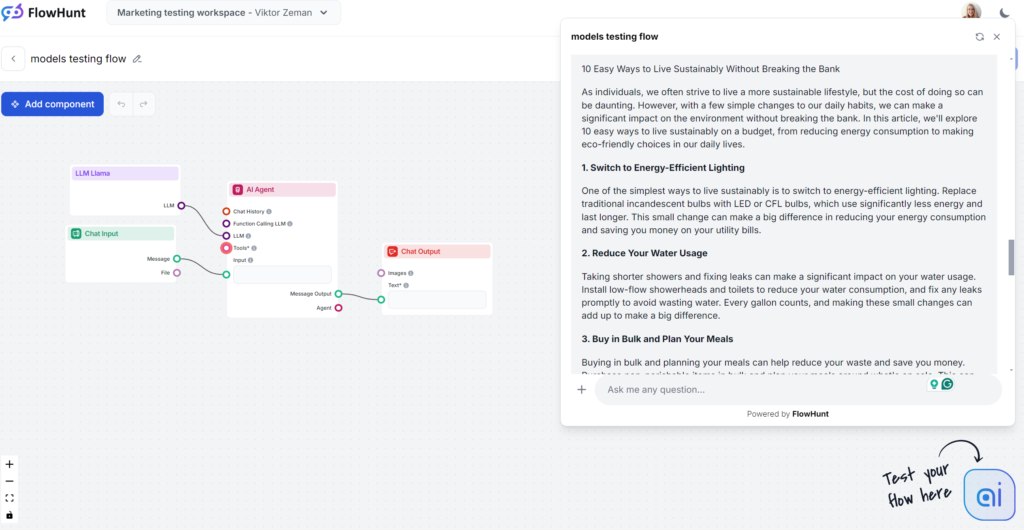
Llamas größte Stärke war die Keyword-Nutzung. Der Schreibstil war dagegen wenig inspiriert und etwas weitschweifig – aber immer noch weniger langweilig als GPT-4o. Llama ist wie der Cousin von GPT-4o: eine sichere Content-Wahl mit etwas wortreicherem, vagerem Stil. Ideal, wenn Sie grundsätzlich die Schreibweise von OpenAI mögen, aber auf klassische GPT-Phrasen verzichten wollen.
Ton und Sprache
Llama-Texte ähneln stark denen von GPT-4o. Die Weitschweifigkeit und Unschärfe sind vergleichbar, aber der Ton ist praktisch und zugänglich.
Keyword-Nutzung
Meta ist der Sieger beim Keyword-Test. Llama verwendete das Keyword mehrfach, unter anderem in der Einleitung, und integrierte natürlich ähnliche Begriffe.
Lesbarkeit
Auf der Flesch-Kincaid-Skala liegt das Ergebnis bei der 10.-12. Klasse (ziemlich schwierig), mit 53,4 Punkten – nur leicht besser als GPT-4o (51,2). Das kurze Output und das Keyword „Nachhaltigkeit“ beeinflussen die Lesbarkeit spürbar. Dennoch gibt es Verbesserungspotenzial.
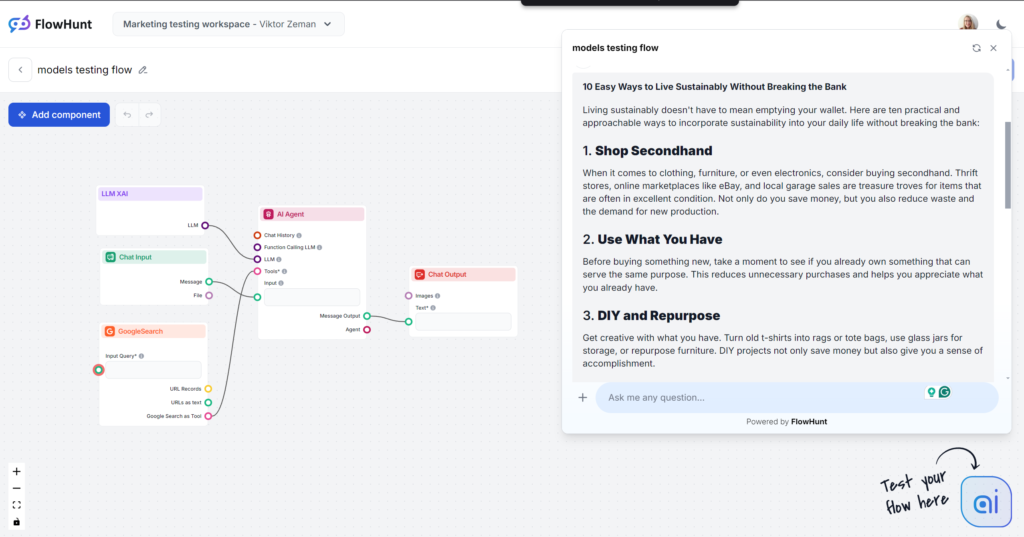
Grok war eine große Überraschung, vor allem in Ton und Sprache. Mit einem sehr natürlichen, entspannten Ton fühlt es sich an, als bekäme man schnelle Tipps von einem guten Freund. Wenn Ihnen ein lockerer, flotter Schreibstil liegt, ist Grok definitiv die beste Wahl.
Ton und Sprache
Der Output liest sich sehr gut. Die Sprache ist natürlich, die Sätze sind prägnant, und Grok verwendet Redewendungen gekonnt. Das Modell bleibt seinem Haupt-Ton treu und geht beim menschlich wirkenden Text neue Wege. Hinweis: Groks entspannter Ton ist nicht immer die beste Wahl für B2B- und SEO-getriebene Inhalte.
Keyword-Nutzung
Grok nutzte das gewünschte Keyword, allerdings nur im Fazit. Andere Modelle platzierten Keywords besser und ergänzten weitere relevante Begriffe, während Grok mehr Wert auf den Sprachfluss legte.
Lesbarkeit
Mit der lockeren Sprache bestand Grok den Flesch-Kincaid-Test mit Bravour: 61,4 Punkte entsprechen der 7.-8. Klasse (Plain English). Damit werden Themen optimal für die Allgemeinheit zugänglich gemacht. Dieser Lesbarkeits-Sprung ist fast greifbar.
Erhalten Sie die neuesten Tipps, Trends und Angebote kostenlos.
Die Leistungsfähigkeit von LLMs hängt entscheidend von der Qualität der Trainingsdaten ab, die manchmal voreingenommen oder ungenau sein können – was zur Verbreitung von Fehlinformationen führt. Es ist daher essenziell, KI-generierte Inhalte auf Fairness und Inklusivität zu prüfen. Beim Experimentieren mit verschiedenen Modellen sollten Sie bedenken, dass jedes Modell unterschiedlich mit Datenschutz und der Begrenzung schädlicher Ausgaben umgeht.
Um einen ethischen Einsatz zu gewährleisten, sollten Unternehmen Rahmenbedingungen für Datenschutz, Vorurteilsminimierung und Inhaltsmoderation schaffen. Dazu gehört der regelmäßige Austausch zwischen KI-Entwicklern, Autoren und Rechtsexperten. Zu den wichtigsten ethischen Überlegungen zählen:
Die Auswahl des LLMs sollte ethisch mit den Content-Richtlinien des Unternehmens übereinstimmen. Sowohl Open-Source- als auch proprietäre Modelle sollten auf potenziellen Missbrauch geprüft werden.
Verzerrungen, Ungenauigkeiten und Halluzinationen bleiben große Herausforderungen bei KI-generierten Inhalten. Durch eingebaute Richtlinien entstehen oft vage, wenig wertvolle Outputs. Unternehmen benötigen zusätzliche Trainings- und Sicherheitsmaßnahmen, um diese Probleme zu adressieren. Für kleine Unternehmen sind Zeit und Ressourcen für individuelles Training meist nicht verfügbar. Eine Alternative ist der Einsatz allgemeiner Modelle über Drittanbieter-Tools wie FlowHunt.
FlowHunt ermöglicht es, klassischen Basismodellen spezifisches Wissen, Internetzugang und neue Fähigkeiten zu geben. So können Sie das passende Modell für die jeweilige Aufgabe wählen, ohne sich durch Limitierungen oder zahlreiche Abos einschränken zu lassen.
Ein weiteres großes Problem ist die Komplexität der Modelle: Mit Milliarden von Parametern sind sie schwer zu steuern, zu verstehen und zu debuggen. FlowHunt gibt Ihnen wesentlich mehr Kontrolle als reine Chat-Prompts. Sie können einzelne Fähigkeiten als Blöcke hinzufügen und anpassen, um Ihre Bibliothek einsatzbereiter KI-Tools zu erstellen.
Die Zukunft von Sprachmodellen (LLMs) in der Content-Erstellung ist vielversprechend und spannend. Mit fortschreitender Entwicklung versprechen diese Modelle größere Genauigkeit und weniger Verzerrung bei der Inhaltserzeugung. Das bedeutet, Autoren können mit KI-Unterstützung zuverlässige, menschenähnliche Texte erstellen.
LLMs werden künftig nicht nur Text, sondern auch multimodale Inhalte meistern: Sie kombinieren Text und Bilder und stärken so die kreative Content-Erstellung in verschiedensten Branchen. Mit größeren, besser gefilterten Datensätzen werden LLMs verlässlichere Inhalte liefern und den Schreibstil weiter verfeinern.
Aber aktuell können LLMs das noch nicht eigenständig – diese Fähigkeiten sind auf verschiedene Unternehmen und Modelle verteilt, die jeweils um Ihre Aufmerksamkeit und Ihr Budget konkurrieren. FlowHunt vereint sie alle und ermöglicht
GPT-4 ist das beliebteste und vielseitigste Modell für allgemeine Inhalte, aber Metas Llama bietet einen frischeren Schreibstil. Claude 3 ist am besten für saubere, einfache Inhalte geeignet, während Grok sich durch einen entspannten, menschlichen Ton auszeichnet. Die beste Wahl hängt von Ihren Content-Zielen und Stilvorlieben ab.
Berücksichtigen Sie Lesbarkeit, Ton, Originalität, Keyword-Nutzung und wie jedes Modell zu Ihren Content-Anforderungen passt. Bewerten Sie auch Stärken wie Kreativität, Genre-Vielfalt oder Integrationspotenzial und achten Sie auf Herausforderungen wie Verzerrung, Weitschweifigkeit oder Ressourcenbedarf.
FlowHunt ermöglicht es Ihnen, mehrere führende LLMs in einer Umgebung zu testen und zu vergleichen. Sie behalten die Kontrolle über die Ausgaben und können das beste Modell für Ihren spezifischen Content-Workflow finden – ohne mehrere Abonnements.
Ja. LLMs können Vorurteile verstärken, Fehlinformationen generieren und Datenschutzbedenken aufwerfen. Es ist wichtig, KI-Ausgaben zu überprüfen, Modelle auf ethische Ausrichtung zu bewerten und Rahmenbedingungen für einen verantwortungsvollen Einsatz zu schaffen.
Künftige LLMs werden eine verbesserte Genauigkeit, weniger Verzerrungen und multimodale Content-Generierung (Text, Bilder usw.) bieten, sodass Autoren zuverlässigere und kreativere Inhalte erstellen können. Einheitliche Plattformen wie FlowHunt werden den Zugang zu diesen fortschrittlichen Fähigkeiten erleichtern.
Erleben Sie Top-LLMs im direkten Vergleich und optimieren Sie Ihren Workflow für Content-Erstellung mit FlowHunts einheitlicher Plattform.
Ein Großes Sprachmodell (LLM) ist eine KI, die auf riesigen Textmengen trainiert wurde, um menschliche Sprache zu verstehen, zu generieren und zu verarbeiten. L...
Textgenerierung mit großen Sprachmodellen (LLMs) bezieht sich auf den fortschrittlichen Einsatz von Machine-Learning-Modellen zur Erstellung menschenähnlicher T...
Entdecken Sie die Kosten, die mit dem Training und der Bereitstellung von Large Language Models (LLMs) wie GPT-3 und GPT-4 verbunden sind, einschließlich Rechen...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.