Context Engineering: Der ultimative Leitfaden 2025 zur Meisterung des KI-Systemdesigns
Tauchen Sie tief ein in das Context Engineering für KI. Dieser Leitfaden behandelt Grundprinzipien, von Prompt vs. Kontext bis hin zu fortgeschrittenen Strategien wie Speicherverwaltung, Context Rot und Multi-Agenten-Design.
AI
LLM
System Design
Agents
Context Engineering
Prompt Engineering
RAG
Die Landschaft der KI-Entwicklung hat sich grundlegend gewandelt. Wo wir früher die perfekte Prompt-Formulierung suchten, stehen wir heute vor einer weitaus komplexeren Herausforderung: den Aufbau ganzer Informationsarchitekturen, die unsere Sprachmodelle umgeben und stärken.
Dieser Wandel markiert den Übergang vom Prompt Engineering zum Context Engineering – und stellt nichts Geringeres als die Zukunft der praktischen KI-Entwicklung dar. Die Systeme, die heute echten Mehrwert liefern, verlassen sich nicht auf magische Prompts. Sie sind erfolgreich, weil ihre Architekten gelernt haben, umfassende Informationsökosysteme zu orchestrieren.
Andrej Karpathy brachte diese Entwicklung perfekt auf den Punkt, als er Context Engineering als die sorgfältige Praxis beschrieb, das Kontextfenster genau im richtigen Moment mit den richtigen Informationen zu füllen. Diese scheinbar einfache Aussage offenbart eine grundlegende Wahrheit: Das LLM ist nicht mehr der Star der Show. Es ist ein zentrales Bauteil in einem sorgfältig designten System, in dem jedes Informationsstück – jedes Speicherfragment, jede Toolbeschreibung, jedes abgerufene Dokument – bewusst positioniert wurde, um optimale Ergebnisse zu erzielen.
Was ist Context Engineering?
Ein historischer Rückblick
Die Wurzeln des Context Engineering reichen weiter zurück, als viele denken. Während sich die Diskussionen um Prompt Engineering in den Jahren 2022-2023 verbreiteten, entstanden die Grundkonzepte des Context Engineering bereits vor über zwanzig Jahren im Bereich Ubiquitous Computing und der Mensch-Maschine-Interaktion.
Schon 2001 legte Anind K. Dey eine Definition vor, die sich als bemerkenswert vorausschauend erwies: Kontext umfasst jede Information, die hilft, die Situation einer Entität zu charakterisieren. Dieses frühe Rahmenwerk bildet bis heute die Grundlage für unser Verständnis maschineller Umgebungswahrnehmung.
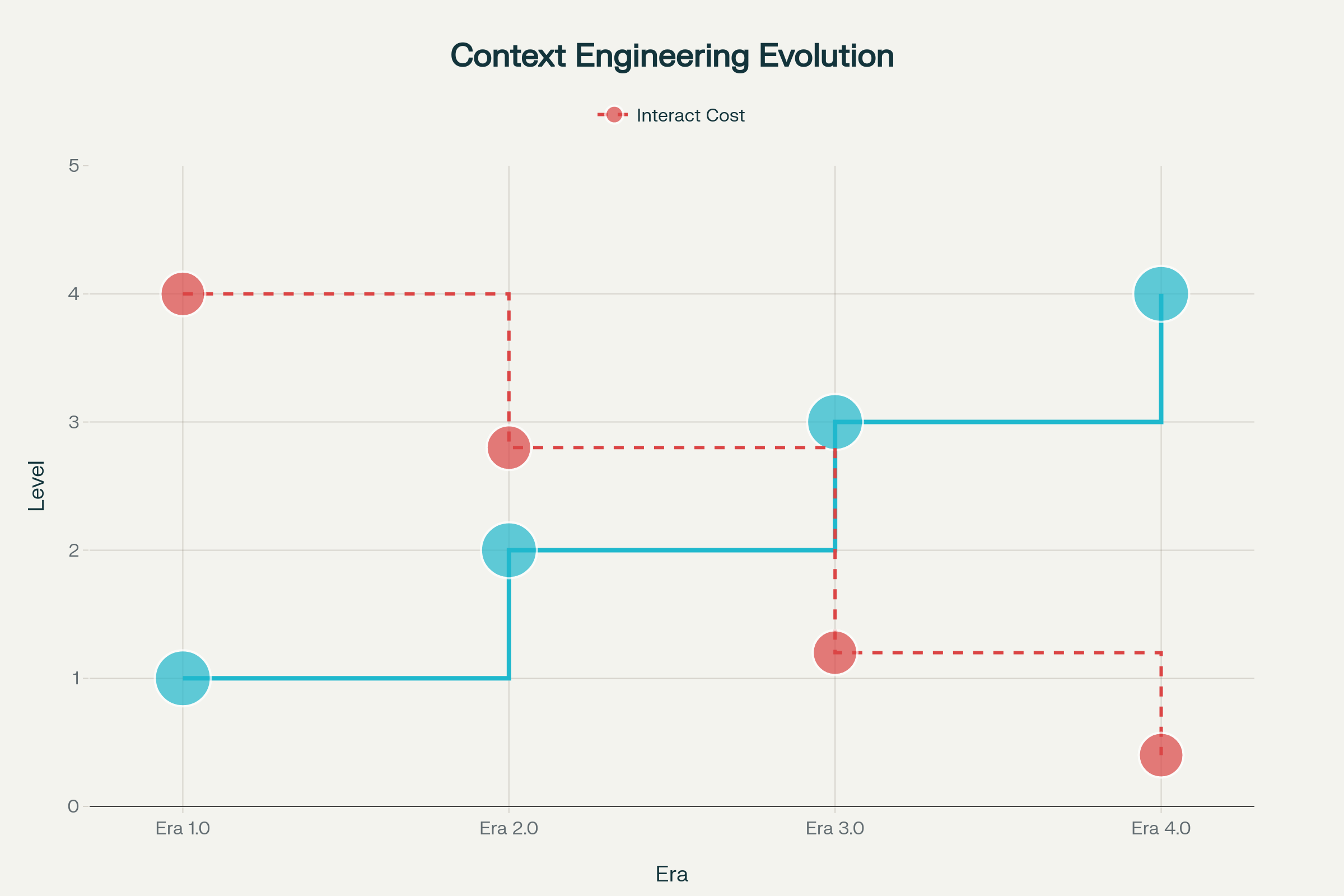
Die Entwicklung des Context Engineering verlief in mehreren Phasen, jede geprägt von Fortschritten in der maschinellen Intelligenz:
Ära 1.0: Primitive Berechnung (1990er–2020) — In dieser langen Phase konnten Maschinen nur strukturierte Eingaben und einfache Umweltsignale verarbeiten. Menschen mussten Kontexte vollständig in maschinenlesbare Formate übersetzen. Beispiele: Desktop-Anwendungen, Mobile Apps mit Sensoren, frühe Chatbots mit starren Antwortbäumen.
Ära 2.0: Agentenzentrierte Intelligenz (2020–heute) — Mit GPT-3 begann 2020 ein Paradigmenwechsel. Große Sprachmodelle ermöglichten echte Sprachverständnis und die Arbeit mit impliziten Absichten. Diese Ära ermöglichte echte Mensch-Agent-Kollaboration, in der Mehrdeutigkeiten und unvollständige Informationen durch Sprachverständnis und In-Context Learning bewältigt werden.
Ära 3.0 & 4.0: Menschliche und Übermenschliche Intelligenz (Zukunft) — Die nächsten Wellen versprechen Systeme, die hochkomplexe Informationen mit menschlicher Flexibilität verarbeiten und schließlich proaktiv Kontexte konstruieren, um Bedürfnisse zu erkennen, die Nutzer noch nicht einmal geäußert haben.
Entwicklung des Context Engineering über vier Epochen: Von primitiver Berechnung zu übermenschlicher Intelligenz
Eine formale Definition
Im Kern ist Context Engineering die systematische Disziplin, zu entwerfen und zu optimieren, wie Kontextinformationen durch KI-Systeme fließen – von der ersten Erfassung über Speicherung, Verwaltung und schließlich Verwendung zur Verbesserung des maschinellen Verständnisses und der Aufgabenerfüllung.
Mathematisch lässt sich dies als Transformationsfunktion ausdrücken:
$CE: (C, T) \rightarrow f_{context}$
Dabei gilt:
C steht für rohe Kontextinformationen (Entitäten und ihre Eigenschaften)
T bezeichnet die Zielaufgabe oder Anwendungsdomäne
f_{context} ist die resultierende Kontextverarbeitungsfunktion
Praktisch ergeben sich daraus vier grundlegende Operationen:
Erfassen relevanter Kontexts-Signale über Sensoren und Informationskanäle
Speichern dieser Informationen effizient in lokalen Systemen, Netzwerken und der Cloud
Managen der Komplexität durch intelligente Verarbeitung von Text, multimodalen Eingaben und Beziehungen
Nutzen des Kontexts durch Filterung auf Relevanz, systemspezifische Weitergabe und Anpassung an Nutzeranforderungen
Warum Context Engineering wichtig ist: Das Entropie-Reduktions-Framework
Context Engineering adressiert eine grundlegende Asymmetrie in der Mensch-Maschine-Kommunikation. Menschen füllen Gesprächslücken mühelos durch geteiltes Wissen, emotionale Intelligenz und Situationsbewusstsein. Maschinen fehlt dies völlig.
Dieses Defizit äußert sich als Informationsentropie. Menschliche Kommunikation funktioniert effizient, weil wir große Mengen an gemeinsamem Kontext voraussetzen können. Maschinen jedoch benötigen alles explizit. Context Engineering ist letztlich die Vorverarbeitung von Kontexten für Maschinen – die Komplexität menschlicher Absichten in maschinenverarbeitbare, „niederentropische“ Repräsentationen zu komprimieren.
Mit wachsender maschineller Intelligenz wird diese Entropiereduktion zunehmend automatisiert. Heute, in Ära 2.0, orchestrieren Ingenieur:innen diesen Prozess noch weitgehend selbst. In Ära 3.0 und darüber hinaus übernehmen Maschinen diesen Aufwand zunehmend eigenständig. Die Kernherausforderung bleibt jedoch: die Kluft zwischen menschlicher Komplexität und maschinellem Verständnis zu überbrücken.
Prompt Engineering vs. Context Engineering: Zentrale Unterschiede
Ein häufiger Fehler ist die Gleichsetzung dieser beiden Disziplinen. In Wahrheit stehen sie für grundlegend verschiedene Ansätze im KI-Systemdesign.
Prompt Engineering konzentriert sich auf die Formulierung einzelner Anweisungen oder Fragen, um das Modellverhalten zu steuern. Es geht um die sprachliche Optimierung dessen, was Sie dem Modell mitteilen – Formulierung, Beispiele und Argumentationsmuster in einer Interaktion.
Context Engineering ist eine umfassende Systemdisziplin, die alles steuert, was das Modell während der Inferenz sieht – inklusive Prompts, aber auch abgerufener Dokumente, Speichersysteme, Toolbeschreibungen, Zustandsinformationen und mehr.
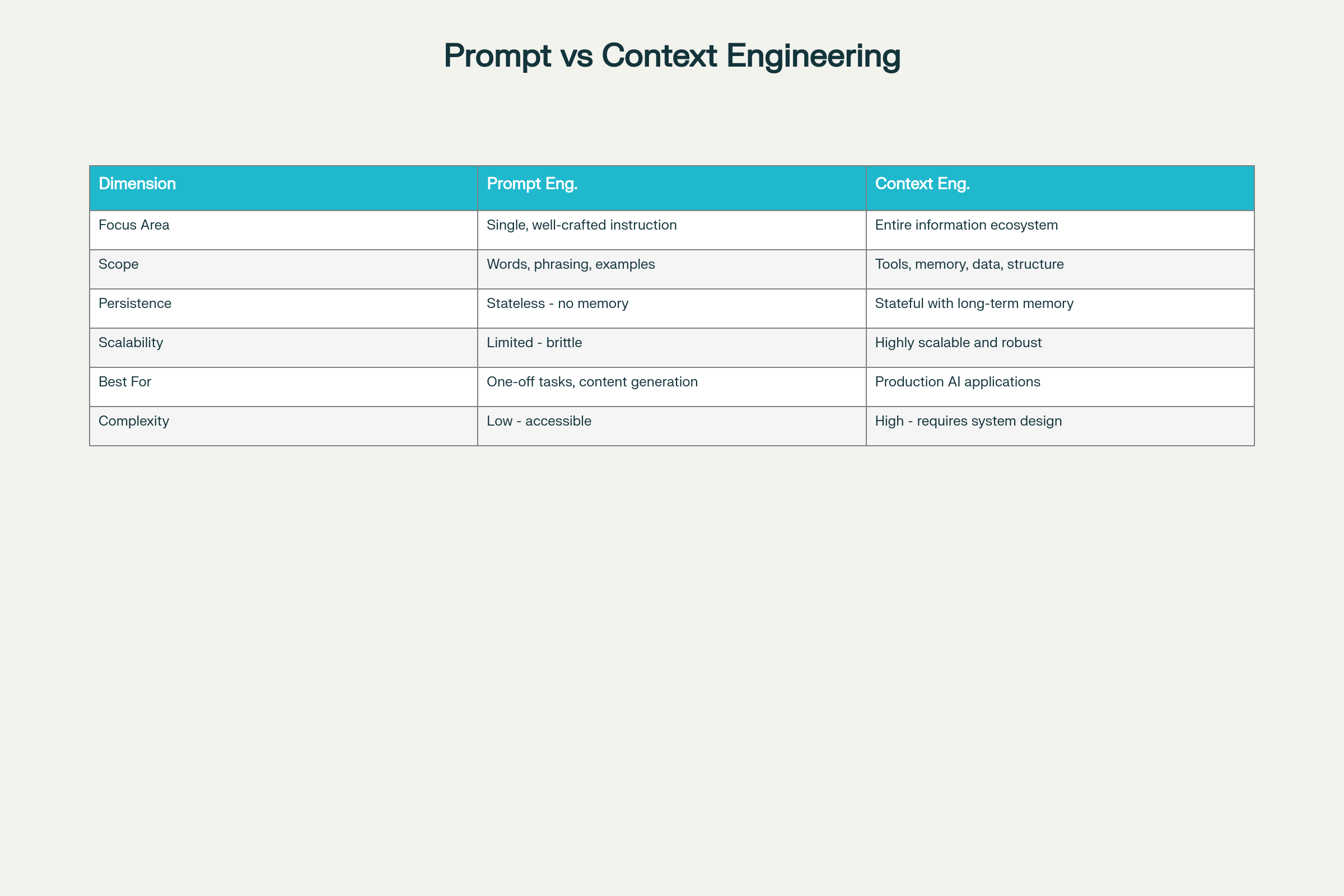
Prompt Engineering vs Context Engineering: Zentrale Unterschiede und Abwägungen
Beispiel: ChatGPT um das Verfassen einer professionellen E-Mail zu bitten ist Prompt Engineering. Eine Kundenservice-Plattform zu bauen, die Gesprächsverläufe über mehrere Sitzungen hinweg speichert, Kontodetails abruft und frühere Support-Tickets kennt – das ist Context Engineering.
Zentrale Unterschiede über acht Dimensionen:
Dimension
Prompt Engineering
Context Engineering
Fokus
Einzelinstruktion
Umfassendes Informationsökosystem
Umfang
Worte, Formulierungen, Beispiele
Tools, Speicher, Datenarchitektur, Struktur
Persistenz
Zustandslos – keine Erinnerung
Zustandsbehaftet mit Langzeitspeicher
Skalierbarkeit
Begrenzte Skalierung, fragil
Hoch skalierbar und robust
Geeignet für
Einmalige Aufgaben, Content-Generierung
Produktionsreife KI-Anwendungen
Komplexität
Geringe Einstiegshürde
Hoch – erfordert Systemdesign-Expertise
Zuverlässigkeit
Unvorhersehbar im großen Maßstab
Konsistent und verlässlich
Wartung
Fragil bei Anforderungsänderungen
Modular und wartbar
Die entscheidende Erkenntnis: Produktionsreife LLM-Anwendungen benötigen fast immer Context Engineering und nicht nur clevere Prompts. Wie Cognition AI feststellte, ist Context Engineering zur Hauptaufgabe für Ingenieur:innen im Agentenbau geworden.
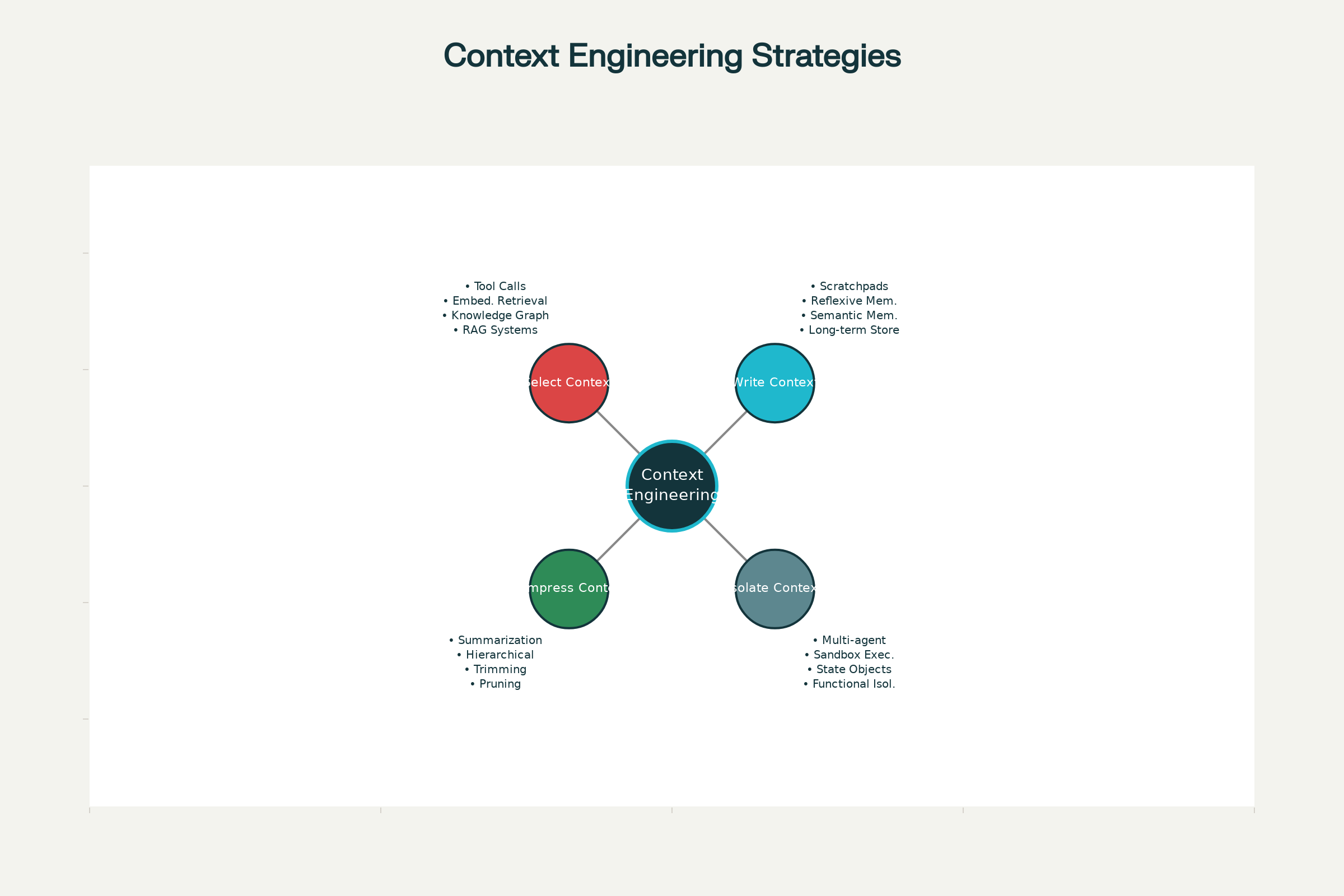
Die vier Kernstrategien des Context Engineering
In führenden KI-Systemen – von Claude und ChatGPT bis zu spezialisierten Agenten von Anthropic und anderen – haben sich vier Kernstrategien für wirksames Kontextmanagement herauskristallisiert. Sie können einzeln oder kombiniert eingesetzt werden.
1. Write Context: Informationen außerhalb des Kontextfensters speichern
Das Grundprinzip ist einfach: Zwingen Sie das Modell nicht, sich alles zu merken. Speichern Sie stattdessen wichtige Informationen außerhalb des Kontextfensters, damit sie bei Bedarf zuverlässig abgerufen werden können.
Scratchpads sind die intuitivste Umsetzung. Wie Menschen Notizen machen, verwenden KI-Agenten Scratchpads, um Informationen für später zu sichern. Das kann ein simples Tool sein, mit dem der Agent Notizen speichert, oder ein Feld im Laufzeit-Zustandsobjekt, das über Ausführungsschritte hinweg erhalten bleibt.
Anthropics Multi-Agenten-Researcher zeigt dies beispielhaft: Der LeadResearcher entwickelt zunächst einen Plan und speichert ihn im Speicher, damit er bei Überschreitung der 200.000 Token-Grenze nicht verloren geht.
Memories erweitern das Scratchpad-Konzept über Sitzungen hinaus. Anstatt Informationen nur innerhalb einer Aufgabe zu speichern (Session-Scoped Memory), bauen Systeme Langzeitgedächtnisse auf, die sich über viele Nutzer-Interaktionen hinweg entwickeln. Dies ist heute Standard in ChatGPT, Claude Code, Cursor und Windsurf.
Initiativen wie Reflexion führen reflektierende Erinnerungen ein – der Agent reflektiert nach jedem Schritt und generiert Erinnerungen für die Zukunft. Generative Agents gehen weiter und verdichten regelmäßig Erinnerungen aus früherem Feedback.
Drei Erinnerungstypen:
Episodisch: Konkrete Beispiele vergangener Interaktionen (wichtig für Few-Shot-Lernen)
Prozedural: Regeln oder Handlungsanweisungen (für konsistentes Verhalten)
Semantisch: Fakten und Relationen über die Welt (für fundiertes Wissen)
2. Select Context: Die richtigen Informationen heranziehen
Sobald Informationen gespeichert sind, muss der Agent gezielt das Relevante für die aktuelle Aufgabe abrufen. Schlechte Auswahl ist ebenso schädlich wie keine Erinnerung – irrelevante Infos verwirren das Modell oder führen zu Halluzinationen.
Mechanismen zur Erinnerungsauswahl:
Einfache Ansätze setzen auf feste, stets eingebundene Dateien. Claude Code nutzt eine CLAUDE.md für prozedurale Erinnerungen, Cursor und Windsurf verwenden rules-Dateien. Doch das skaliert schlecht, wenn Hunderte Fakten und Relationen anfallen.
Für größere Speichersammlungen kommen Embedding-basiertes Retrieval und Wissensgraphen zum Einsatz. System und Anfrage werden als Vektoren kodiert und die semantisch ähnlichsten Erinnerungen abgerufen.
Doch wie Simon Willison auf der AIEngineer World’s Fair zeigte, kann auch das spektakulär scheitern: ChatGPT fügte unerwartet seinen Standort aus Erinnerungen in ein Bild ein. Das macht deutlich, wie sorgfältig das Engineering sein muss.
Tool-Auswahl ist eine weitere Herausforderung. Bei Dutzenden oder Hunderten Tools kann deren bloße Auflistung zu Verwirrung führen – überlappende Beschreibungen verleiten das Modell zu falschen Entscheidungen. Ein effektiver Ansatz: RAG-Prinzipien auf Toolbeschreibungen anwenden, d.h. nur semantisch relevante Tools abrufen. So wurde eine dreifache Steigerung der Auswahlgenauigkeit erzielt.
Wissensabruf ist vielleicht das reichhaltigste Problemfeld. Code-Agenten müssen das produktiv lösen. Wie ein Windsurf-Ingenieur bemerkte: Code zu indexieren bedeutet nicht, Kontext effektiv zu holen. Sie kombinieren Indexierung, Embedding-Suche mit AST-Parsing und Chunking entlang semantischer Grenzen. Aber Embedding-Suche wird mit wachsendem Codebestand unzuverlässiger. Erfolg braucht eine Kombination aus Grep-/Dateisuche, Wissensgraph-basiertem Retrieval und Re-Ranking nach Relevanz.
3. Compress Context: Nur das Notwendige behalten
Bei Langzeitaufgaben wächst der Kontext schnell. Scratchpad-Notizen, Tool-Ausgaben, Interaktionshistorie – alles kann das Fenster sprengen. Kompressionsstrategien destillieren gezielt, was zählt.
Zusammenfassung ist die wichtigste Technik. Claude Code implementiert „auto-compact“: Ist das Kontextfenster zu 95 % gefüllt, wird die Interaktionshistorie zusammengefasst. Dabei kommen verschiedene Strategien zum Einsatz:
Rekursive Zusammenfassung: Zusammenfassungen von Zusammenfassungen für hierarchische Kompaktheit
Hierarchische Zusammenfassung: Verschiedene Abstraktionsebenen
Gezielte Zusammenfassung: Nur spezifische Teile (z.B. tokenlastige Suchergebnisse) werden komprimiert
Cognition AI nutzt feinjustierte Modelle zur Zusammenfassung an Agenten-Grenzen, um Tokenverbrauch beim Wissensaustausch zu minimieren – ein Beispiel für den technischen Tiefgang dieses Schritts.
Context Trimming ergänzt dies. Statt LLMs zur Zusammenfassung einzusetzen, werden mit festen Heuristiken ältere Nachrichten, unwichtige Infos oder mit trainierten Prunern wie Provence für Q&A entfernt.
Die zentrale Erkenntnis: Was Sie entfernen, ist oft genauso wichtig wie das, was bleibt. Ein fokussierter 300-Token-Kontext schlägt oft einen unfokussierten mit 113.000 Tokens.
Isolationsstrategien anerkennen, dass verschiedene Aufgaben unterschiedliche Informationen erfordern. Statt alle Informationen in ein Kontextfenster zu pressen, werden sie über spezialisierte Systeme verteilt.
Multi-Agenten-Architekturen sind der gängigste Ansatz. Die OpenAI Swarm Library ist explizit auf „Separation of Concerns“ ausgelegt – spezialisierte Subagenten bearbeiten Aufgaben mit eigenen Tools, Anweisungen und Kontextfenstern.
Anthropics Forschung zeigt die Stärke dieses Ansatzes: Viele Agenten mit isolierten Kontexten übertreffen Einzelagenten, weil jedes Subagenten-Fenster für Teilaufgaben optimal genutzt wird. Subagenten arbeiten parallel in eigenen Fenstern und beleuchten verschiedene Aspekte gleichzeitig.
Multi-Agenten-Systeme bringen jedoch Abwägungen mit sich. Anthropic berichtet bis zu 15-fachen Tokenverbrauch gegenüber Einzelagenten-Chats. Dies erfordert ausgefeilte Orchestrierung, Prompt-Engineering und Koordination.
Sandbox-Umgebungen bieten eine weitere Isolationsstrategie. HuggingFace’s CodeAgent zeigt: Statt JSON zurückzugeben, das das Modell analysieren muss, gibt der Agent Code aus, der in einer Sandbox ausgeführt wird. Nur ausgewählte Ausgaben werden an das LLM zurückgegeben – tokenlastige Objekte bleiben isoliert. Das ist besonders für visuelle und Audiodaten effektiv.
State Object Isolation ist vielleicht die unterschätzteste Technik. Der Laufzeitstatus eines Agenten kann als strukturiertes Schema (wie ein Pydantic-Modell) mit mehreren Feldern gestaltet werden. Ein Feld (z.B. messages) wird dem LLM bei jedem Schritt gezeigt, andere Felder bleiben isoliert und werden selektiv genutzt. Das erlaubt feingranulare Steuerung ohne architektonische Komplexität.
Vier Kernstrategien für effektives Context Engineering in KI-Agenten
Das Context Rot Problem: Eine zentrale Herausforderung
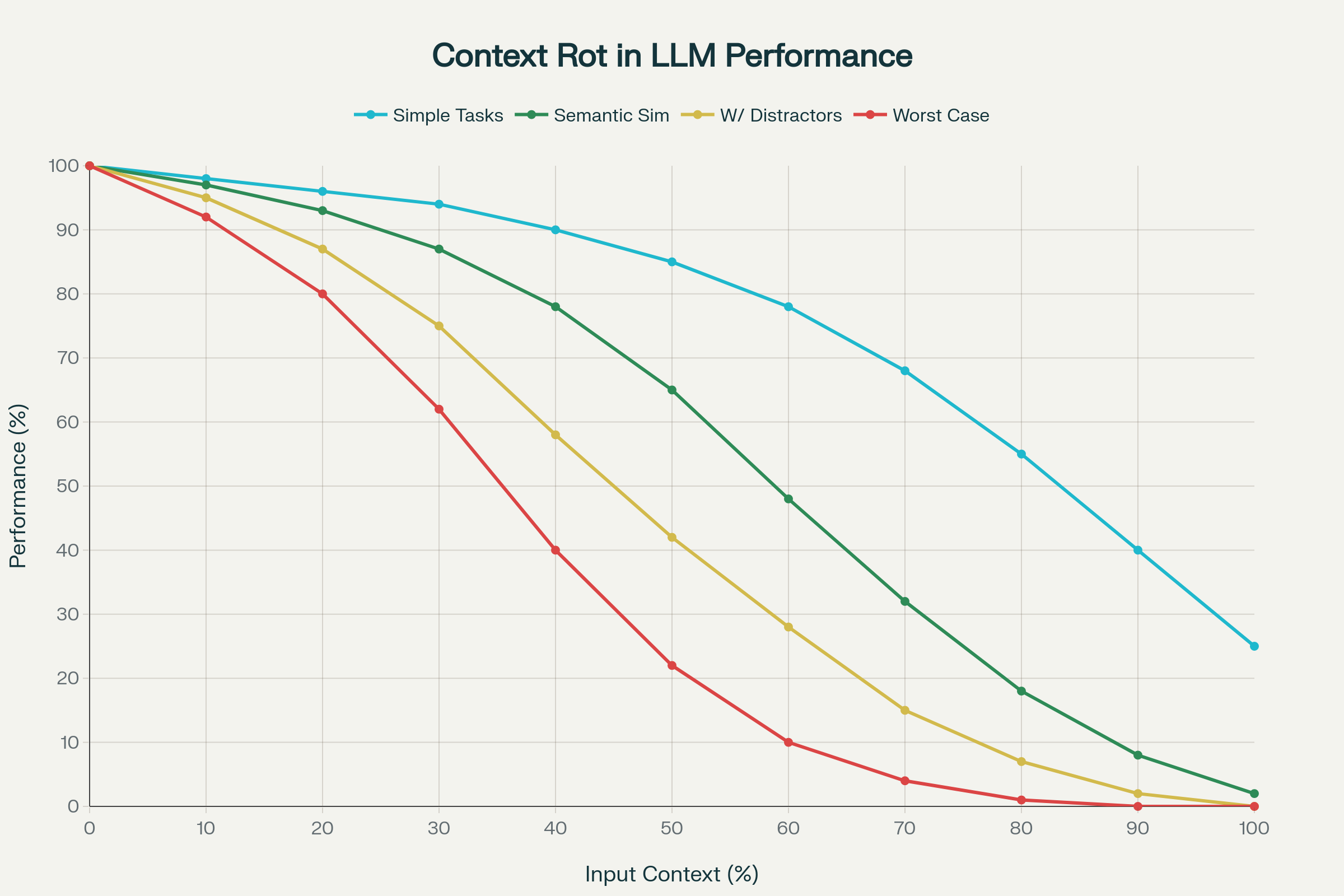
Obwohl längere Kontexte branchenweit gefeiert werden, zeigen aktuelle Forschungen eine beunruhigende Realität: Mehr Kontext bedeutet nicht automatisch bessere Leistung.
Eine Studie mit 18 führenden LLMs – darunter GPT-4.1, Claude 4, Gemini 2.5 und Qwen 3 – entdeckte das Phänomen Context Rot: den oft drastischen, unvorhersehbaren Leistungsabfall mit wachsendem Eingabekontext.
Zentrale Erkenntnisse zu Context Rot
1. Nichtlineare Leistungsabfälle
Die Leistung sinkt nicht linear. Modelle zeigen plötzliche, individuelle Einbrüche je nach Modell und Aufgabe. Ein Modell kann bis zu einer bestimmten Kontextlänge 95 % Genauigkeit halten, dann plötzlich auf 60 % fallen. Diese Einbrüche sind modellübergreifend unvorhersehbar.
2. Semantische Komplexität verstärkt Context Rot
Einfache Aufgaben (z.B. Wiederholen von Wörtern, semantischer Abruf) zeigen moderate Verluste. Müssen aber semantisch ähnliche „Nadeln im Heuhaufen“ gefunden werden, sinkt die Genauigkeit massiv. Plausible Ablenker – ähnliche, aber nicht relevante Infos – verschlechtern die Genauigkeit deutlich.
3. Positionsbias und Aufmerksamkeitskollaps
Transformer-Attention skaliert nicht linear. Tokens am Anfang (Primacy Bias) und Ende (Recency Bias) erhalten überproportional viel Aufmerksamkeit. In Extremfällen kollabiert die Aufmerksamkeit, sodass das Modell große Teile des Inputs ignoriert.
4. Modellspezifische Fehlermuster
Verschiedene LLMs zeigen individuelle Muster:
GPT-4.1: Halluziniert, wiederholt falsche Tokens
Gemini 2.5: Fügt irrelevante Fragmente oder Satzzeichen ein
Claude Opus 4: Verweigert Aufgaben oder wird übervorsichtig
5. Auswirkungen in echten Dialogen
Am alarmierendsten: Im LongMemEval-Benchmark waren Modelle mit Zugang zum vollen Gespräch (ca. 113k Tokens) deutlich schlechter als bei nur 300 fokussierten Tokens. Das zeigt: Context Rot schwächt Abruf und Logik auch in realen Dialogen.
Context Rot: Leistungsabfall je nach Eingabelänge bei 18 LLMs
Fazit: Qualität vor Quantität
Die wichtigste Erkenntnis aus Context Rot: Die Menge der Input-Tokens allein bestimmt nicht die Qualität. Wie der Kontext konstruiert, gefiltert und präsentiert wird, ist mindestens ebenso wichtig.
Das bestätigt die ganze Disziplin des Context Engineering. Statt lange Kontextfenster als Allheilmittel zu sehen, erkennen fortschrittliche Teams, dass sorgfältiges Context Engineering – durch Kompression, Auswahl und Isolation – essenziell ist, um bei großen Inputs die Leistung zu erhalten.
Context Engineering in der Praxis: Anwendungsbeispiele
Claude Code und Cursor sind State-of-the-Art im Context Engineering für Code-Assistenz:
Erfassung: Kontext aus offenen Dateien, Projektstruktur, Editierverlauf, Terminalausgabe und Kommentaren wird gesammelt.
Management: Statt alle Dateien in den Prompt zu laden, wird gezielt komprimiert. Claude Code nutzt hierarchische Zusammenfassungen. Kontext wird nach Funktion getaggt (z.B. „aktuell editiertes File“, „abhängige Datei“, „Fehlermeldung“).
Nutzung: Pro Schritt werden die relevanten Dateien und Kontextelemente strukturiert präsentiert, getrennte Tracks für Logik und sichtbare Ausgabe gepflegt.
Kompression: Bei Kontextgrenzen startet auto-compact, um die Interaktionshistorie unter Erhalt der wichtigsten Entscheidungen zusammenzufassen.
Ergebnis: Die Tools bleiben in großen Projekten (tausende Dateien) performant, trotz Kontextbeschränkungen.
Fallstudie 2: Tongyi DeepResearch (Open-Source Deep Research Agent)
Tongyi DeepResearch zeigt, wie Context Engineering komplexe Rechercheaufgaben ermöglicht:
Data-Synthesis-Pipeline: Statt auf beschränkte, handannotierte Daten zu setzen, erstellt Tongyi mit iterativer Komplexitätssteigerung Forschungsfragen auf PhD-Niveau. Jede Iteration vertieft das Wissen und konstruiert komplexere Aufgaben.
Kontextmanagement: Das System setzt auf IterResearch – in jeder Runde wird ein fokussierter Workspace aus den wichtigsten Outputs der letzten Runde rekonstruiert. So wird „kognitive Erstickung“ durch Kontextüberladung verhindert.
Parallele Exploration: Mehrere Forschungsagenten arbeiten parallel mit isolierten Kontexten, ein Synthese-Agent integriert deren Ergebnisse.
Ergebnisse: Tongyi DeepResearch erreicht Leistungen auf Augenhöhe mit Systemen wie OpenAI DeepResearch (32,9 Punkte im Humanity’s Last Exam, 75 auf Nutzerbenchmarks).
Fallstudie 3: Anthropics Multi-Agent Researcher
Anthropics Forschung zeigt, wie Isolation und Spezialisierung die Leistung steigern:
Architektur: Spezialisierte Subagenten bearbeiten einzelne Aufgaben (Literatur, Synthese, Verifikation) mit eigenen Kontextfenstern.
Vorteile: So werden Single-Agenten-Systeme qualitativ übertroffen, da jedes Subagenten-Fenster für seine Teilaufgabe optimiert ist.
Nachteil: Der Tokenverbrauch steigt um bis zu das 15-fache gegenüber Einzelagenten-Chats.
Das zeigt: Context Engineering ist oft ein Abwägen zwischen Qualität, Geschwindigkeit und Kosten – die richtige Balance hängt von den Anforderungen ab.
Das Framework für Designentscheidungen
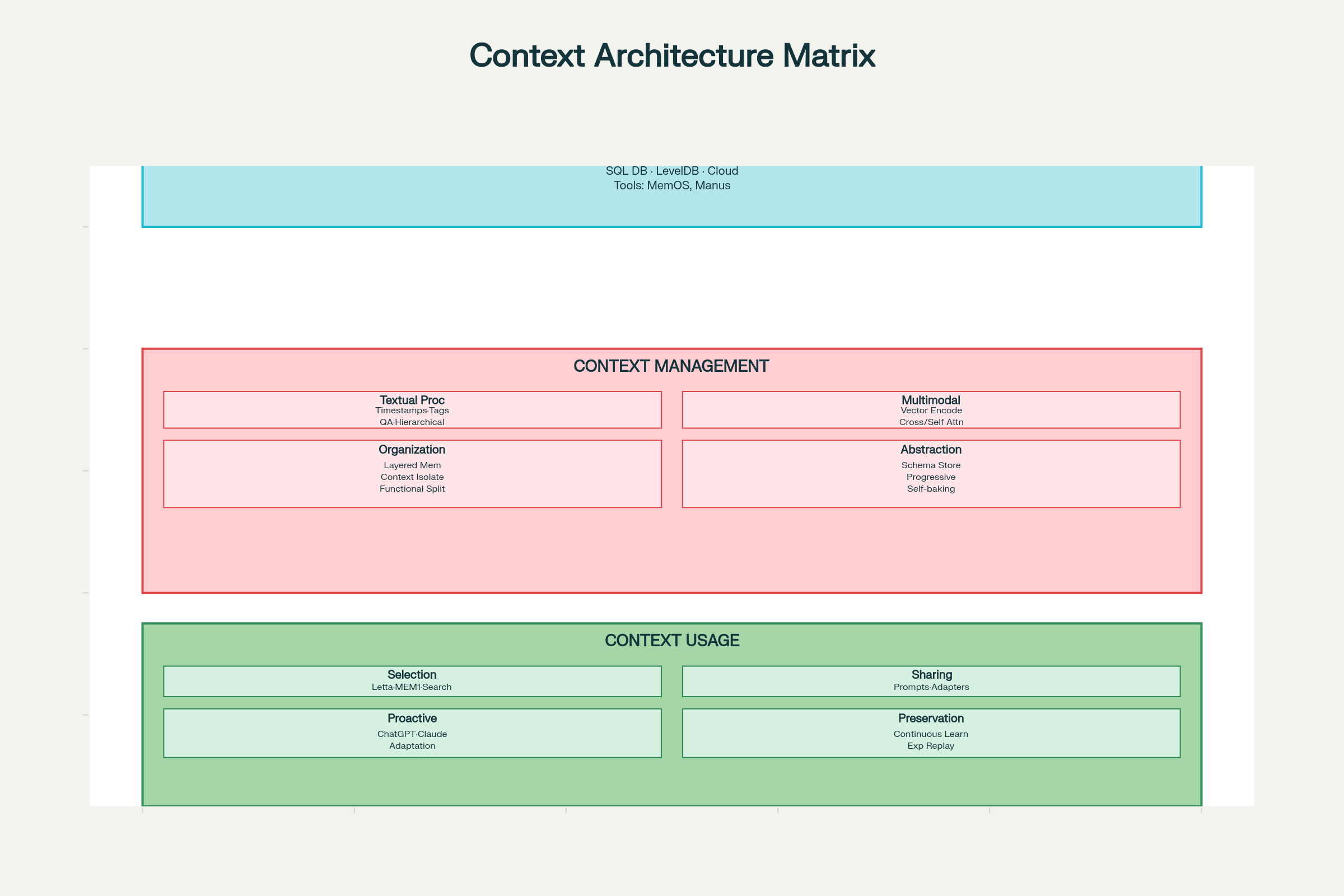
Wirksames Context Engineering benötigt systematisches Denken über drei Achsen: Erfassung & Speicherung, Management und Nutzung.
Context Engineering Designüberlegungen: Gesamtsystem-Architektur und Komponenten
Balance zwischen Nützlichkeit und Privatsphäre bleibt eine Herausforderung
Context Engineering Skills: Was Teams meistern müssen
Mit wachsender Bedeutung des Context Engineering trennt sich hier die Spreu vom Weizen.
1. Strategische Kontextzusammenstellung
Teams müssen wissen, welche Informationen für welche Aufgabe nötig sind. Es geht nicht um pure Datensammlung – sondern darum, Anforderungen so zu verstehen, dass Rauschen vermieden wird.
In der Praxis:
Fehleranalysen zur Identifikation fehlender Kontexte
A/B-Tests verschiedener Kontextkombinationen
Observability zur Wirkungsmessung einzelner Elemente
2. Speicherarchitektur
Effektive Speichersysteme erfordern den richtigen Umgang mit unterschiedlichen Erinnerungstypen:
Wann Kurzzeit-, wann Langzeitspeicher?
Wie interagieren verschiedene Erinnerungstypen?
Welche Kompressionsstrategien erhalten die Qualität bei Tokenreduktion?
3. Semantische Suche & Retrieval
Jenseits von Keyword-Matching braucht es Expertise in:
Embedding-Modelle und deren Grenzen
Vektorähnlichkeitsmetriken und ihre Abwägungen
Re-Ranking- und Filterstrategien
Umgang mit Mehrdeutigkeiten
4. Tokenökonomie & Kostenanalyse
Jedes Byte Kontext ist eine Abwägung:
Tokenverbrauch je Kontextvariante überwachen
Modellabhängige Kostenstrukturen verstehen
Qualität gegen Kosten und Latenz ausbalancieren
5. Systemorchestrierung
Mit mehreren Agenten, Tools und Speichern ist Orchestrierung essenziell:
Koordination zwischen Subagenten
Fehlerbehandlung und Recovery
Zustandsmanagement für Langzeitaufgaben
6. Evaluation & Messung
Context Engineering ist letztlich Optimierung:
Leistungsmetriken definieren
A/B-Tests verschiedener Ansätze
Einfluss auf Nutzererfahrung messen, nicht nur Modellgenauigkeit
Wie ein leitender Ingenieur sagte: Der schnellste Weg zu hochwertigen KI-Produkten ist, kleine, modulare Agenten-Konzepte in bestehende Produkte einzubauen.
Best Practices für erfolgreiches Context Engineering
1. Einfach starten, gezielt erweitern
Beginnen Sie mit simpler Prompt-Entwicklung und Scratchpad-Speicher. Komplexität (Multi-Agenten-Isolation, anspruchsvolles Retrieval) erst hinzufügen, wenn sie nachweislich gebraucht wird.
2. Alles messen
Tools wie LangSmith für Observability nutzen. Tracken Sie:
Kontextqualität steigt, wenn nachvollziehbar ist, was das Modell sieht. Nutzen Sie:
Klare, strukturierte Formate (JSON, Markdown)
Getaggte Kontexte mit expliziten Rollen
Trennung der Verantwortlichkeiten
5. Context-First statt LLM-First
Nicht mit „Welches LLM nehmen wir?“ starten, sondern mit „Welchen Kontext braucht diese Aufgabe?“ Das LLM ist dann ein Baustein im größeren Kontextsystem.
6. Schichtenarchitekturen nutzen
Trennen Sie:
Arbeitsgedächtnis (aktuelles Kontextfenster)
Kurzzeitgedächtnis (letzte Interaktionen)
Langzeitgedächtnis (dauerhafte Fakten)
Jede Schicht erfüllt einen anderen Zweck und kann separat optimiert werden.
Herausforderungen und Zukunftsperspektiven
Aktuelle Herausforderungen
1. Context Rot & Skalierung
Trotz Gegenmaßnahmen bleibt Context Rot ungelöst. Je größer der Input, desto anspruchsvoller werden Auswahl- und Kompressionsmechanismen.
2. Konsistenz & Kohärenz der Speicher
Kohärenz zwischen verschiedenen Erinnerungsarten und Zeiträumen bleibt schwierig. Widersprüchliche oder veraltete Speicherinformationen schaden der Leistung.
3. Privatsphäre & selektive Offenlegung
Mit wachsendem Nutzerkontext wird der Spagat zwischen Personalisierung und Privatsphäre kritischer. Das „Kontextfenster gehört nicht mehr ihnen“-Problem entsteht, wenn Unerwartetes auftaucht.
4. Rechnerischer Overhead
Komplexes Context Engineering kostet Rechenleistung. Auswahl, Kompression, Retrieval brauchen Ressourcen. Die richtige Balance ist eine offene Frage.
Vielversprechende Zukunftsrichtungen
1. Gelernte Context Engineers
Statt alles von Hand zu bauen, könnten Systeme optimale Kontextstrategien via Meta- oder Reinforcement Learning selbst lernen.
2. Aufkommen symbolischer Mechanismen
Neue Forschung zeigt, dass LLMs emergente symbolische Strukturen entwickeln. Diese könnten höhere Kontextabstraktion ermöglichen.
3. Cognitive Tools & Prompt Programming
Frameworks wie IBMs „Cognitive Tools“ kapseln logische Operationen als Module. So wird Context Engineering zu kompositorischer Software – kleine, wiederverwendbare Bausteine.
4. Neural Field Theory für Kontext
Statt diskreter Elemente könnte Kontext als kontinuierliches neuronales Feld modelliert werden – für flüssigere, adaptivere Verwaltung.
5. Quanten-Semantik & Superposition
Erste Forschung fragt, ob Kontext Quanten-Superpositionsprinzipien nutzen könnte – Informationen existieren in mehreren Zuständen, bis sie gebraucht werden. Das würde Speicherung und Abruf revolutionieren.
Fazit: Warum Context Engineering jetzt zählt
Wir stehen an einem Wendepunkt der KI-Entwicklung. Lange lag der Fokus darauf, Modelle größer und klüger zu machen. Die Frage war: „Wie verbessern wir das LLM?“
Heute lautet die Kernfrage: „Wie bauen wir Systeme um LLMs, um ihr volles Potenzial auszuschöpfen?“
Context Engineering ist die Antwort. Es ist kein technischer Trick – sondern eine Grunddisziplin für den Bau zuverlässiger, skalierbarer und wirklich nützlicher KI-Systeme.
Der Beweis ist überwältigend. Teams bei Anthropic, Alibaba (Tongyi) und anderen Tech-Riesen zeigen: Gutes Context Engineering schlägt rohe Modellgröße. Ein kleines, gutes Team mit weniger leistungsstarkem Modell, aber durchdachtem Kontextmanagement, erzielt bessere Ergebnisse als große Teams mit Frontier-Modellen, aber schlechtem Kontext.
Das hat weitreichende Folgen:
Context Engineering demokratisiert KI: Sie brauchen nicht das größte Modell, sondern das am besten konstruierte Kontextsystem.
Es wird zur Schlüsselkompetenz: Teams, die Context Engineering meistern, werden den größten Einfluss auf KI-Ergebnisse haben.
Es ist die Basis für Agenten: Je mehr KI von Einzelanfragen zu langanhaltender, mehrschrittiger Logik übergeht, desto unverzichtbarer wird Context Engineering.
Es bleibt: Egal wie klug Modelle werden – das Problem, das Kontextfenster sinnvoll zu füllen, bleibt.
Die nächste Generation von KI-Systemen wird weniger durch Parameter, sondern durch die Qualität ihres Kontext-Engineerings definiert.
Literatur & weiterführende Ressourcen
Für Teams, die ihre Context-Engineering-Expertise vertiefen möchten, bieten diese Ressourcen Theorie und Praxis:
Context Engineering 2.0: The Context of Context Engineering — Umfassende Arbeit zu 20+ Jahren Kontextevolution über vier Ären hinweg
Tongyi DeepResearch — Produktionsexempel für fortgeschrittenes Context Engineering bei Research-Agenten
12-Factor Agents — Prinzipien für zuverlässige LLM-Anwendungen inklusive Kontext-Management
Context Rot Research — Wie man Leistungsabfall bei wachsender Eingabelänge vermeidet
**Cognitive Tools Framework
Häufig gestellte Fragen
Prompt Engineering konzentriert sich darauf, eine einzelne Anweisung für ein LLM zu formulieren. Context Engineering ist eine umfassendere Systemdisziplin, die das gesamte Informationsökosystem für ein KI-Modell verwaltet – einschließlich Speicher, Tools und abgerufener Daten –, um die Leistung bei komplexen, zustandsbehafteten Aufgaben zu optimieren.
Context Rot ist der unvorhersehbare Leistungsabfall eines LLM, wenn sein Eingabekontext länger wird. Modelle können plötzlich deutlich ungenauer werden, Teile des Kontexts ignorieren oder halluzinieren. Das zeigt, dass Qualität und sorgfältiges Kontextmanagement wichtiger sind als reine Quantität.
Die vier Kernstrategien sind: 1. Write Context (Informationen außerhalb des Kontextfensters speichern, z.B. Scratchpads oder Speicher), 2. Select Context (nur relevante Informationen abrufen), 3. Compress Context (zusammenfassen oder kürzen, um Platz zu sparen), und 4. Isolate Context (unterteilen mit Multi-Agenten-Systemen oder Sandboxes, um Aufgaben zu trennen).
Arshia ist eine AI Workflow Engineerin bei FlowHunt. Mit einem Hintergrund in Informatik und einer Leidenschaft für KI spezialisiert sie sich darauf, effiziente Arbeitsabläufe zu entwickeln, die KI-Tools in alltägliche Aufgaben integrieren und so Produktivität und Kreativität steigern.
Arshia Kahani
AI Workflow Engineerin
Meistern Sie Context Engineering
Bereit, die nächste Generation von KI-Systemen zu bauen? Entdecken Sie unsere Ressourcen und Tools, um fortgeschrittenes Context Engineering in Ihren Projekten umzusetzen.
Es lebe Context Engineering: Produktionsreife KI-Systeme mit modernen Vektordatenbanken bauen
Erfahren Sie, wie Context Engineering die KI-Entwicklung neu gestaltet, wie sich RAG zu produktionsreifen Systemen entwickelt hat und warum moderne Vektordatenb...
Das Jahrzehnt der KI-Agenten: Karpathy über den AGI-Zeitplan
Entdecken Sie Andrej Karpathys differenzierte Sicht auf AGI-Zeitpläne, KI-Agenten und warum das nächste Jahrzehnt entscheidend für die Entwicklung künstlicher I...
Aufstrebende KI-Agenten-Startups und Disruptoren im Q4 2025: Die Agenten-Ära beginnt
Entdecken Sie die innovativsten KI-Agenten-Startups, die im Q4 2025 die Unternehmensautomatisierung transformieren. Lernen Sie autonome Agenten, kognitive Archi...
15 Min. Lesezeit
AI Agents
Startups
+3
Cookie-Zustimmung Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.