Wie Sie individuelle Knowledge-Base-Seiten in Hugo aus LiveAgent-Tickets erstellen
Erfahren Sie, wie Sie mit KI-Agenten und GitHub-Integration die Erstellung von Knowledge-Base-Artikeln in Hugo direkt aus Kundensupport-Tickets automatisieren.
Automation
Knowledge Base
Hugo
GitHub
AI Agents
Customer Support
Kundensupport-Teams generieren täglich wertvolle Erkenntnisse durch ihre Interaktionen mit Kunden. Diese Fragen, Anliegen und Lösungen sind eine wahre Fundgrube an Informationen, von denen Ihre gesamte Nutzerschaft profitieren könnte – sofern sie richtig dokumentiert werden. Die manuelle Umwandlung von Support-Tickets in ausgearbeitete Knowledge-Base-Artikel ist jedoch zeitaufwändig, repetitiv und wird oft zugunsten dringender Supportanfragen zurückgestellt. Was wäre, wenn Sie diesen gesamten Prozess automatisieren könnten und so aus rohen Kundenanfragen professionell formatierte, SEO-optimierte Wissensdatenbankseiten entstehen, die direkt auf Ihrer Website erscheinen? Genau das machen moderne Automatisierungs-Workflows heute möglich. Durch die Verbindung Ihres LiveAgent-Ticketsystems mit Hugo zur statischen Seitengenerierung und GitHub als Versionskontrolle können Sie eine nahtlose Pipeline schaffen, die Kundenfragen automatisch in durchsuchbaren, auffindbaren Knowledge-Base-Content verwandelt. In diesem umfassenden Leitfaden zeigen wir, wie Sie dieses leistungsstarke Automatisierungssystem aufbauen, welche technische Architektur dahintersteht und wie Sie die Lösung praktisch in Ihrem Unternehmen implementieren.
Was ist Wissensdatenbank-Automatisierung?
Eine Wissensdatenbank ist ein zentrales Informationsarchiv, das Nutzern hilft, Antworten auf häufige Fragen zu finden, ohne direkt den Support kontaktieren zu müssen. Traditionelle Wissensdatenbanken werden manuell aufgebaut – Support-Teams schreiben Artikel, formatieren sie, optimieren sie für Suchmaschinen und veröffentlichen sie über ein Content-Management-System. Dieser Prozess ist arbeitsintensiv und stellt insbesondere für wachsende Unternehmen mit hunderten Anfragen täglich einen Engpass dar. Wissensdatenbank-Automatisierung ändert dieses Paradigma: Künstliche Intelligenz extrahiert relevante Informationen aus Support-Tickets, strukturiert sie nach vordefinierten Vorlagen und veröffentlicht sie direkt auf Ihrer Website. Das Automatisierungssystem agiert als intelligentes Bindeglied zwischen Support-Team und Website, erkennt, welche Tickets verallgemeinerbares Wissen enthalten und verwandelt diese Rohgespräche in ausgearbeitete, professionelle Dokumentation. Das spart nicht nur Zeit, sondern sorgt auch für einheitliches Format, Struktur und SEO-Optimierung aller Knowledge-Base-Artikel. Das System kann auf Ihr Geschäftskontext angepasst werden, vermeidet doppelte Inhalte und pflegt eine konsistente Wissensbasis, die organisch mit jedem bearbeiteten Support-Ticket wächst.
Bereit, Ihr Geschäft zu erweitern?
Starten Sie heute Ihre kostenlose Testversion und sehen Sie innerhalb weniger Tage Ergebnisse.
Warum Wissensdatenbank-Automatisierung für Ihr Unternehmen wichtig ist
Das Business-Case für Wissensdatenbank-Automatisierung ist überzeugend und vielschichtig. Erstens senkt sie das Support-Volumen drastisch, da Kunden eigenständig Antworten finden. Studien zeigen, dass Kunden Self-Service bevorzugen, wenn dieser verfügbar und effektiv ist – eine gut gepflegte Knowledge-Base kann Support-Tickets um 20-30 % reduzieren. Zweitens verbessert sie die Kundenzufriedenheit, da sofortige Antworten auf häufige Fragen bereitstehen, ohne auf eine Support-Reaktion warten zu müssen. Drittens entstehen große SEO-Vorteile: Knowledge-Base-Artikel werden von Suchmaschinen indexiert und können organischen Traffic auf Ihre Website bringen – so werden neue Kunden durch Suchanfragen auf Ihre Inhalte aufmerksam. Viertens sichert sie institutionelles Wissen, das sonst beim Ausscheiden von Teammitgliedern verloren gehen könnte. Jede Support-Interaktion enthält wertvollen Kontext und Lösungen, die dokumentiert zum dauerhaften Wissensbestand Ihres Unternehmens werden. Fünftens ermöglicht sie Ihrem Support-Team, sich auf komplexe, wertschöpfende Themen zu konzentrieren, statt immer wieder dieselben Fragen zu beantworten. Durch die Automatisierung der Knowledge-Base-Erstellung aus Support-Tickets schaffen Sie einen Multiplikator für Ihr Support-Team: Die Zeit, die für Antworten aufgewendet wird, wird zur dokumentierten Wissensbasis für Tausende künftiger Kunden. Schließlich liefert sie wertvolle Daten über die Herausforderungen Ihrer Kunden – diese Insights fließen in Produktentwicklung, Marketing und Kundenschulungsinitiativen ein.
Die Architektur der automatisierten Wissensdatenbank-Erstellung
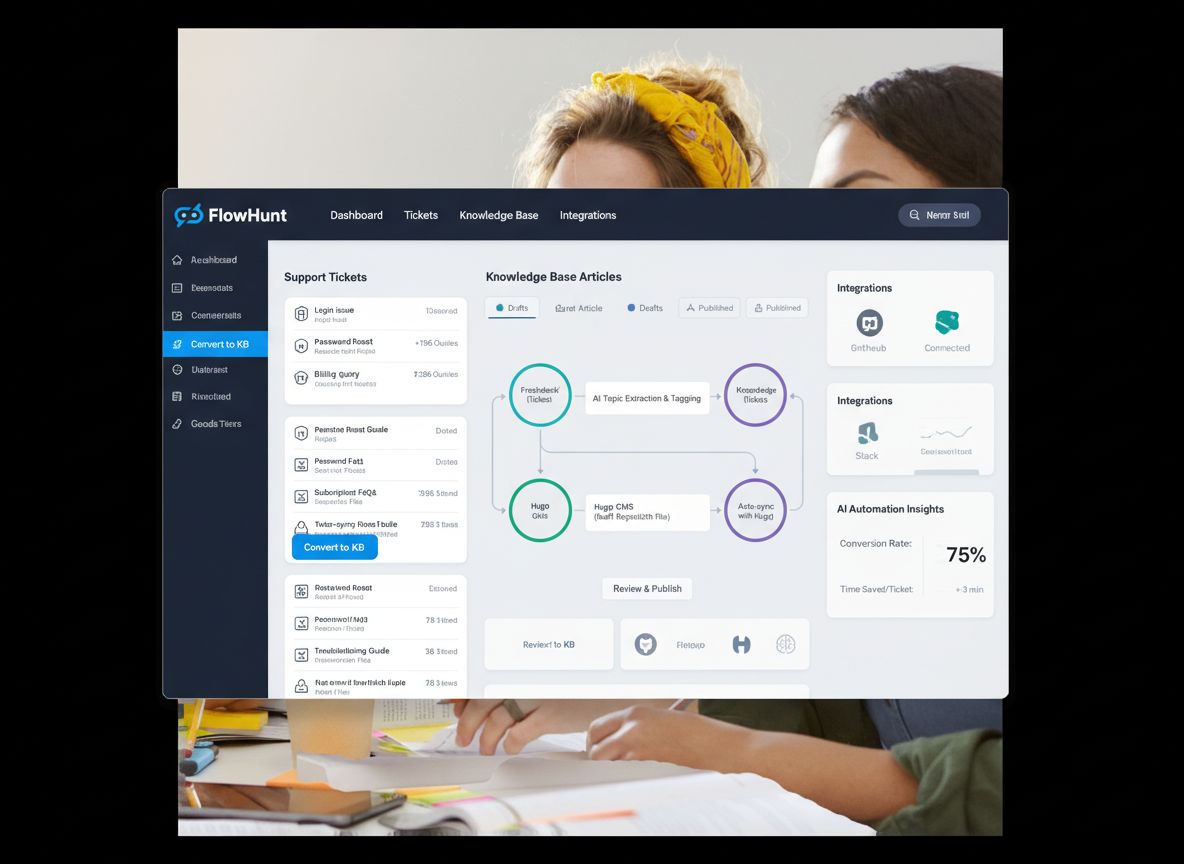
Der Aufbau eines automatisierten Systems für Wissensdatenbanken erfordert die Integration mehrerer Tools und Plattformen in einen durchgängigen Workflow. Das System besteht meist aus vier Hauptkomponenten: einem Ticketsystem (LiveAgent), einem KI-Agenten, der die Tickets verarbeitet, einem Versionskontrollsystem (GitHub) und einem Static-Site-Generator (Hugo). LiveAgent ist die Quelle für Kundenanfragen und speichert alle Supportgespräche inklusive Metadaten wie Tags, Kategorien und Zeitstempel. Der KI-Agent orchestriert den gesamten Prozess – er erhält eine Ticket-ID, holt sämtliche Inhalte und Konversationsverläufe, analysiert, ob das Ticket für eine Veröffentlichung geeignet ist, prüft bestehende Knowledge-Base-Inhalte auf Duplikate, generiert SEO-optimierte Inhalte im richtigen Format und steuert den GitHub-Workflow. GitHub übernimmt das Content-Management und die Versionskontrolle, ermöglicht die Überprüfung, Freigabe und Nachverfolgung aller Artikel. Hugo wandelt die Markdown-Dateien aus GitHub in eine schnelle, sichere und SEO-freundliche Website um. Diese Architektur sorgt für eine klare Trennung der Verantwortlichkeiten: LiveAgent für Support, der KI-Agent für Intelligenz, GitHub für Versionierung und Zusammenarbeit, Hugo für die Präsentation. Der Vorteil: Jede Komponente kann unabhängig gepflegt und aktualisiert werden, ohne die anderen zu stören.
Abonnieren Sie unseren Newsletter
Erhalten Sie die neuesten Tipps, Trends und Angebote kostenlos.
Wie FlowHunt Wissensdatenbank-Automatisierung ermöglicht
FlowHunt stellt die Orchestrierungsschicht bereit, die alle diese Systeme in einem nahtlosen Workflow verbindet. Statt individueller Entwicklung oder komplexer Integrationen können Sie mit FlowHunt den Automatisierungsflow visuell gestalten und LiveAgent, GitHub und Hugo über eine einfache, intuitive Oberfläche verknüpfen. Die Plattform übernimmt Authentifizierung, Fehlerbehandlung, Wiederholungslogik und sämtliche technische Komplexität, die ansonsten erheblichen Entwicklungsaufwand erfordern würde. Mit FlowHunt lassen sich auch anspruchsvolle Automatisierungs-Workflows ohne Programmierkenntnisse erstellen – so wird Wissensdatenbank-Automatisierung auch für Teams ohne eigene Entwicklungsressourcen zugänglich. Die Plattform bietet zudem Gedächtnis- und Kontextverwaltung, so dass Ihr Workflow aus vorherigen Durchläufen lernen und intelligent entscheiden kann, wann neue Artikel erstellt oder bestehende aktualisiert werden. Die GitHub-Integration ermöglicht automatische Pull-Request-Erstellung, so dass Ihr Team Inhalte vor der Veröffentlichung prüfen kann. Dieser Human-in-the-Loop-Ansatz sichert Qualität und kombiniert sie mit der Effizienz der Automatisierung.
Der komplette Workflow: Schritt-für-Schritt Prozess
Die automatisierte Erstellung von Knowledge-Base-Artikeln folgt einer genau definierten Abfolge, bei der jeder Schritt auf dem vorherigen aufbaut und so einen vollständigen, einsatzbereiten Artikel erzeugt. Das Verständnis dieses Prozesses ist entscheidend, um die Lösung erfolgreich zu implementieren.
Schritt 1: Ticket-Abruf und Validierung
Der Workflow beginnt damit, dass Sie eine Ticket-ID aus Ihrem LiveAgent-System bereitstellen. Der KI-Agent ruft daraufhin sofort den vollständigen Ticket-Inhalt ab – einschließlich Betreff, Text, aller Tags und der gesamten Konversationshistorie zwischen Kunde und Support-Team. Diese umfassende Erfassung ist entscheidend, damit die KI den Kontext für die Erstellung relevanter Inhalte hat. Der Agent prüft auch, ob das Ticket genügend Informationen enthält und für die Veröffentlichung geeignet ist. Wenn Ihr Unternehmen beispielsweise viele Demo-Termin-Anfragen erhält, können Sie das System so konfigurieren, dass diese Tickets automatisch übersprungen werden, da sie kein verallgemeinerbares Wissen enthalten. Diese Filterung verhindert, dass Ihre Wissensdatenbank mit administrativen oder transaktionalen Inhalten gefüllt wird, die Nutzern keinen Mehrwert bieten.
Schritt 2: Dublettenprüfung mithilfe von Gedächtnis
Bevor neue Inhalte erstellt werden, prüft das System mithilfe seines Gedächtnisses, ob zu diesem Thema bereits ein ähnlicher Artikel existiert. Dieses Gedächtnis ist eine der wichtigsten Funktionen der Automatisierung, da so doppelte oder nahezu doppelte Artikel vermieden werden, die Nutzer verwirren und Ihre SEO-Bemühungen schwächen. Der KI-Agent durchsucht frühere Tickets und generierte Artikel nach ähnlichen Themen. Wird eine Übereinstimmung gefunden, kann entweder der bestehende Artikel mit neuen Informationen ergänzt oder die Neuerstellung übersprungen werden – je nach Konfiguration. Gibt es kein ähnliches Thema, ergänzt der Agent das Gedächtnis um dieses Ticket und legt einen Vermerk für zukünftige Anfragen an. Dieser Gedächtnis-basierte Ansatz sorgt dafür, dass das System mit jedem bearbeiteten Ticket klüger wird – es entsteht eine umfassende Landkarte Ihrer Wissensbasis, die immer intelligentere Entscheidungen über Inhaltserstellung und Updates ermöglicht.
Schritt 3: Analyse der Knowledge-Base-Struktur
Das System untersucht anschließend Ihr bestehendes Knowledge-Base-Repository, um zu verstehen, wie Inhalte strukturiert, formatiert und organisiert sind. Dieser Schritt ist entscheidend, damit alle Artikel konsistent aufgebaut sind. Der KI-Agent analysiert vorhandene Markdown-Dateien, Frontmatter-Formate, Überschriftenstrukturen und Inhaltsmuster, um die Konventionen Ihrer Wissensdatenbank zu erfassen. Er prüft, wie Artikel kategorisiert werden, welche Metadaten enthalten sind, wie Bilder referenziert werden und welche SEO-Elemente vorhanden sind. Durch die Analyse Ihrer bestehenden Inhalte lernt das System Ihre spezifischen Stil- und Strukturvorgaben und sorgt dafür, dass neue Artikel sich nahtlos einfügen – und nicht als automatisierte Fremdkörper auffallen.
Schritt 4: GitHub-Branch-Management
Um eine saubere Versionskontrolle und nachvollziehbare Review-Prozesse zu gewährleisten, erstellt oder nutzt das System einen bestehenden GitHub-Branch für das Knowledge-Base-Update. Anstatt für jedes einzelne Ticket einen neuen Branch zu erstellen, verwaltet das System die Branches intelligent und hält Ihr Repository übersichtlich. Gibt es bereits einen Branch für Knowledge-Base-Updates, wird dieser genutzt und die neue Datei hinzugefügt. So vermeiden Sie eine Branch-Flut, können aber mehrere Artikel gesammelt in einen Pull Request bringen. Die Branch-Benennung ist meist sprechend, etwa “knowledge-base-updates” oder “kb-automation”, so dass Teammitglieder sofort den Zweck erkennen.
Schritt 5: Inhaltserstellung und Formatierung
Mit dem gesammelten Kontext erstellt der KI-Agent den Knowledge-Base-Artikel. Der generierte Inhalt umfasst ein korrekt formatiertes Frontmatter mit Metadaten wie Titel, Beschreibung, Keywords, Tags, Kategorien, Veröffentlichungsdatum und Call-to-Action-Elementen. Der Artikel selbst folgt einem strukturierten Aufbau, der sowohl für Nutzer als auch für Suchmaschinen optimiert ist: Hauptüberschrift, mehrere H2-Abschnitte mit Frage-basierten Überschriften (wie “Was ist das?”, “Warum sollten wir das tun?”, “Wie wird das gemacht?”) und detaillierte Antworten als Absätze und Aufzählungen. Diese Struktur ist für Featured Snippets und andere Suchmaschinenfunktionen optimiert, die klare Frage-Antwort-Strukturen belohnen. Die Inhalte werden im Markdown-Format erstellt, das Standard bei Hugo und den meisten Static-Site-Generatoren ist – das erleichtert Bearbeitung und Kompatibilität.
Schritt 6: Dateierstellung und Commit
Das System erstellt eine neue Markdown-Datei im Knowledge-Base-Ordner mit einem passenden Dateinamen, der auf dem Thema basiert. Der Dateiname ist in der Regel “slugified” (kleingeschrieben, Bindestriche statt Leerzeichen) und entspricht damit Webstandards. Die Datei enthält das vollständige Frontmatter und den zuvor generierten Inhalt. Nach der Dateierstellung committet das System die Änderungen in den entsprechenden GitHub-Branch mit einer sprechenden Commit-Message, die die ursprüngliche Ticket-ID referenziert. Diese Commit-Nachricht schafft eine dauerhafte Verbindung zwischen Knowledge-Base-Artikel und Kundenanfrage und ermöglicht so Nachvollziehbarkeit und Kontext für die Zukunft.
Schritt 7: Pull Request-Erstellung und Review
Abschließend erstellt das System einen Pull Request vom Knowledge-Base-Branch zum Hauptbranch. Der Pull Request enthält eine Beschreibung der Änderungen, die Ticket-ID, die zur Erstellung geführt hat, und weitere relevante Informationen. Der Pull Request ist der Kontrollpunkt, an dem Ihr Team die Inhalte prüfen, ggf. bearbeiten, die Qualität sichern und die Einhaltung Ihrer Strategie gewährleisten kann. Dieser menschliche Review-Schritt ist essenziell – KI-generierte Inhalte sind zwar meist hochwertig, doch nur menschliche Kontrolle sichert absolute Genauigkeit, Marken- und Stiltreue. Nach der Freigabe wird der Pull Request gemerged, Hugo baut die Seite neu und der Artikel ist live.
Praktische Umsetzung: Ticket-IDs finden und verwenden
Um den Automatisierungs-Workflow zu nutzen, müssen Sie die richtige Ticket-ID aus Ihrem LiveAgent-System identifizieren. LiveAgent zeigt Ticket-IDs an zwei Stellen an: Zum einen direkt im Interface mit dem “Ticket”-Label und der ID, die Sie einfach kopieren können. Zum anderen finden Sie die Ticket-ID meist am Ende der URL, wenn Sie ein Ticket öffnen – dort steht beispielsweise “ID=12345”. Diese ID geben Sie in den FlowHunt-Workflow ein, woraufhin der gesamte Prozess automatisch startet: Das System holt das Ticket, analysiert es, prüft auf Duplikate, generiert den Artikel, erstellt Branch und Pull Request in GitHub und benachrichtigt Ihr Team zur Überprüfung. Die gesamte Verarbeitung ist meist in Sekunden bis wenigen Minuten abgeschlossen – abhängig von Ticket-Komplexität und Umfang Ihrer bestehenden Wissensbasis.
Beschleunigen Sie Ihren Workflow mit FlowHunt
Erleben Sie, wie FlowHunt die Erstellung Ihrer Wissensdatenbank aus Support-Tickets automatisiert – von der Ticketanalyse und Inhaltserstellung bis zur GitHub-Integration und Hugo-Publikation – alles in einem durchgängigen Workflow.
Wenn der Grundworkflow steht, lassen sich zahlreiche Einstellungen für spezielle Anforderungen optimieren. Sie können das System so konfigurieren, dass bestimmte Ticket-Typen anhand von Tags, Kategorien oder Keywords ignoriert werden. Beispielsweise können Sie alle Tickets mit dem Tag “Abrechnung” oder “konto-spezifisch” überspringen lassen, da diese in der Regel kein verallgemeinerbares Wissen enthalten. Sie können auch Schwellenwerte für Artikelqualität oder -länge setzen – ist ein Ticket zu kurz oder enthält zu wenig Informationen, wird es übersprungen. Das Gedächtnissystem kann von einfacher Keyword-Abfrage bis hin zu semantischer Ähnlichkeitsanalyse angepasst werden. Auch das Frontmatter und die Inhaltsstruktur lassen sich individuell gestalten, z. B. mit zusätzlichen Feldern oder verändertem Artikelaufbau. Manche Unternehmen fügen Metadaten wie Schwierigkeitsgrad, Zielgruppe oder verwandte Artikel hinzu. Ebenso kann das System Bilder automatisch einfügen – etwa durch KI-Generierung oder aus Ihrem Asset-Archiv. Für internationale Zielgruppen ist auch die automatische Erstellung in mehreren Sprachen möglich. Sie können auch Benachrichtigungen und Freigabeprozesse konfigurieren – etwa, dass bestimmte Teammitglieder Artikel in speziellen Kategorien freigeben müssen.
Praxisbeispiel: WordPress-Integrationsfehler
Ein praktisches Beispiel aus dem Workflow-Alltag: Ein Kunde reicht ein Support-Ticket zu einem WordPress-Integrationsfehler ein. Das Ticket enthält Fehlermeldungen, Screenshots und eine detaillierte Beschreibung der bisherigen Versuche. Das Support-Team antwortet mit Lösungsschritten und löst das Problem schließlich. Dieses Ticket ist ein idealer Kandidat für die automatische Knowledge-Base-Erstellung. Nach Angabe der Ticket-ID ruft das System die gesamte Konversation ab, analysiert sie und prüft das Gedächtnis. Da noch kein Artikel zu WordPress-Integrationsfehlern existiert, wird dieses Thema aufgenommen und mit der Artikelerstellung fortgefahren. Das System erkennt, dass es für technische Troubleshooting-Artikel eine bestimmte Struktur gibt – mit Abschnitten für Symptome, Ursachen, Lösungen und Prävention. Der generierte Artikel folgt diesem Format und wird so zu einer umfassenden Anleitung, mit der künftige Kunden das Problem eigenständig lösen können. Der Artikel wird im GitHub-Branch erstellt, ein Pull Request generiert, Ihr Team prüft und passt ihn an und merged ihn schließlich. Innerhalb weniger Minuten ist der Artikel live, durch Suchmaschinen indexiert und für Ihre Kunden verfügbar. Sucht nun jemand nach “WordPress-Integrationsfehler” oder hat ein ähnliches Problem, findet er direkt Ihren Artikel und benötigt keinen Supportkontakt mehr.
Erfolgsmessung und ROI
Um die Investition in die Wissensdatenbank-Automatisierung zu rechtfertigen, sollten Sie die Ergebnisse messen. Wichtige Kennzahlen sind die Reduzierung der Support-Tickets zu abgedeckten Themen, der Zuwachs an organischem Suchmaschinen-Traffic, die Zeitersparnis Ihres Support-Teams und die Verbesserung der Kundenzufriedenheitswerte. Sie können tracken, wie viele Kunden Knowledge-Base-Artikel vor einem Supportkontakt nutzen, wie viele Tickets auf solche Artikel verweisen und wie viele Kunden angeben, die benötigte Antwort gefunden zu haben. Auch die Qualität der generierten Artikel lässt sich messen – etwa anhand von Verweildauer, Scrolltiefe und Absprungrate. Wertvolle Artikel zeigen hier hohe Engagement-Werte. Weitere Metriken sind die Anzahl generierter Artikel, die Zeitersparnis gegenüber manueller Erstellung und die Kosteneinsparung durch weniger Supportaufkommen. Die meisten Unternehmen stellen fest, dass sich die Automatisierung durch gesparte Supportkosten und höhere Kundenzufriedenheit schon nach wenigen Monaten selbst trägt.
Fazit
Die Automatisierung der Knowledge-Base-Erstellung aus LiveAgent-Tickets bietet eine große Chance, die Effizienz im Kundensupport zu verbessern, die SEO-Performance Ihrer Website zu steigern und eine wertvolle Ressource zu schaffen, die Ihren Kunden weit über die Erstinteraktion hinaus dient. Mit der Verbindung von LiveAgent, GitHub, Hugo und KI-basierter Automatisierung via FlowHunt entsteht ein System, das rohe Kundenanfragen automatisch in ausgearbeitete, professionelle Knowledge-Base-Artikel verwandelt. Der Workflow ist einfach: Ticket-ID bereitstellen, und das System übernimmt Inhaltserstellung, GitHub-Integration und Pull-Request-Erstellung. Das Gedächtnissystem stellt sicher, dass keine doppelten Inhalte entstehen, während der menschliche Review-Schritt Qualität und Markenkonsistenz wahrt. Mit wachsender Wissensdatenbank wird diese zum immer wertvolleren Asset, das Supportkosten senkt, Kundenzufriedenheit steigert und organischen Traffic generiert. Die Umsetzung ist auch für Teams ohne große technische Ressourcen zugänglich – so steht diese leistungsstarke Automatisierung Unternehmen jeder Größe offen.
Häufig gestellte Fragen
Was ist ein LiveAgent-Ticket?
Ein LiveAgent-Ticket ist eine Kundensupport-Anfrage oder ein Anliegen, das im LiveAgent-Ticketsystem erfasst wird. Jedes Ticket enthält einen Betreff, den Inhalt, Tags und die vollständige Konversationshistorie, die zur Erstellung von Knowledge-Base-Inhalten verwendet werden können.
Wie finde ich meine Ticket-ID in LiveAgent?
Sie können Ihre Ticket-ID auf zwei Arten finden: (1) Suchen Sie im LiveAgent-Interface nach dem 'Ticket'-Label mit der angezeigten ID oder (2) prüfen Sie die URL am Ende, wo 'ID=ihre-ticket-id' angezeigt wird. Kopieren Sie diese ID, um sie im Automatisierungsflow zu verwenden.
Kann der Flow bestimmte Ticket-Typen ignorieren?
Ja, der Flow kann so konfiguriert werden, dass bestimmte Ticket-Typen ignoriert werden. Zum Beispiel können Sie einstellen, dass Demo-Termin-Anfragen übersprungen werden, damit nicht für ähnliche Themen doppelte Knowledge-Base-Seiten erstellt werden.
Was passiert, wenn bereits ein ähnlicher Knowledge-Base-Artikel existiert?
Der Flow nutzt ein Gedächtnis, um zu prüfen, ob ein ähnliches Thema bereits verarbeitet wurde. Falls eine Übereinstimmung gefunden wird, wird der bestehende Artikel bei Bedarf aktualisiert oder die Erstellung übersprungen, um Duplikate zu vermeiden.
Wie integriert sich der Flow mit GitHub?
Der Flow erstellt oder verwendet einen bestehenden GitHub-Branch, generiert eine Markdown-Datei mit korrektem Frontmatter, committed die Änderungen und erstellt einen Pull Request zur Überprüfung, bevor auf den Hauptbranch gemerged wird.
Arshia ist eine AI Workflow Engineerin bei FlowHunt. Mit einem Hintergrund in Informatik und einer Leidenschaft für KI spezialisiert sie sich darauf, effiziente Arbeitsabläufe zu entwickeln, die KI-Tools in alltägliche Aufgaben integrieren und so Produktivität und Kreativität steigern.
Arshia Kahani
AI Workflow Engineerin
Automatisieren Sie Ihre Wissensdatenbank-Erstellung
Verwandeln Sie Kundensupport-Tickets automatisch mit KI-gestützten Workflows von FlowHunt in SEO-optimierte Knowledge-Base-Artikel.
So automatisieren Sie die Ticketbeantwortung in LiveAgent mit FlowHunt
Erfahren Sie, wie Sie FlowHunt AI-Flows mit LiveAgent integrieren, um Kundenanfragen automatisch mit intelligenten Automatisierungsregeln und API-Integration zu...
Erweiterte FlowHunt–LiveAgent-Integration: Sprachsteuerung, Spamfilterung, API-Auswahl und Automatisierungs-Best Practices
Ein technischer Leitfaden zur Beherrschung der erweiterten FlowHunt-Integration mit LiveAgent: Sprachsteuerung, Unterdrückung von Markdown, Spamfilterung, API-V...
Automatischer AI-Ticket-Responder mit Spam-Erkennung bauen
Erfahren Sie, wie Sie ein vollständig automatisiertes Kundensupport-System mit KI-gestützten Ticketantworten und intelligenter Spam-Erkennung mithilfe von FlowH...
17 Min. Lesezeit
AI Automation
Customer Support
+3
Cookie-Zustimmung Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.