
Mensch in der Schleife
Human-in-the-Loop (HITL) ist ein Ansatz in der KI und dem maschinellen Lernen, bei dem menschliche Expertise in das Training, die Feinabstimmung und die Anwendu...
2 Min. Lesezeit
AI
Human-in-the-Loop
+4
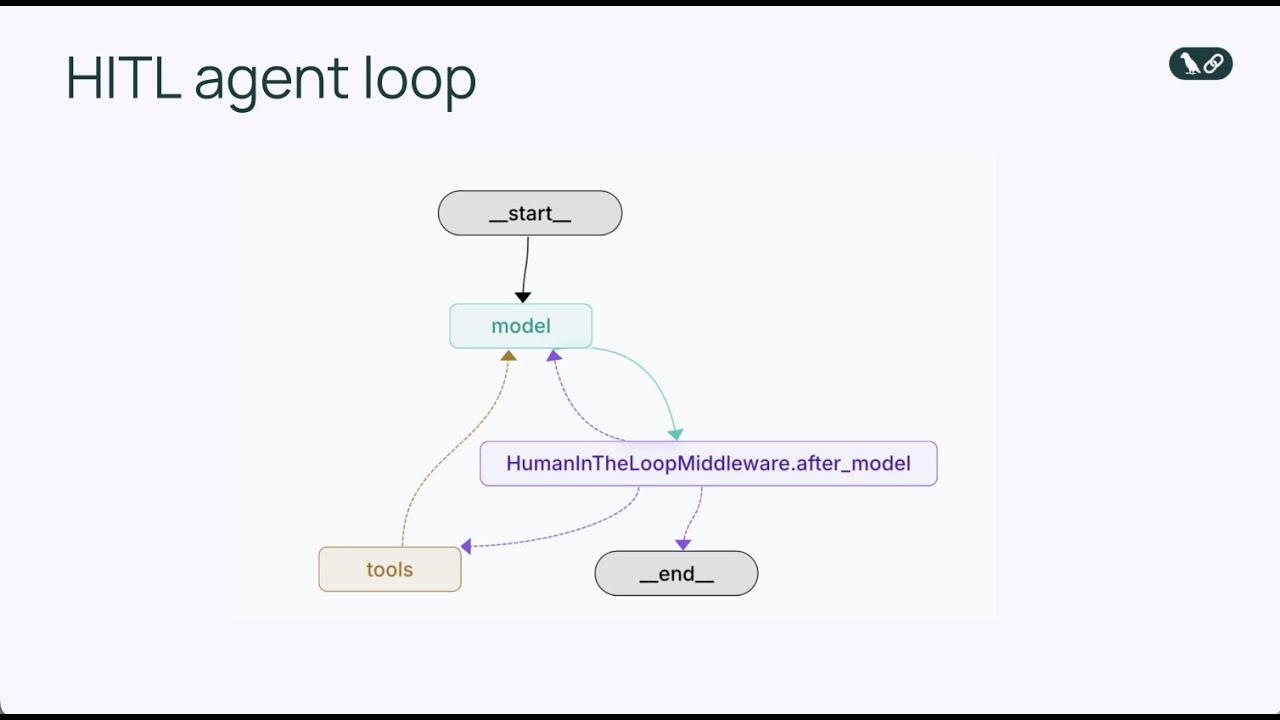
Erfahren Sie, wie Sie Human-in-the-Loop-Middleware in Python mit LangChain implementieren, um KI-Agenten mit Freigabe-, Bearbeitungs- und Ablehnungsfunktionen vor der Ausführung von Tools auszustatten.
Der Bau von KI-Agenten, die Tools autonom ausführen und Aktionen durchführen können, ist mächtig – birgt jedoch inhärente Risiken. Was passiert, wenn ein Agent entscheidet, eine E-Mail mit falschen Informationen zu versenden, eine große Finanztransaktion freizugeben oder kritische Datenbankeinträge zu ändern? Ohne geeignete Schutzmechanismen können autonome Agenten erheblichen Schaden anrichten, bevor jemand bemerkt, was geschehen ist. Genau hier wird Human-in-the-Loop-Middleware unerlässlich. In diesem umfassenden Leitfaden zeigen wir, wie Sie Human-in-the-Loop-Middleware in Python mit LangChain implementieren, damit KI-Agenten vor der Ausführung sensibler Operationen eine menschliche Freigabe abwarten. Sie lernen, wie Sie Freigabe-Workflows hinzufügen, Bearbeitungsmöglichkeiten einbauen und Ablehnungen handhaben – und das, ohne die Effizienz und Intelligenz Ihrer autonomen Systeme einzubüßen.

Bevor wir in die Human-in-the-Loop-Middleware einsteigen, ist es wichtig, das Grundprinzip von KI-Agenten zu verstehen. Ein KI-Agent arbeitet in einer kontinuierlichen Schleife, die sich wiederholt, bis er entscheidet, dass seine Aufgabe abgeschlossen ist. Die zentrale Agenten-Schleife besteht aus drei Hauptkomponenten: einem Sprachmodell, das über den nächsten Schritt nachdenkt, einer Sammlung von Tools, die der Agent zur Ausführung nutzen kann, und einem Zustandsmanagement, das den Gesprächsverlauf und relevante Kontexte verfolgt. Der Agent erhält zunächst eine Eingabe vom Nutzer, das Sprachmodell analysiert diese zusammen mit den verfügbaren Tools und entscheidet, ob ein Tool aufgerufen oder eine finale Antwort gegeben werden soll. Entscheidet sich das Modell für einen Tool-Aufruf, wird dieses Tool ausgeführt und das Ergebnis in den Gesprächsverlauf eingefügt. Dieser Zyklus – Modell-Überlegung, Tool-Auswahl, Tool-Ausführung, Ergebnisintegration – wiederholt sich, bis das Modell entscheidet, dass keine weiteren Tool-Aufrufe nötig sind, und die endgültige Antwort an den Nutzer gibt.
Dieses einfache, aber leistungsfähige Muster ist in den letzten Jahren zur Grundlage für Hunderte von KI-Agenten-Frameworks geworden. Die Eleganz der Agenten-Schleife liegt in ihrer Flexibilität: Durch die Änderung der verfügbaren Tools kann ein Agent völlig unterschiedliche Aufgaben übernehmen. Ein Agent mit E-Mail-Tools kann Kommunikation managen, ein Agent mit Datenbank-Tools kann Daten abfragen und aktualisieren, ein Agent mit Finanz-Tools kann Transaktionen durchführen. Doch genau diese Flexibilität birgt auch Risiken. Da die Agenten-Schleife autonom operiert, gibt es keinen eingebauten Mechanismus, um zu pausieren und einen Menschen zu fragen, ob eine bestimmte Aktion wirklich ausgeführt werden soll. Das Modell könnte beschließen, eine E-Mail zu senden, eine Datenbank-Abfrage auszuführen oder eine Finanztransaktion zu genehmigen – und bis ein Mensch bemerkt, was geschehen ist, ist die Aktion bereits abgeschlossen. In Produktionsumgebungen werden hier die Schwächen der grundlegenden Agenten-Schleife deutlich.
Starten Sie heute Ihre kostenlose Testversion und sehen Sie innerhalb weniger Tage Ergebnisse.
Mit steigender Leistungsfähigkeit und zunehmendem Einsatz von KI-Agenten in realen Geschäftsprozessen wird menschliche Kontrolle immer wichtiger. Die Tragweite autonomer Agentenaktionen variiert stark je nach Kontext. Manche Tool-Aufrufe sind risikoarm und können ohne menschliche Prüfung sofort ausgeführt werden – etwa das Lesen einer E-Mail oder das Abrufen von Daten aus einer Datenbank. Andere hingegen sind hochriskant und potenziell unumkehrbar, zum Beispiel das Versenden von Nachrichten im Namen eines Nutzers, das Überweisen von Geldern, das Löschen von Datensätzen oder das Eingehen von Verpflichtungen, die eine Organisation binden. In Produktionssystemen kann ein Fehler eines Agenten bei einer kritischen Operation enorme Folgen haben. Eine unglücklich formulierte E-Mail an den falschen Empfänger kann Geschäftsbeziehungen schädigen. Ein fehlerhaft genehmigtes Budget verursacht finanzielle Verluste. Ein versehentlich gelöschter Datenbankeintrag kann Datenverlust bedeuten, der erst nach Stunden oder Tagen aus Backups wiederhergestellt werden kann.
Neben den unmittelbaren operationellen Risiken gibt es auch Compliance- und regulatorische Anforderungen. Viele Branchen schreiben vor, dass bestimmte Entscheidungen menschliches Urteil und Freigabe benötigen. Finanzinstitute müssen Transaktionen ab bestimmten Beträgen menschlich prüfen. Im Gesundheitswesen ist menschliche Kontrolle bei bestimmten automatisierten Entscheidungen Pflicht. Anwaltskanzleien müssen sicherstellen, dass Kommunikationen vor dem Versand im Namen von Mandanten geprüft werden. Diese regulatorischen Vorgaben sind kein bürokratischer Ballast – sie existieren, weil die Folgen vollautonomer Entscheidungen in diesen Bereichen gravierend sein können. Darüber hinaus liefert menschliche Kontrolle wertvolles Feedback, das zur Verbesserung des Agenten beiträgt. Wenn ein Mensch die vorgeschlagene Aktion prüft und genehmigt oder bearbeitet, kann dieses Feedback verwendet werden, um Prompts zu verfeinern, die Tool-Auswahl-Logik anzupassen oder die zugrunde liegenden Modelle nachzutrainieren. So entsteht ein positiver Kreislauf, in dem der Agent zuverlässiger wird und besser auf die spezifischen Anforderungen und das Risikoprofil der Organisation abgestimmt wird.
Human-in-the-Loop-Middleware ist eine spezialisierte Komponente, die die Agenten-Schleife an einer entscheidenden Stelle abfängt: direkt vor der Ausführung eines Tools. Anstatt dem Agenten zu erlauben, einen Tool-Aufruf sofort auszuführen, pausiert die Middleware und präsentiert die vorgeschlagene Aktion einem Menschen zur Überprüfung. Der Mensch hat dann mehrere Möglichkeiten zu reagieren: Er kann die Aktion genehmigen (sie exakt wie vorgeschlagen ausführen lassen), die Aktion bearbeiten (Parameter anpassen, etwa Empfängeradresse oder Nachrichtentext ändern) oder die Aktion ganz ablehnen und dem Agenten Feedback geben, warum die Aktion ungeeignet war und er einen neuen Ansatz vorschlagen soll. Dieser dreistufige Entscheidungsmechanismus – genehmigen, bearbeiten, ablehnen – bietet einen flexiblen Rahmen für verschiedene Anforderungen an menschliche Kontrolle.
Die Middleware erweitert die Standard-Agenten-Schleife um einen zusätzlichen Entscheidungspunkt. Im Grundmodell lautet die Sequenz: Modell ruft Tools auf → Tools werden ausgeführt → Ergebnisse gehen zurück ans Modell. Mit Human-in-the-Loop-Middleware wird daraus: Modell ruft Tools auf → Middleware fängt ab → Mensch prüft → Mensch entscheidet (genehmigen/bearbeiten/ablehnen) → wenn genehmigt oder bearbeitet, Tool wird ausgeführt → Ergebnis geht zurück ans Modell. Dieser menschliche Entscheidungspunkt unterbricht die Agenten-Schleife nicht, sondern ergänzt sie um ein Sicherheitsventil. Die Middleware ist konfigurierbar – Sie können exakt festlegen, welche Tools eine menschliche Überprüfung auslösen und welche automatisch laufen dürfen. Sie könnten beispielsweise alle E-Mail-Tools unterbrechen, aber Lesezugriffe auf die Datenbank ohne Prüfung erlauben. So stellen Sie sicher, dass menschliche Kontrolle gezielt dort greift, wo sie nötig ist, ohne Routineoperationen unnötig zu verlangsamen.
Erhalten Sie die neuesten Tipps, Trends und Angebote kostenlos.
Wenn die Human-in-the-Loop-Middleware die Tool-Ausführung eines Agenten unterbricht, hat der menschliche Prüfer drei Hauptmöglichkeiten zu reagieren – jede davon erfüllt eine eigene Funktion im Freigabe-Workflow. Das Verständnis dieser drei Antworttypen ist entscheidend für die Gestaltung effektiver Human-in-the-Loop-Systeme.
Genehmigung ist die einfachste Antwort. Prüft ein Mensch einen vorgeschlagenen Tool-Aufruf und befindet ihn für angemessen, gibt er die Genehmigung. Damit signalisiert er der Middleware, dass das Tool mit exakt den vom Agenten vorgeschlagenen Parametern ausgeführt werden soll. Im Fall eines E-Mail-Assistenten bedeutet die Genehmigung, dass der Entwurf in Ordnung ist und wie vorgesehen verschickt werden kann. Genehmigung ist der Weg des geringsten Widerstands – die vorgeschlagene Aktion wird ohne Änderung ausgeführt. Dies ist sinnvoll, wenn der Agent gute Arbeit geleistet hat und der Prüfer einverstanden ist. Genehmigungen werden meist schnell erteilt, was wichtig ist, damit menschliche Kontrolle nicht zum Flaschenhals wird.
Bearbeitung ist differenzierter: Sie signalisiert, dass der Ansatz des Agenten im Prinzip richtig ist, aber Details angepasst werden müssen. Gibt ein Mensch eine Bearbeitungsantwort, lehnt er die Aktion nicht ab, sondern verfeinert die Ausführung. Im E-Mail-Beispiel könnte das bedeuten, den Empfänger zu ändern, die Betreffzeile zu überarbeiten oder den Text anzupassen. Das Wesentliche an der Bearbeitung ist, dass die Tool-Parameter geändert werden, der Tool-Aufruf aber derselbe bleibt. Der Agent schlägt den Versand einer E-Mail vor, der Mensch stimmt dem zu, möchte aber den Inhalt oder den Empfänger anpassen. Nach der Bearbeitung wird das Tool mit den neuen Parametern ausgeführt und das Ergebnis an den Agenten zurückgegeben. Das ist besonders wertvoll, weil der Agent Aktionen vorschlagen kann, der Mensch aber mit seiner Expertise Feinschliff gibt.
Ablehnung ist die einschneidenste Antwort, denn sie verhindert nicht nur die Ausführung, sondern gibt dem Agenten auch Feedback, warum die Aktion ungeeignet war. Eine Ablehnung bedeutet: Die vorgeschlagene Aktion soll gar nicht ausgeführt werden, stattdessen bekommt der Agent Hinweise, wie er sein Vorgehen überdenken soll. Im E-Mail-Beispiel könnte die Ablehnung erfolgen, wenn der Agent eine Zustimmung zu einem großen Budgetantrag ohne ausreichende Details vorschlägt. Der Mensch lehnt ab und gibt eine Nachricht zurück, dass mehr Informationen nötig sind. Diese Ablehnungsnachricht wird Teil des Agentenkontexts; der Agent kann das Feedback verarbeiten und einen neuen Vorschlag machen, zum Beispiel eine E-Mail, die weitere Details einfordert. Ablehnungen sind wichtig, um zu verhindern, dass der Agent wiederholt ungeeignete Aktionen vorschlägt. Durch klares Feedback helfen Sie dem Agenten, seine Entscheidungen zu verbessern.
Sehen wir uns eine konkrete Implementierung der Human-in-the-Loop-Middleware mit LangChain und Python an. Unser Beispiel ist ein E-Mail-Assistent – ein praxisnahes Szenario, das den Wert menschlicher Kontrolle gut illustriert. Der Assistent kann E-Mails im Namen eines Nutzers versenden; die Middleware sorgt dafür, dass alle E-Mails vor dem Versand geprüft werden.
Zuerst definieren wir das E-Mail-Tool, das unser Agent nutzt. Es nimmt drei Parameter: Empfängeradresse, Betreffzeile und Nachrichtentext. Das Tool ist simpel – es steht für die Aktion, eine E-Mail zu senden. In einer echten Anwendung würde es mit Diensten wie Gmail oder Outlook interagieren; für das Beispiel genügt eine einfache Funktion:
def send_email(recipient: str, subject: str, body: str) -> str:
"""Send an email to the specified recipient."""
return f"Email sent to {recipient} with subject '{subject}'"
Nun erstellen wir einen Agenten, der dieses Tool verwendet. Wir nutzen GPT-4 als Sprachmodell und geben einen System-Prompt, der klarmacht, dass der Agent ein hilfreicher E-Mail-Assistent ist. Der Agent wird mit dem E-Mail-Tool initialisiert:
from langchain.agents import create_agent
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-4o")
tools = [send_email]
agent = create_agent(
model=model,
tools=tools,
system_prompt="Du bist ein hilfreicher E-Mail-Assistent für Sydney. Du kannst im Namen des Nutzers E-Mails versenden."
)
Bis hierhin kann der Agent E-Mails versenden – allerdings ohne menschliche Kontrolle. Jetzt fügen wir die Human-in-the-Loop-Middleware hinzu. Die Implementierung ist überraschend einfach und erfordert nur zwei zusätzliche Zeilen Code:
from langchain.agents.middleware import HumanInTheLoopMiddleware
agent = create_agent(
model=model,
tools=tools,
system_prompt="Du bist ein hilfreicher E-Mail-Assistent für Sydney. Du kannst im Namen des Nutzers E-Mails versenden.",
middleware=[
HumanInTheLoopMiddleware(
interrupt_on={"send_email": True}
)
]
)
Mit dem Hinzufügen der HumanInTheLoopMiddleware und interrupt_on={"send_email": True} weisen wir den Agenten an, vor jedem send_email-Aufruf zu pausieren und auf eine menschliche Entscheidung zu warten. Der Wert True bedeutet, dass alle Aufrufe dieses Tools unterbrochen werden. Für mehr Kontrolle könnten Sie erlaubte Entscheidungstypen oder eigene Beschreibungen angeben.
Nach der Integration testen wir die Middleware mit einem risikoarmen Beispiel. Angenommen, ein Nutzer bittet den Agenten, auf eine freundliche E-Mail einer Kollegin namens Alice zu antworten, die ein Treffen zum Kaffee vorschlägt. Der Agent verarbeitet die Anfrage und schlägt eine entsprechende Antwort vor:
send_email mit Parametern wie recipient=“alice@example.com
”, subject=“Kaffee nächste Woche?”, body=“Ich würde mich freuen, nächste Woche mit dir Kaffee zu trinken!” auf.Dieses Beispiel demonstriert den Genehmigungsweg. Die menschliche Kontrolle bietet eine Sicherheitsstufe, ohne den Prozess nennenswert zu verzögern. Bei risikoarmen Aktionen erfolgt die Freigabe meist sehr zügig.
Nun ein Szenario mit höherem Risiko, bei dem die Bearbeitung wertvoll ist. Der Agent soll auf eine E-Mail eines Startup-Partners antworten, der die Unterschrift unter ein Ingenieursbudget über 1 Million Dollar für Q1 erbitten möchte. Das ist eine weitreichende Entscheidung. Der Agent schlägt vielleicht eine E-Mail vor wie: “Ich habe den Vorschlag für das 1-Million-Dollar-Ingenieursbudget für Q1 geprüft und genehmigt.”
Beim Erreichen des menschlichen Prüfers erkennt dieser, dass es sich um eine bedeutende finanzielle Verpflichtung handelt, die nicht leichtfertig genehmigt werden sollte. Der Prüfer will die Aktion nicht komplett ablehnen, aber die Antwort vorsichtiger formulieren. Er gibt eine Bearbeitungs-Antwort und ändert den Text in: “Vielen Dank für den Vorschlag. Ich möchte die Details vor einer Freigabe sorgfältig prüfen. Können Sie mir bitte eine Aufschlüsselung der Budgetverwendung senden?”
So sieht eine Bearbeitungs-Antwort im Code aus:
edit_decision = {
"type": "edit",
"edited_action": {
"name": "send_email",
"args": {
"recipient": "partner@startup.com",
"subject": "Q1 Ingenieursbudget-Vorschlag",
"body": "Vielen Dank für den Vorschlag. Ich möchte die Details vor einer Freigabe sorgfältig prüfen. Können Sie mir bitte eine Aufschlüsselung der Budgetverwendung senden?"
}
}
}
Bei einer Bearbeitungs-Antwort führt die Middleware das Tool mit den angepassten Parametern aus. Die E-Mail wird mit dem überarbeiteten, angemesseneren Inhalt versendet. Das verdeutlicht die Stärke der Bearbeitungs-Antwort: Der Mensch kann den Vorschlag des Agenten nutzen und gleichzeitig sicherstellen, dass die finale Aktion den Standards des Unternehmens entspricht.
Die Ablehnungs-Antwort ist besonders mächtig, denn sie verhindert nicht nur eine unpassende Aktion, sondern liefert auch konstruktives Feedback zur Verbesserung der Agentenlogik. Bleiben wir beim Beispiel der Budgetfreigabe: Der Agent schlägt vor, das 1-Million-Dollar-Budget für Q1 zu genehmigen.
Der Prüfer erkennt, dass das zu voreilig ist. Eine solche Verpflichtung darf nicht ohne gründliche Prüfung erfolgen. Der Mensch möchte nicht einfach nur den Text bearbeiten, sondern das gesamte Vorgehen ablehnen und den Agenten um einen neuen Ansatz bitten. Das Feedback könnte lauten:
reject_decision = {
"type": "reject",
"message": "Ich kann dieses Budget ohne weitere Informationen nicht freigeben. Bitte verfassen Sie eine E-Mail, in der um eine detaillierte Aufschlüsselung des Vorschlags gebeten wird, einschließlich der Mittelverwendung pro Team und erwarteter Ergebnisse."
}
Die Middleware führt das Tool nicht aus, sondern gibt die Ablehnungsnachricht in den Agentenkontext zurück. Der Agent erkennt, dass sein Vorschlag abgelehnt wurde, versteht den Grund und kann einen neuen, angemesseneren Vorschlag machen – etwa eine E-Mail, die mehr Details anfordert. Der Mensch kann diesen neuen Vorschlag dann erneut prüfen, bearbeiten oder erneut ablehnen.
Dieser iterative Prozess – Vorschlag, Überprüfung, Ablehnung mit Feedback, neuer Vorschlag – ist einer der größten Vorteile von Human-in-the-Loop-Middleware. So entsteht eine Zusammenarbeit, in der Geschwindigkeit und Logik des Agenten mit menschlichem Urteilsvermögen und Fachwissen kombiniert werden.
Erleben Sie, wie FlowHunt Ihre KI-Content- und SEO-Workflows automatisiert – von der Recherche und Content-Erstellung bis hin zu Veröffentlichung und Analyse – alles an einem Ort.
Während die Grundimplementierung der Human-in-the-Loop-Middleware einfach ist, bietet LangChain weitergehende Konfigurationsmöglichkeiten, mit denen Sie exakt steuern können, wann und wie unterbrochen wird. Eine wichtige Option ist das Festlegen erlaubter Entscheidungstypen pro Tool. Sie könnten zum Beispiel für E-Mails Genehmigung und Bearbeitung erlauben, aber keine Ablehnung, oder für Finanztransaktionen alle drei, für Lesezugriffe nur Genehmigung.
Ein Beispiel für eine feinere Konfiguration:
from langchain.agents.middleware import HumanInTheLoopMiddleware
agent = create_agent(
model=model,
tools=tools,
middleware=[
HumanInTheLoopMiddleware(
interrupt_on={
"send_email": {
"allowed_decisions": ["approve", "edit", "reject"]
},
"read_database": False, # Automatische Ausführung, keine Unterbrechung
"delete_record": {
"allowed_decisions": ["approve", "reject"] # Keine Bearbeitung bei Löschen
}
}
)
]
)
Hier werden E-Mails unterbrochen und alle drei Entscheidungstypen erlaubt. Leseoperationen laufen automatisch. Löschoperationen werden unterbrochen, erlauben aber keine Bearbeitung – der Mensch kann nur genehmigen oder ablehnen. Damit wird menschliche Kontrolle gezielt und effizient eingesetzt.
Ein weiteres Feature ist die Möglichkeit, eigene Beschreibungen für Unterbrechungen zu geben. Standardmäßig bietet die Middleware eine allgemeine Beschreibung wie “Tool-Ausführung erfordert Freigabe.” Sie können diese anpassen, um spezifischeren Kontext zu liefern:
HumanInTheLoopMiddleware(
interrupt_on={
"send_email": {
"allowed_decisions": ["approve", "edit", "reject"],
"description": "E-Mail-Versand erfordert menschliche Freigabe vor der Ausführung"
}
}
)
Ein entscheidender Punkt bei der Implementierung von Human-in-the-Loop-Middleware ist der Einsatz eines Checkpointers. Ein Checkpointer speichert den Zustand des Agenten zum Zeitpunkt der Unterbrechung und ermöglicht so das spätere Fortsetzen des Workflows. Das ist wichtig, weil menschliche Entscheidungen nicht sofort erfolgen – zwischen Unterbrechung und Entscheidung kann Zeit vergehen. Ohne Checkpointer würde der Zustand des Agenten in dieser Zeit verloren gehen und der Workflow ließe sich nicht korrekt fortsetzen.
LangChain bietet verschiedene Checkpointer. Für Entwicklung und Test genügt ein In-Memory-Checkpointer:
from langgraph.checkpoint.memory import InMemorySaver
checkpointer = InMemorySaver()
agent = create_agent(
model=model,
tools=tools,
checkpointer=checkpointer,
middleware=[
HumanInTheLoopMiddleware(
interrupt_on={"send_email": True}
)
]
)
In Produktivsystemen sollten Sie einen persistenten Checkpointer verwenden, der den Zustand etwa in einer Datenbank oder im Dateisystem speichert. Der Checkpointer hält den vollständigen Verlauf des Agentenzustands fest, inklusive Gesprächshistorie, Tool-Aufrufen und deren Ergebnissen. Gibt ein Mensch eine Entscheidung (genehmigen, bearbeiten, ablehnen), nutzt die Middleware den Checkpointer, um den gespeicherten Zustand abzurufen, die Entscheidung anzuwenden und die Agenten-Schleife fortzusetzen.
Human-in-the-Loop-Middleware eignet sich für zahlreiche reale Szenarien, in denen autonome Agenten agieren, deren Aktionen aber menschlicher Kontrolle bedürfen. Im Finanzbereich können Agenten, die Transaktionen abwickeln, Kredite genehmigen oder Investitionen verwalten, durch die Middleware sicherstellen, dass kritische Entscheidungen von Menschen geprüft werden. Im Gesundheitswesen sorgt Middleware dafür, dass Empfehlungen zu Behandlungen oder Zugriffe auf Patientendaten den Vorschriften entsprechen. In der Rechtsberatung garantiert sie, dass Entwürfe oder vertrauliche Dokumente von Anwälten kontrolliert werden. Im Kundenservice sorgt sie dafür, dass Rückerstattungen, Zusagen an Kunden oder Eskalationen konform mit Unternehmensrichtlinien sind.
Abseits branchenspezifischer Anwendungen ist die Middleware überall sinnvoll, wo Fehler eines Agenten gravierende Folgen haben können – zum Beispiel bei Content-Moderation (Löschen von Nutzerinhalten), HR-Prozessen (Personalentscheidungen), oder Supply-Chain-Systemen (Bestellungen, Lageranpassungen). Allen Szenarien gemeinsam ist: Die vorgeschlagenen Aktionen des Agenten haben echte Auswirkungen, die eine menschliche Überprüfung rechtfertigen.
Es lohnt sich, die Human-in-the-Loop-Middleware mit anderen Methoden der menschlichen Kontrolle zu vergleichen. Eine Alternative ist, alle Agentenaktionen nach Ausführung zu prüfen. Das Problem: Zu diesem Zeitpunkt ist die Aktion bereits erfolgt und lässt sich nur schwer oder gar nicht rückgängig machen – die E-Mail ist raus, der Datensatz gelöscht, die Überweisung gebucht. Die Middleware verhindert irreversible Aktionen im Vorfeld.
Eine andere Alternative ist, Menschen alle Aufgaben manuell erledigen zu lassen, die Agenten übernehmen könnten – damit geht jedoch der Nutzen der Automatisierung verloren. Agenten bringen Vorteile, weil sie Routinearbeiten effizient erledigen und Menschen für strategische Aufgaben entlasten. Middleware soll das richtige Gleichgewicht schaffen: Routinearbeiten automatisieren, bei kritischen Vorgängen pausieren.
Drittens gibt es sogenannte Guardrails oder Validierungsregeln, die Agenten an unpassenden Aktionen hindern. Beispielsweise könnte eine Regel den Versand von E-Mails an externe Adressen verbieten oder Löschungen ohne Bestätigung verhindern. Guardrails sind nützlich und sollten zusätzlich zur Middleware genutzt werden, haben aber Grenzen: Sie sind regelbasiert und können nicht alle Kontexte abdecken. Menschliches Urteilsvermögen ist flexibler – deshalb ist Human-in-the-Loop-Middleware so wertvoll.
Für eine effektive und effiziente Implementierung von Human-in-the-Loop-Middleware gibt es einige bewährte Vorgehensweisen. Erstens: Wählen Sie strategisch aus, welche Tools unterbrochen werden. Wird jeder Tool-Aufruf unterbrochen, entstehen Flaschenhälse. Konzentrieren Sie sich auf teure, risikoreiche oder kritische Tools. Leseoperationen benötigen meist keine Kontrolle, Schreiboperationen oder externe Aktionen schon.
Zweitens: Geben Sie Prüfern klaren Kontext. Bei einer Unterbrechung muss der Mensch verstehen, welche Aktion vorgeschlagen wird und warum. Machen Sie die Beschreibung der Unterbrechung verständlich und zeigen Sie relevante Informationen – etwa den vollständigen E-Mail-Text oder Details zum zu löschenden Datensatz.
Drittens: Halten Sie den Freigabeprozess so reibungslos wie möglich. Menschen genehmigen schneller, wenn der Prozess einfach ist und wenig Eingaben erfordert. Bieten Sie klare Buttons für Genehmigen, Bearbeiten und Ablehnen. Wenn Bearbeitung möglich ist, sollten die Parameter leicht anpassbar sein, ohne dass Kenntnisse des Codes nötig sind.
Viertens: Nutzen Sie Ablehnungsfeedback gezielt. Erläutern Sie bei Ablehnung, warum die Aktion ungeeignet ist und was der Agent stattdessen tun soll. So helfen Sie dem Agenten, seine Entscheidungen zu verbessern und sich an Ihre Standards anzupassen.
Fünftens: Analysieren Sie Muster bei Unterbrechungen. Behalten Sie im Blick, welche Tools oft unterbrochen werden, welche Entscheidungen am häufigsten fallen und wie lange der Freigabeprozess dauert. Diese Daten helfen, Konfigurationen zu optimieren und die Agentenlogik zu verbessern.
Für Unternehmen, die Human-in-the-Loop-Workflows skalierbar einsetzen möchten, bietet FlowHunt eine umfassende Plattform, die sich nahtlos mit LangChain-Middleware integriert. FlowHunt ermöglicht es, KI-Agenten mit integrierten Freigabe-Workflows zu erstellen, zu betreiben und zu verwalten. Sie können festlegen, welche Tools menschliche Freigabe erfordern, die Freigabeoberfläche anpassen und alle Entscheidungen für Compliance und Audits nachverfolgen. Die Plattform übernimmt das komplexe Zustandsmanagement, Checkpointing und Workflow-Orchestrierung, sodass Sie sich auf die Entwicklung effektiver Agenten und passender Freigaberichtlinien konzentrieren können. Dank Integration mit LangChain nutzen Sie die volle Power der Middleware und profitieren gleichzeitig von Benutzerfreundlichkeit und Zuverlässigkeit auf Enterprise-Niveau.
Human-in-the-Loop-Middleware ist eine entscheidende Brücke zwischen der Effizienz autonomer KI-Agenten und der Notwendigkeit menschlicher Kontrolle in produktiven Systemen. Durch Freigabe-Workflows, Bearbeitungsmöglichkeiten und Ablehnungsfeedback können Sie Agenten entwickeln, die leistungsfähig UND sicher sind. Das Drei-Wege-Entscheidungsmodell – genehmigen, bearbeiten, ablehnen – bietet Flexibilität für verschiedene Anforderungen, von schnellen Freigaben bei Routineaufgaben bis zur gründlichen Prüfung und Anpassung bei kritischen Entscheidungen. Die Implementierung ist unkompliziert und erfordert nur wenige Zeilen Code, hat aber einen erheblichen Einfluss auf Zuverlässigkeit und Sicherheit des Gesamtsystems. Mit zunehmender Leistungsfähigkeit und Verbreitung von KI-Agenten wird Human-in-the-Loop-Middleware zum unverzichtbaren Bestandteil verantwortungsvoller KI-Anwendungen. Egal ob Sie E-Mail-Assistenten, Finanzsysteme, Gesundheitsanwendungen oder andere Agenten mit realen Auswirkungen bauen – die Middleware bietet das Fundament, um menschliches Urteilsvermögen im Zentrum Ihrer Automatisierungs-Workflows zu bewahren.
Arshia ist eine AI Workflow Engineerin bei FlowHunt. Mit einem Hintergrund in Informatik und einer Leidenschaft für KI spezialisiert sie sich darauf, effiziente Arbeitsabläufe zu entwickeln, die KI-Tools in alltägliche Aufgaben integrieren und so Produktivität und Kreativität steigern.

Erstellen Sie intelligente Agenten mit integrierten Freigabe-Workflows und menschlicher Kontrolle. FlowHunt erleichtert die Umsetzung von Human-in-the-Loop-Automatisierung für Ihre Geschäftsprozesse.
Human-in-the-Loop (HITL) ist ein Ansatz in der KI und dem maschinellen Lernen, bei dem menschliche Expertise in das Training, die Feinabstimmung und die Anwendu...
Erfahren Sie, wie die Middleware-Architektur von LangChain 1.0 die Agentenentwicklung revolutioniert und es Entwicklern ermöglicht, leistungsstarke, erweiterbar...

Entdecken Sie die Bedeutung und Anwendung von Human in the Loop (HITL) in KI-Chatbots, bei denen menschliche Expertise KI-Systeme für höhere Genauigkeit, ethisc...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.