
Intelligente Agenten
Ein intelligenter Agent ist eine autonome Entität, die darauf ausgelegt ist, ihre Umgebung mittels Sensoren wahrzunehmen und über Aktuatoren auf diese Umgebung ...
6 Min. Lesezeit
AI
Intelligent Agents
+4

Entdecken Sie die 12 Faktoren für den Aufbau robuster, skalierbarer AI-Agenten: von der Umwandlung natürlicher Sprache und Prompt-Ownership bis hin zur Mensch-KI-Zusammenarbeit und stateless Design. Entwickeln Sie produktionsreife AI-Systeme mit echtem geschäftlichem Mehrwert.
Bevor wir auf die Faktoren eingehen, wollen wir klären, was wir unter „AI-Agenten“ verstehen. Im Kern sind dies Systeme, die natürliche Sprachbefehle interpretieren, kontextbasiert Entscheidungen treffen und konkrete Aktionen über Tools oder APIs ausführen – und dabei konsistente, fortlaufende Interaktionen aufrechterhalten.
Die leistungsfähigsten Agenten verbinden die Argumentationsfähigkeiten von Sprachmodellen mit der Zuverlässigkeit deterministischen Codes. Dieses Gleichgewicht zu erreichen, erfordert jedoch durchdachtes Design – und genau darauf zielen diese Faktoren ab.
Die Fähigkeit, natürliche Sprachbefehle in strukturierte Tool-Aufrufe umzuwandeln, steht im Zentrum der Agentenfunktionalität. Das ermöglicht es einem Agenten, einen einfachen Befehl wie „Erstelle einen Zahlungslink für 750 $ an Terri für das Februar AI Tinkerers Meetup“ in einen korrekt formatierten API-Aufruf zu übersetzen.

{
"function": {
"name": "create_payment_link",
"parameters": {
"amount": 750,
"customer": "cust_128934ddasf9",
"product": "prod_8675309",
"price": "prc_09874329fds",
"quantity": 1,
"memo": "Hey Jeff - see below for the payment link for the February AI Tinkerers meetup"
}
}
}
Der Schlüssel für zuverlässige Funktion ist der Einsatz von deterministischem Code, um die strukturierten Ausgaben des Sprachmodells zu verarbeiten. Überprüfen Sie immer die API-Payloads vor der Ausführung, um Fehler zu vermeiden, und stellen Sie sicher, dass Ihr LLM konsistente JSON-Formate liefert, die zuverlässig geparst werden können.
Ihre Prompts sind die Schnittstelle zwischen Ihrer Anwendung und dem Sprachmodell – behandeln Sie sie als erstklassigen Code. Frameworks, die Prompts abstrahieren, wirken vielleicht bequem, verschleiern aber oft, wie Anweisungen an das LLM übergeben werden, was Feinabstimmungen erschwert oder unmöglich macht.
Stattdessen sollten Sie die Prompts explizit selbst schreiben:
function DetermineNextStep(thread: string) -> DoneForNow | ListGitTags | DeployBackend | DeployFrontend | RequestMoreInformation {
prompt #"
{{ _.role("system") }}
You are a helpful assistant that manages deployments for frontend and backend systems.
...
{{ _.role("user") }}
{{ thread }}
What should the next step be?
"#
}
Diese Vorgehensweise bietet Ihnen mehrere Vorteile:
Das Kontextfenster dient als Input für das LLM und umfasst Prompts, Gesprächshistorie und externe Daten. Die Optimierung dieses Fensters erhöht die Performance und Token-Effizienz.

Gehen Sie über Standard-Message-Formate hinaus und nutzen Sie eigene Strukturen, die die Informationsdichte maximieren:
<slack_message>
From: @alex
Channel: #deployments
Text: Can you deploy the backend?
</slack_message>
<list_git_tags>
intent: "list_git_tags"
</list_git_tags>
<list_git_tags_result>
tags:
- name: "v1.2.3"
commit: "abc123"
date: "2024-03-15T10:00:00Z"
</list_git_tags_result>
Das bringt mehrere Vorteile:
Im Kern sind Tools einfach JSON-Ausgaben des LLM, die in Ihrem Code deterministische Aktionen auslösen. Dadurch entsteht eine saubere Trennung zwischen AI-Entscheidung und Ausführung.
Definieren Sie Tool-Schemata klar:
class CreateIssue {
intent: "create_issue";
issue: {
title: string;
description: string;
team_id: string;
assignee_id: string;
};
}
class SearchIssues {
intent: "search_issues";
query: string;
what_youre_looking_for: string;
}
Bauen Sie anschließend zuverlässiges Parsen für LLM-JSON-Ausgaben, führen Sie die Aktionen deterministisch aus und geben Sie die Ergebnisse zur iterativen Verarbeitung in den Kontext zurück.
Viele Agenten-Frameworks trennen Ausführungsstatus (z.B. aktueller Schritt im Prozess) vom Geschäftsstatus (z.B. Historie der Tool-Aufrufe und deren Ergebnisse). Diese Trennung sorgt für unnötige Komplexität.
Speichern Sie stattdessen den gesamten Status direkt im Kontextfenster und leiten Sie den Ausführungsstatus aus der Ereignisabfolge ab:
<deploy_backend>
intent: "deploy_backend"
tag: "v1.2.3"
environment: "production"
</deploy_backend>
<error>
error running deploy_backend: Failed to connect to deployment service
</error>
Dieser einheitliche Ansatz bietet:
Starten Sie heute Ihre kostenlose Testversion und sehen Sie innerhalb weniger Tage Ergebnisse.
Produktionsreife Agenten müssen sich nahtlos in externe Systeme integrieren, bei langlaufenden Aufgaben pausieren und durch Webhooks oder andere Events fortgesetzt werden können.
Setzen Sie APIs um, die das Starten, Pausieren und Fortsetzen von Agenten ermöglichen und speichern Sie den Status robust zwischen den Vorgängen. So erreichen Sie:
AI-Agenten benötigen häufig menschlichen Input bei kritischen Entscheidungen oder Unklarheiten. Strukturierte Tool-Aufrufe machen diese Interaktion nahtlos:
class RequestHumanInput {
intent: "request_human_input";
question: string;
context: string;
options: {
urgency: "low" | "medium" | "high";
format: "free_text" | "yes_no" | "multiple_choice";
choices: string[];
};
}

Dieser Ansatz bietet eine klare Spezifikation von Interaktionstyp und Dringlichkeit, unterstützt Input mehrerer Nutzer und lässt sich gut mit APIs für dauerhafte Workflows kombinieren.
Eigene Ablaufsteuerung ermöglicht es, für menschliche Freigabe zu pausieren, Ergebnisse zu cachen oder Ratenbegrenzungen umzusetzen – und so das Verhalten des Agenten individuell anzupassen:
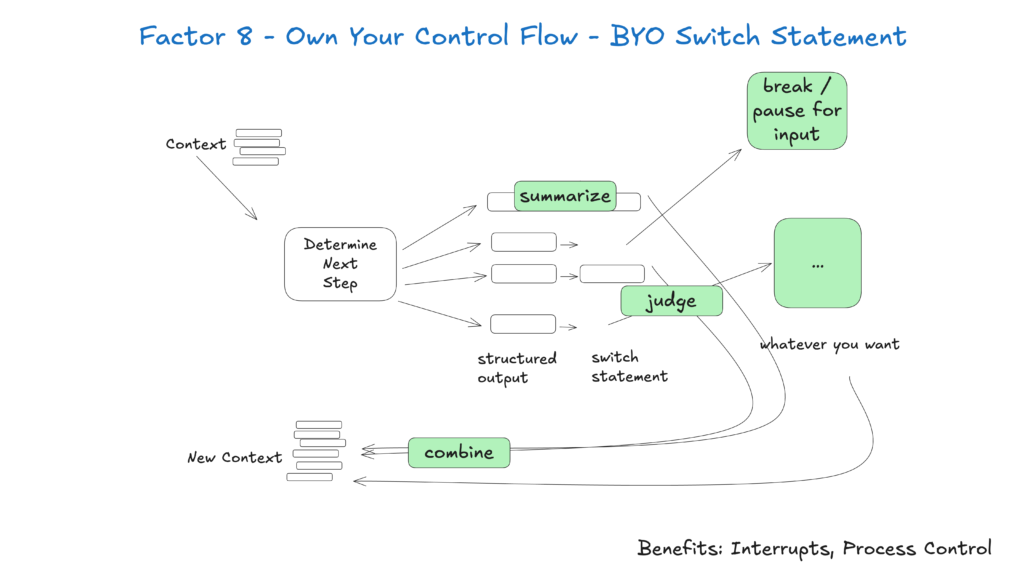
async function handleNextStep(thread: Thread) {
while (true) {
const nextStep = await determineNextStep(threadToPrompt(thread));
if (nextStep.intent === 'request_clarification') {
await sendMessageToHuman(nextStep);
await db.saveThread(thread);
break;
} else if (nextStep.intent === 'fetch_open_issues') {
const issues = await linearClient.issues();
thread.events.push({ type: 'fetch_open_issues_result', data: issues });
continue;
}
}
}
Damit profitieren Sie von:
Fehler direkt im Kontextfenster zu speichern, ermöglicht es AI-Agenten, aus Fehlern zu lernen und ihr Vorgehen anzupassen:
try {
const result = await handleNextStep(thread, nextStep);
thread.events.push({ type: `${nextStep.intent}_result`, data: result });
} catch (e) {
thread.events.push({ type: 'error', data: formatError(e) });
}
Damit das wirkungsvoll funktioniert:
Kleine Agenten, die 3–20 Schritte abdecken, behalten überschaubare Kontextfenster und erhöhen die LLM-Leistung und Zuverlässigkeit. Das sorgt für:
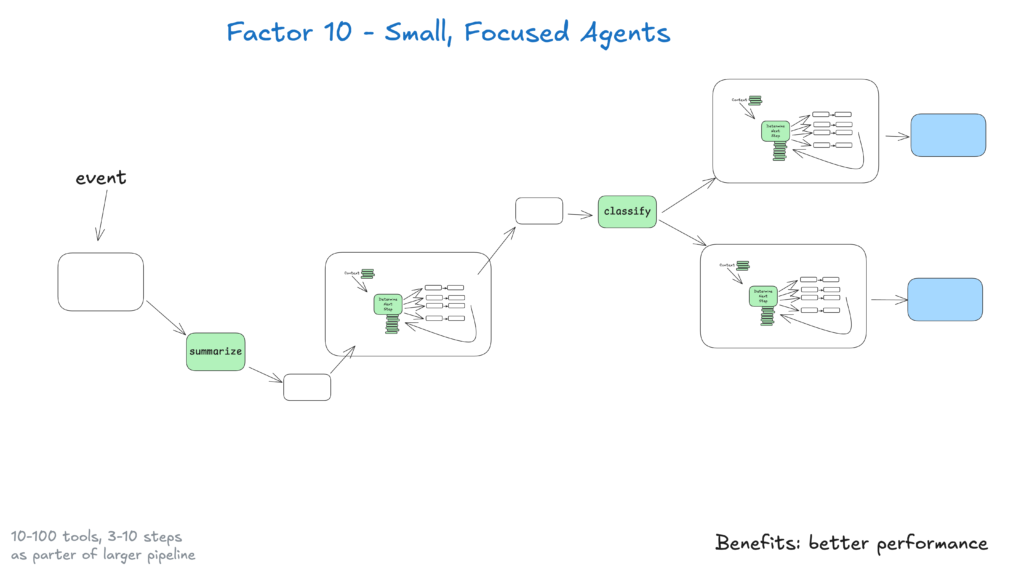
Mit zunehmender Leistungsfähigkeit von LLMs kann der Umfang dieser kleinen Agenten wachsen, während die Qualität erhalten bleibt – das sichert langfristige Skalierbarkeit.
Stellen Sie Ihre Agenten bereit, indem Sie Auslöser aus Slack, E-Mail oder Event-Systemen ermöglichen – und so Nutzer direkt dort abholen, wo sie arbeiten.
Implementieren Sie APIs, die Agenten aus verschiedenen Kanälen starten und im gleichen Medium antworten lassen. Das führt zu:
Behandeln Sie Agenten als zustandslose Funktionen, die Eingabekontext in Ausgaben umwandeln. Das vereinfacht das Zustandsmanagement und macht sie vorhersehbar und leichter zu debuggen.
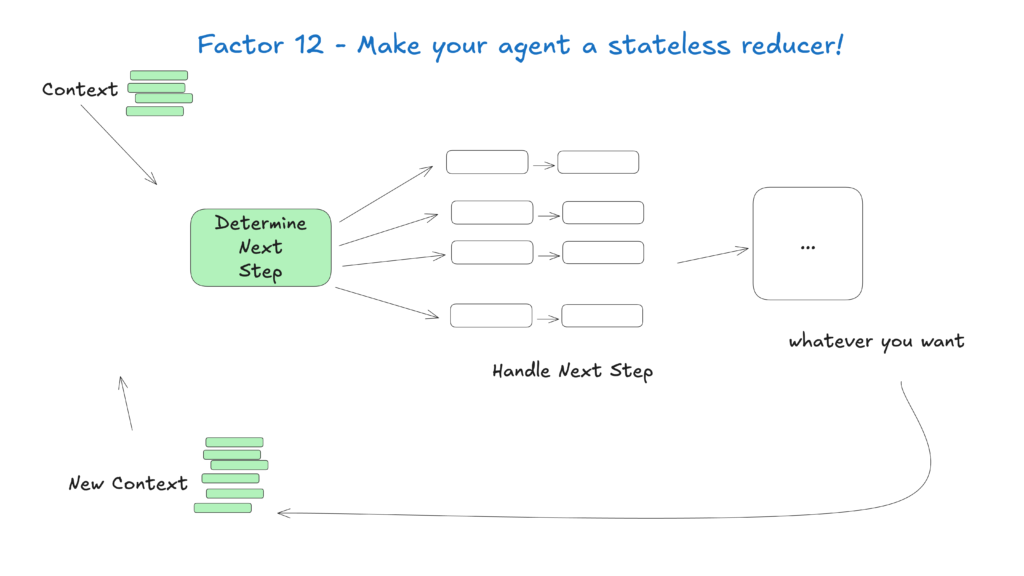
Dieses Konzept sieht Agenten als pure Funktionen ohne internen Zustand:
Erhalten Sie die neuesten Tipps, Trends und Angebote kostenlos.
Das Feld der AI-Agenten entwickelt sich rasant weiter, aber diese Kernprinzipien bleiben auch mit verbesserten Modellen relevant. Indem Sie mit kleinen, fokussierten Agenten starten, die diese Praktiken befolgen, schaffen Sie Systeme, die heute Wert liefern und sich an zukünftige Fortschritte anpassen.
Denken Sie daran: Die effektivsten AI-Agenten verbinden die Argumentationsfähigkeiten von Sprachmodellen mit der Zuverlässigkeit von deterministischem Code – und diese 12 Faktoren helfen, dieses Gleichgewicht herzustellen.
Bei FlowHunt haben wir diese Prinzipien umgesetzt und einen eigenen AI-Agenten entwickelt, der automatisch Workflow-Automatisierungen für unsere Kunden erstellt. So haben wir die 12-Faktoren-Methodik angewendet, um ein zuverlässiges, produktionsreifes System zu bauen
Die 12-Faktoren-AI-Agenten-Methodik ist ein Satz von Best Practices, inspiriert vom 12-Faktoren-App-Modell, der Entwicklern hilft, robuste, wartbare und skalierbare AI-Agenten zu bauen, die zuverlässig in realen Produktionsumgebungen arbeiten.
Kontextmanagement stellt sicher, dass AI-Agenten relevante Gesprächshistorien, Prompts und Zustände behalten, um die Leistung zu optimieren, den Tokenverbrauch zu reduzieren und die Entscheidungsgenauigkeit zu verbessern.
FlowHunt AI-Agenten strukturieren Tool-Aufrufe so, dass bei Bedarf menschlicher Input angefordert wird. So ermöglichen sie nahtlose Zusammenarbeit, Freigaben und dauerhafte Workflows für komplexe oder kritische Szenarien.
Stateless AI-Agenten sind vorhersehbar, leichter zu debuggen und einfacher zu skalieren, weil sie den Eingabekontext in Ausgaben umwandeln, ohne versteckten internen Zustand zu behalten.
Arshia ist eine AI Workflow Engineerin bei FlowHunt. Mit einem Hintergrund in Informatik und einer Leidenschaft für KI spezialisiert sie sich darauf, effiziente Arbeitsabläufe zu entwickeln, die KI-Tools in alltägliche Aufgaben integrieren und so Produktivität und Kreativität steigern.

Bereit, robuste, produktionsreife AI-Agenten zu entwickeln? Entdecken Sie die Tools von FlowHunt und erfahren Sie, wie die 12-Faktoren-Methodik Ihre Automatisierung transformieren kann.
Ein intelligenter Agent ist eine autonome Entität, die darauf ausgelegt ist, ihre Umgebung mittels Sensoren wahrzunehmen und über Aktuatoren auf diese Umgebung ...

Erkunden Sie die Welt der KI-Agentenmodelle mit einer umfassenden Analyse von 20 fortschrittlichen Systemen. Erfahren Sie, wie sie denken, schlussfolgern und be...

Erfahren Sie, wie die Integration und Governance unstrukturierter Daten Unternehmensdaten in KI-bereite Datensätze verwandelt und so präzise RAG-Systeme und int...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.