Wan 2.1: Die Open-Source-Revolution der KI-Video-Generierung
Wan 2.1 ist ein leistungsstarkes Open-Source-KI-Video-Generierungsmodell von Alibaba, das Studioqualität aus Text oder Bildern liefert und von jedem lokal genutzt werden kann.
AI Video Generation
Open Source
Wan 2.1
Alibaba
Generative AI
Video AI
AI Tools
Wan 2.1 (auch WanX 2.1 genannt) setzt neue Maßstäbe als vollständig Open-Source-KI-Video-Generierungsmodell, entwickelt vom Tongyi Lab von Alibaba. Im Gegensatz zu vielen proprietären Video-Generierungs-Systemen, die teure Abonnements oder API-Zugänge erfordern, liefert Wan 2.1 vergleichbare oder sogar bessere Qualität und bleibt dabei komplett kostenlos und zugänglich für Entwickler, Forscher und Kreativprofis.
Was Wan 2.1 wirklich besonders macht, ist die Kombination aus Zugänglichkeit und Leistung. Die kleinere T2V-1.3B-Variante benötigt nur etwa 8,2 GB GPU-Speicher und ist so mit den meisten modernen Consumer-GPUs kompatibel. Gleichzeitig liefert die größere Version mit 14 Milliarden Parametern eine Spitzenleistung, die sowohl Open-Source-Alternativen als auch viele kommerzielle Modelle in Standard-Benchmarks übertrifft.
Schlüsselfunktionen, die Wan 2.1 auszeichnen
Multi-Task-Unterstützung
Wan 2.1 ist nicht nur auf die Text-zu-Video-Generierung beschränkt. Seine vielseitige Architektur unterstützt:
Text-zu-Video (T2V)
Bild-zu-Video (I2V)
Video-zu-Video-Bearbeitung
Text-zu-Bild-Generierung
Video-zu-Audio-Generierung
Diese Flexibilität bedeutet, dass Sie mit einem Text-Input, einem Standbild oder sogar einem vorhandenen Video beginnen und es nach Ihrer kreativen Vision umwandeln können.
Mehrsprachige Textgenerierung
Als erstes Videomodell, das lesbaren englischen und chinesischen Text in generierten Videos darstellen kann, eröffnet Wan 2.1 neue Möglichkeiten für internationale Content Creator. Besonders wertvoll ist diese Funktion für die Erstellung von Untertiteln oder Szene-Texten in mehrsprachigen Videos.
Revolutionäres Video-VAE (Wan-VAE)
Im Herzen von Wan 2.1s Effizienz steckt sein 3D kausaler Video-Variational-Autoencoder. Dieser technologische Durchbruch komprimiert räumlich-zeitliche Informationen äußerst effizient und ermöglicht es dem Modell:
Videos um ein Vielfaches zu komprimieren
Bewegung und Detailtreue zu bewahren
Hochauflösende Ausgaben bis zu 1080p zu unterstützen
Außergewöhnliche Effizienz und Zugänglichkeit
Das kleinere 1.3B-Modell benötigt nur 8,19 GB VRAM und kann ein 5-sekündiges, 480p-Video in etwa 4 Minuten auf einer RTX 4090 erzeugen. Trotz dieser Effizienz erreicht seine Qualität das Niveau deutlich größerer Modelle oder übertrifft diese sogar – die perfekte Balance aus Geschwindigkeit und visueller Brillanz.
Branchenführende Benchmarks & Qualität
In öffentlichen Evaluierungen erzielte Wan 14B die höchste Gesamtpunktzahl in den Wan-Bench-Tests und übertraf die Konkurrenz in:
Bewegungsqualität
Stabilität
Genauigkeit der Prompt-Umsetzung
Bereit, Ihr Geschäft zu erweitern?
Starten Sie heute Ihre kostenlose Testversion und sehen Sie innerhalb weniger Tage Ergebnisse.
Wie sich Wan 2.1 von anderen Video-Generierungsmodellen abhebt
Im Gegensatz zu Closed-Source-Systemen wie OpenAIs Sora oder Runways Gen-2 ist Wan 2.1 frei verfügbar und kann lokal ausgeführt werden. Es übertrifft im Allgemeinen frühere Open-Source-Modelle (wie CogVideo, MAKE-A-VIDEO und Pika) und sogar viele kommerzielle Lösungen in Qualitätsbenchmarks.
Eine aktuelle Branchenumfrage stellte fest, dass „unter vielen KI-Videomodellen Wan 2.1 und Sora hervorstechen“ – Wan 2.1 durch seine Offenheit und Effizienz, Sora durch seine proprietäre Innovation. In Community-Tests wurde berichtet, dass die Bild-zu-Video-Fähigkeit von Wan 2.1 Konkurrenten in Klarheit und filmischem Charakter übertrifft.
Die Technologie hinter Wan 2.1
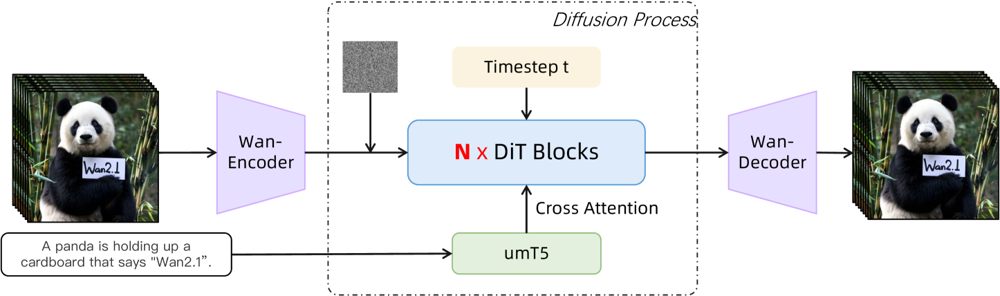
Wan 2.1 basiert auf einem Diffusions-Transformer-Backbone mit einem neuartigen räumlich-zeitlichen VAE. So funktioniert es:
Ein Input (Text und/oder Bild/Video) wird vom Wan-VAE in eine latente Videorepräsentation kodiert
Ein Diffusions-Transformer (basierend auf der DiT-Architektur) entrauscht diese Latente schrittweise
Der Prozess wird vom Text-Encoder (eine mehrsprachige T5-Variante namens umT5) gesteuert
Abschließend rekonstruiert der Wan-VAE-Decoder die Video-Frames
Abbildung: Die High-Level-Architektur von Wan 2.1 (Text-zu-Video-Fall). Ein Video (oder Bild) wird zunächst vom Wan-VAE Encoder in eine latente Darstellung kodiert. Diese Latente wird dann durch N Diffusions-Transformer-Blöcke geleitet, die per Cross-Attention auf das Text-Embedding (von umT5) zugreifen. Schließlich rekonstruiert der Wan-VAE Decoder die Video-Frames. Dieses Design – mit einem „3D kausalen VAE Encoder/Decoder um einen Diffusions-Transformer“ (ar5iv.org
) – ermöglicht eine effiziente Komprimierung räumlich-zeitlicher Daten und unterstützt hochwertige Videoausgaben.
Diese innovative Architektur – ein „3D kausaler VAE Encoder/Decoder um einen Diffusions-Transformer“ – erlaubt eine effiziente Komprimierung räumlich-zeitlicher Daten und hochqualitative Videoausgaben.
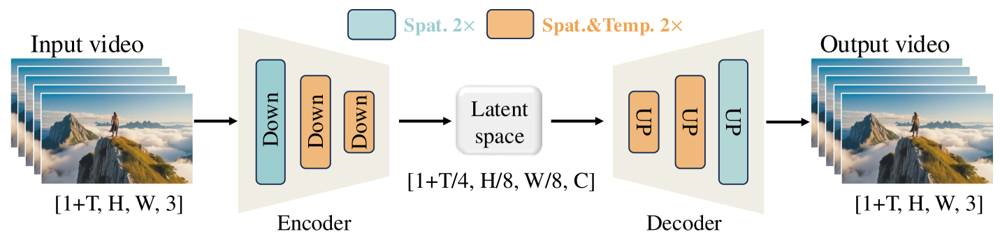
Der Wan-VAE ist speziell für Videos konzipiert. Er komprimiert den Input um beeindruckende Faktoren (zeitlich 4× und räumlich 8×) in eine kompakte Latente, bevor das Video wieder in voller Auflösung rekonstruiert wird. Der Einsatz von 3D-Convolutions und kausalen (zeitbewahrenden) Layern sorgt dabei für kohärente Bewegungen im gesamten generierten Inhalt.
Abbildung: Das Wan-VAE-Framework von Wan 2.1 (Encoder-Decoder). Der Wan-VAE-Encoder (links) verwendet eine Reihe von Downsampling-Schichten („Down“) auf das Eingabevideo (Form [1+T, H, W, 3] Frames), bis eine kompakte Latente ([1+T/4, H/8, W/8, C]) erreicht ist. Der Wan-VAE-Decoder (rechts) upsamplet („UP“) diese Latente symmetrisch zurück zu den Original-Video-Frames. Blaue Blöcke stehen für räumliche Kompression, orange Blöcke für kombinierte räumliche+zeitliche Kompression (ar5iv.org
). Durch eine Komprimierung des Videos um den Faktor 256 (im räumlich-zeitlichen Volumen) macht Wan-VAE hochauflösendes Video-Modeling für das nachfolgende Diffusionsmodell möglich.
Abonnieren Sie unseren Newsletter
Erhalten Sie die neuesten Tipps, Trends und Angebote kostenlos.
Wie Sie Wan 2.1 auf Ihrem eigenen Rechner ausführen
Bereit, Wan 2.1 selbst auszuprobieren? So legen Sie los:
Systemvoraussetzungen
Python 3.8+
PyTorch ≥2.4.0 mit CUDA-Unterstützung
NVIDIA-GPU (8GB+ VRAM für das 1.3B-Modell, 16-24GB für die 14B-Modelle)
Zusätzliche Bibliotheken aus dem Repository
Installationsschritte
Repository klonen und Abhängigkeiten installieren:
git clone https://github.com/Wan-Video/Wan2.1.git
cd Wan2.1
pip install -r requirements.txt
python generate.py --task t2v-14B --size 1280*720 \
--ckpt_dir ./Wan2.1-T2V-14B \
--prompt "A futuristic city skyline at sunset, with flying cars zooming overhead."
Performance-Tipps
Bei begrenztem GPU-Speicher das leichtere t2v-1.3B-Modell nutzen
Mit den Flags --offload_model True --t5_cpu Teile des Modells auf die CPU auslagern
Seitenverhältnis über den Parameter --size steuern (z. B. 832*480 für 16:9 480p)
Wan 2.1 bietet Prompt-Erweiterung und „Inspiration Mode“ über zusätzliche Optionen
Zur Orientierung: Eine RTX 4090 generiert ein 5-sekündiges 480p-Video in etwa 4 Minuten. Multi-GPU-Setups sowie verschiedene Performance-Optimierungen (FSDP, Quantisierung usw.) werden für den großflächigen Einsatz unterstützt.
Warum Wan 2.1 für die Zukunft der KI-Video-Entwicklung wichtig ist
Als Open-Source-Kraftpaket, das die Giganten der KI-Video-Generierung herausfordert, markiert Wan 2.1 einen bedeutenden Wandel in der Zugänglichkeit. Sein freier und offener Charakter ermöglicht es jedem mit einer ordentlichen GPU, modernste Video-Generierung ohne Abogebühren oder API-Kosten zu erkunden.
Für Entwickler erlaubt die Open-Source-Lizenz individuelle Anpassungen und Verbesserungen des Modells. Forscher können seine Fähigkeiten erweitern, während Kreative Videocontent schnell und effizient prototypen.
In einer Zeit, in der proprietäre KI-Modelle zunehmend hinter Bezahlschranken verschwinden, zeigt Wan 2.1, dass Spitzenleistung demokratisiert und mit der breiten Community geteilt werden kann.
Häufig gestellte Fragen
Was ist Wan 2.1?
Wan 2.1 ist ein vollständig Open-Source-KI-Video-Generierungsmodell, entwickelt vom Tongyi Lab von Alibaba, das hochwertige Videos aus Texteingaben, Bildern oder vorhandenen Videos erstellen kann. Es ist kostenlos nutzbar, unterstützt mehrere Aufgaben und läuft effizient auf Consumer-GPUs.
Welche Funktionen machen Wan 2.1 besonders?
Wan 2.1 unterstützt Multi-Task-Video-Generierung (Text-zu-Video, Bild-zu-Video, Video-Editing usw.), mehrsprachige Texteinblendungen in Videos, hohe Effizienz durch sein 3D kausales Video-VAE und übertrifft viele kommerzielle und Open-Source-Modelle in Benchmarks.
Wie kann ich Wan 2.1 auf meinem eigenen Rechner ausführen?
Sie benötigen Python 3.8+, PyTorch 2.4.0+ mit CUDA sowie eine NVIDIA-GPU (8GB+ VRAM für das kleinere Modell, 16-24GB für das große Modell). Klonen Sie das GitHub-Repository, installieren Sie die Abhängigkeiten, laden Sie die Modellgewichte herunter und nutzen Sie die bereitgestellten Skripte, um Videos lokal zu generieren.
Warum ist Wan 2.1 wichtig für die KI-Video-Generierung?
Wan 2.1 demokratisiert den Zugang zu modernster Video-Generierung durch Open-Source und kostenlose Nutzung, sodass Entwickler, Forscher und Kreative ohne Bezahlschranken oder proprietäre Einschränkungen experimentieren und innovieren können.
Wie schneidet Wan 2.1 im Vergleich zu Modellen wie Sora oder Runway Gen-2 ab?
Im Gegensatz zu Closed-Source-Alternativen wie Sora oder Runway Gen-2 ist Wan 2.1 vollständig Open-Source und kann lokal ausgeführt werden. Es übertrifft in der Regel frühere Open-Source-Modelle und erreicht oder übertrifft viele kommerzielle Lösungen in Qualitätsbenchmarks.
Arshia ist eine AI Workflow Engineerin bei FlowHunt. Mit einem Hintergrund in Informatik und einer Leidenschaft für KI spezialisiert sie sich darauf, effiziente Arbeitsabläufe zu entwickeln, die KI-Tools in alltägliche Aufgaben integrieren und so Produktivität und Kreativität steigern.
Arshia Kahani
AI Workflow Engineerin
Teste FlowHunt und entwickle KI-Lösungen
Beginnen Sie mit dem Aufbau eigener KI-Tools und Video-Generierungs-Workflows mit FlowHunt oder vereinbaren Sie eine Demo, um die Plattform in Aktion zu sehen.
Wie transformiert man die Content-Erstellung mit Wan 2.2 & 2.5 Video-Generierung?
FlowHunt unterstützt jetzt die Video-Generierungsmodelle Wan 2.2 und 2.5 für Text-zu-Video, Bild-zu-Video, Persona-Austausch und Animation. Transformieren Sie I...
Oktober 2025 Update: Leistungsstarke neue Video- & Bild-AI-Modelle
Das FlowHunt-Update für Oktober 2025 bringt revolutionäre Wan 2.2- und 2.5-Videogenerierungsmodelle für Text-zu-Video, Bild-zu-Video und Animation sowie Qwens f...
KI-Gesichtsersetzung und Animation meistern mit WAN 2.2 Animate Replace in FlowHunt Photomatic
Erfahren Sie, wie Sie mit WAN 2.2 Animate Replace professionelle, KI-animierte Face-Swap-Videos erstellen. Entdecken Sie den vollständigen Workflow, fortgeschri...
16 Min. Lesezeit
AI Video
Animation
+4
Cookie-Zustimmung Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.