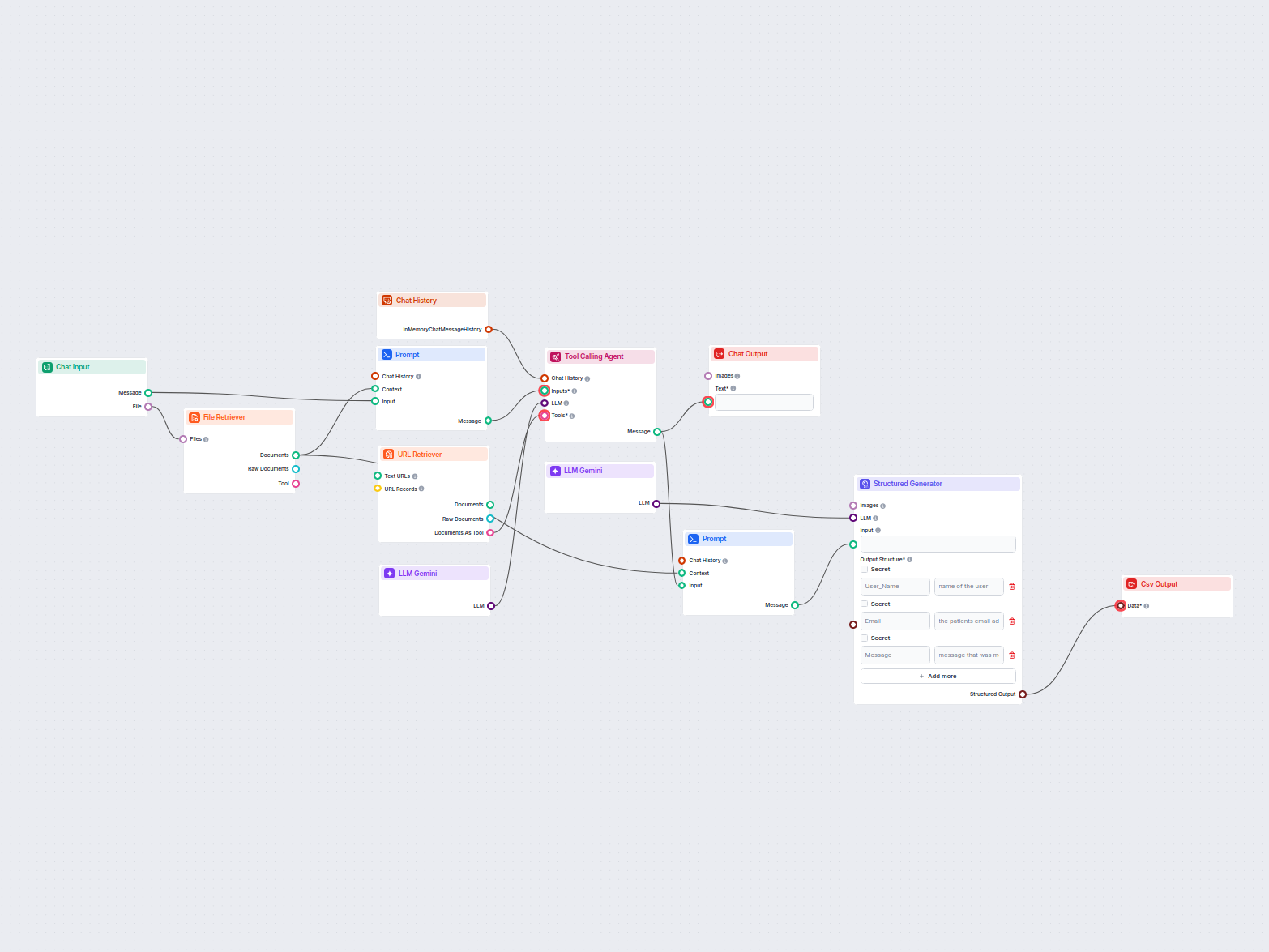
E-Mail- & Dateiextraktion zu CSV
Dieser Workflow extrahiert und organisiert Schlüsselinformationen aus E-Mails und angehängten Dateien, nutzt KI zur Verarbeitung und Strukturierung der Daten un...
4 Min. Lesezeit
Um Ihnen den schnellen Einstieg zu erleichtern, haben wir mehrere Beispiel-Flow-Vorlagen vorbereitet, die zeigen, wie die Urlcontent-Komponente effektiv genutzt wird. Diese Vorlagen präsentieren verschiedene Anwendungsfälle und Best Practices und erleichtern Ihnen das Verständnis und die Implementierung der Komponente in Ihren eigenen Projekten.
Dieser Workflow extrahiert und organisiert Schlüsselinformationen aus E-Mails und angehängten Dateien, nutzt KI zur Verarbeitung und Strukturierung der Daten un...
Wir helfen Unternehmen wie Ihrem, intelligente Chatbots, MCP-Server, KI-Tools oder andere Arten von KI-Automatisierungen zu entwickeln, um Menschen bei sich wiederholenden Aufgaben in Ihrer Organisation zu ersetzen.