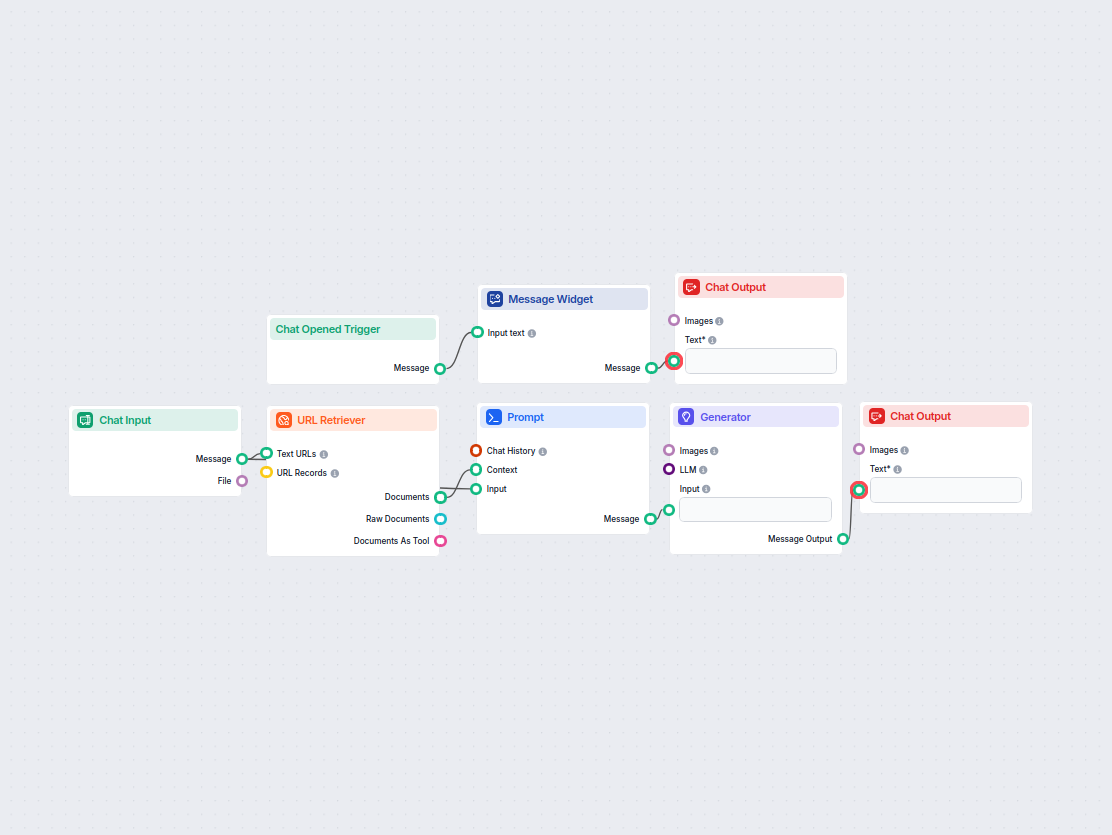
Verwandle jede URL in einen ansprechenden X-Post
Verwandelt den Inhalt jeder angegebenen URL automatisch in einen prägnanten, ansprechenden Beitrag, der für X (Twitter) geeignet ist, und hilft Vermarktern und ...
2 Min. Lesezeit
Mit dem URL-Retriever können Sie Inhalte von Weblinks abrufen und verarbeiten – unterstützt OCR, Metadatenextraktion und flexiblen Output zur Ansteuerung von KI-Workflows.
Komponentenbeschreibung
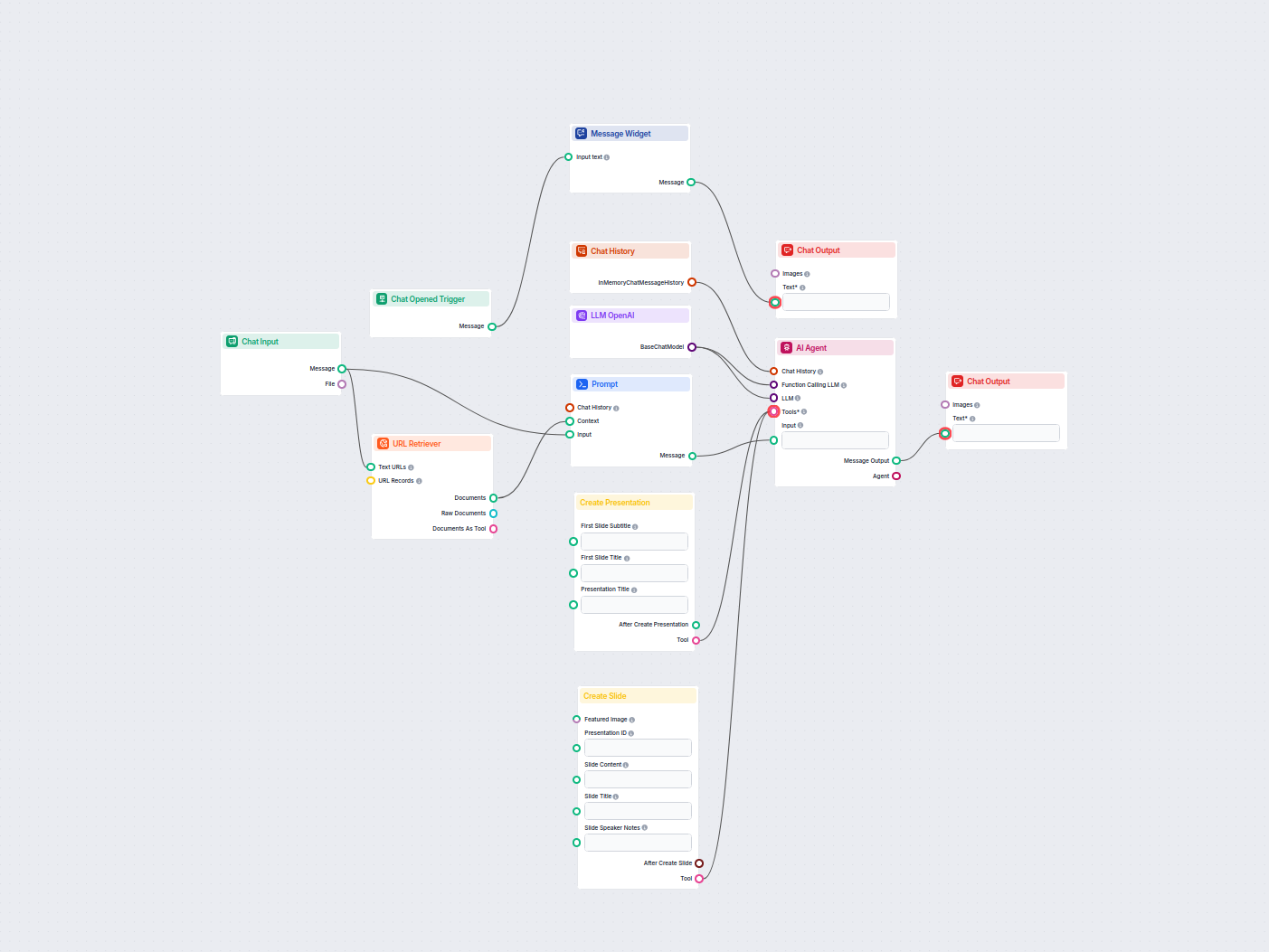
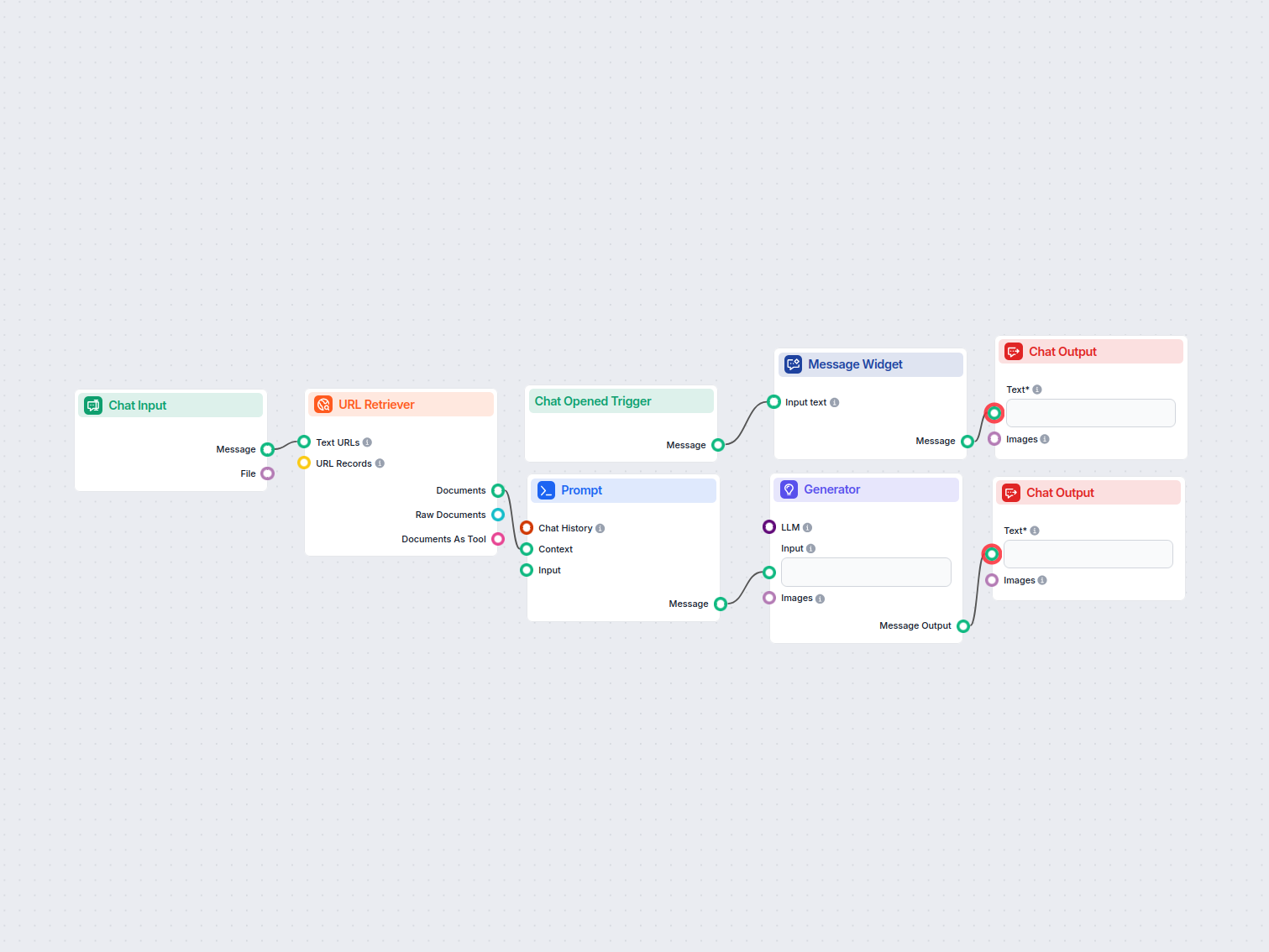
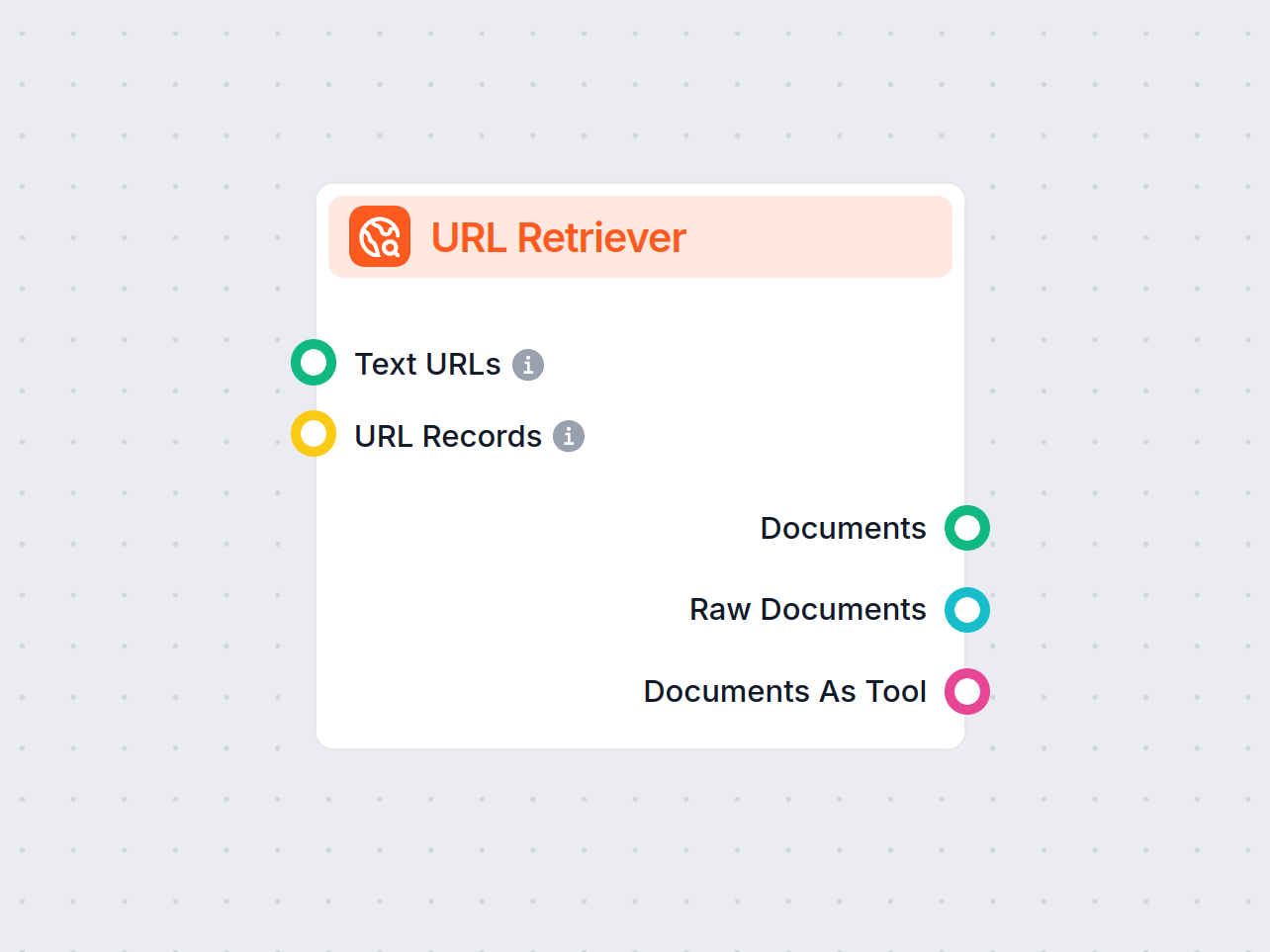
The URL Retriever is a versatile flow component designed to fetch and process web content from specified URLs, returning the information as structured documents. It serves as a bridge between external online content and your AI workflow, enabling you to integrate, analyze, or process web-based information efficiently.
This component retrieves the content of one or multiple URLs provided as input. It can extract the main text, metadata, and even process content from images using Optical Character Recognition (OCR). The retrieved data is then made available in various structured formats suitable for downstream AI tasks such as summarization, question answering, or knowledge extraction.
You can supply URLs to the component in two ways:
Text URLs:
MessageURL Records:
UrlRecord| Parameter | Type | Default | Description |
|---|---|---|---|
| Apply OCR | Boolean | false | If enabled, applies OCR to extract text from images in the document. |
| Cache TTL | Dropdown | 2 weeks | How long the content should be cached, with options from no cache up to 1 year. |
| From H1 if exists | Boolean | true | Begins extraction from the H1 tag if present, focusing on main content. |
| Load from pointer | Boolean | true | Loads content starting from the most relevant section based on your query. |
| Hide Resources | Boolean | false | Hides the retrieved resources from being output or displayed. |
| Max Tokens | Integer | 3000 | Sets the maximum number of tokens for the output text. |
| Skip Last Header | Boolean | true | Skips the last header during extraction for streamlined content. |
| Strategy | Dropdown | Include equal size from each documents | Determines how content is combined: concatenate fully or include equal parts from each document. |
| Export Content | Multi-select | All | Choose which HTML elements to export (H1-H6, Paragraph). |
| Include Metadata | Multi-select | Product | Specify which metadata fields to include (e.g., Product, Author, Website, etc.). |
| Verbose | Boolean | false | Enables detailed output for debugging or information purposes. |
| Tool Name | String | (empty) | Optionally assign a custom name to the tool for agent reference. |
| Tool Description | Multiline | (empty) | Provide a description to help agents understand the tool’s purpose. |
The URL Retriever provides its outputs in several formats, allowing flexible integration with various AI processes:
| Output Name | Type | Description |
|---|---|---|
| Documents | Message | The processed content from the URLs, ready for use in messaging-oriented workflows. |
| Raw Documents | Document | The raw, unprocessed document objects for advanced downstream processing. |
| Documents As Tool | Tool | The content packaged as a tool, enabling agent-based workflows to utilize the documents. |
| Feature | Description |
|---|---|
| Fetches URLs | Retrieves and processes web content from provided URLs. |
| OCR Support | Extracts text from images in documents if enabled. |
| Metadata Extraction | Optionally includes metadata such as author, product, or schema.org types. |
| Customizable Output | Select which HTML elements or metadata to export. |
| Caching | Configurable cache lifetimes for efficiency. |
| Multiple Output Types | Supports message, raw document, and tool outputs for workflow flexibility. |
The URL Retriever is a powerful and flexible bridge between web content and your AI workflows, offering granular control over content extraction and integration.
Um Ihnen den schnellen Einstieg zu erleichtern, haben wir mehrere Beispiel-Flow-Vorlagen vorbereitet, die zeigen, wie die URL-Retriever-Komponente effektiv genutzt wird. Diese Vorlagen präsentieren verschiedene Anwendungsfälle und Best Practices und erleichtern Ihnen das Verständnis und die Implementierung der Komponente in Ihren eigenen Projekten.
Verwandelt den Inhalt jeder angegebenen URL automatisch in einen prägnanten, ansprechenden Beitrag, der für X (Twitter) geeignet ist, und hilft Vermarktern und ...
Erzeugen Sie Transkripte aus Videos, indem Sie Untertitel von bereitgestellten URLs extrahieren. Nützlich, um schnell lesbaren Text aus Online-Videos mit nicht ...
Erstellen Sie mithilfe von KI prägnante Fazits aus Websites, hochgeladenen Dokumenten oder YouTube-Videos. Perfekt, um schnell die wichtigsten Erkenntnisse zusa...
Analysieren Sie die Lesbarkeit jeder beliebigen Website, indem Sie deren URL eingeben. Dieser Workflow ruft den Inhalt von der angegebenen URL ab und bewertet d...
Interagieren Sie mit jedem YouTube-Video, indem Sie mit dessen Transkript chatten. Extrahieren und durchsuchen Sie Videoinhalte sofort, um prägnante, KI-gestütz...
Erzeugen Sie automatisch SEO-optimierte YouTube-Videotitel, Beschreibungen und Hashtags aus jeder Webseiten-URL. Perfekt für Marketer, Content-Ersteller und Unt...
Verwandeln Sie jedes YouTube-Video in wenigen Minuten in eine professionelle Google Slides Präsentation. Dieser KI-gestützte Workflow extrahiert Inhalte aus ein...
Automatisches Generieren von hochrangigen SEO-Blogartikeln aus YouTube-Videos. Dieser Workflow extrahiert Videotranskripte, analysiert Top-SEO-Keywords, erstell...
Anzeige 61 bis 68 von 68 Ergebnissen
Der URL-Retriever ruft Inhalte von angegebenen Weblinks ab und verarbeitet sie, sodass Text und Metadaten aus Online-Dokumenten für Ihren Workflow oder KI-Agenten verfügbar werden.
Ja, wenn die OCR-Option aktiviert ist, kann die Komponente Text aus bildbasierten Dokumenten oder gescannten PDFs extrahieren.
Sie gibt verarbeitete Dokumente als Textnachrichten, rohe Dokumentenobjekte oder als Tool für Agenten-Workflows aus – je nach Setup.
Sie können festlegen, wie lange abgerufene Inhalte zwischengespeichert werden, um wiederholte Downloads zu vermeiden und Ihre Flows zu beschleunigen.
Ja, Sie können festlegen, welche Überschriften, Absätze oder Metadatenfelder in die Ausgabe aufgenommen werden sollen, um gezielt zu extrahieren.
Absolut. Der URL-Retriever ist essenziell für jede Automatisierung oder jeden Chatbot, der Live-Webinhalte lesen, verarbeiten oder zusammenfassen muss.
Steigern Sie Ihre Workflows, indem Sie Live-Webinhalte integrieren. Extrahieren, verarbeiten und nutzen Sie Daten aus URLs ganz einfach.
Integrieren Sie Ihre Workflows mit Google Docs mithilfe der Google Docs Retriever-Komponente – holen Sie nahtlos Dokumenteninhalte zur Nutzung in Automatisierun...
Die Datei-Retriever-Komponente in FlowHunt ermöglicht es Ihnen, Dateien in Ihren Workflow einzubringen und in Dokumente für die weitere Verarbeitung umzuwandeln...
Erfassen Sie Website-Screenshots sofort mit der Screenshot-Tool-Komponente. Automatisieren Sie ganz einfach das Aufnehmen von Screenshots jeder URL innerhalb Ih...